This specification defines an XML syntax for the
Resource Description Framework (RDF) as amended and clarified by the
RDF Core Working Group
from that originally described in
RDF Model & Syntax.
The syntax is updated to be specified in terms of
XML,
XML Namespaces,
the
XML Information Set
with new support for
XML Base.
For each part of the RDF/XML syntax,
it gives an example of how it works and in grammar
defines actions for generating the triples that form the
RDF graph
as defined in the
RDF Concepts and Abstract Data Model Working Draft.
This is done using the
N-Triples
graph serializing test format which enables more precise recording of
the mapping in a machine processable and testable form. These tests
are gathered and published in the
RDF Test Cases
Working Draft.
This is the editors version of a W3C
RDF Core Working Group
Working Draft produced as part of the W3C
Semantic Web Activity
(Activity Statement).
It incorporates decisions made by the Working Group
updating the XML syntax for RDF from the original
RDF Model & Syntax [RDF-MS] document
in terms of the
XML Information Set
[INFOSET].
including new support for
XML Base,
RDF datatyping,
rdf:nodeID for referencing blank nodes and
rdf:parseType="Collection" for
expressing a closed collection of nodes.
This document is being released for review by W3C Members and
other interested parties to encourage feedback and comments,
especially with regard to how the changes affect existing
implementations and content. The current state is that it represents
all the syntax as described in the
grammar section
of the original document, with some removed parts
(see rdfms-abouteach),
and the mapping to the RDF graph is considered complete.
The detailed changes from the previous
25 March 2002 draft
are described in the Changes section
however the main changes are as follows:
Section 2 An XML syntax for RDF expanded
with many more examples covering all of the syntax,
support for RDF datatyped literals using rdf:datatype was added,
rdf:nodeID was added to allow referencing of blank nodes,
rdf:parseType="Collection" was added for creating
closed collections of nodes
and many other more minor changes after RDF Core Working Group
decisions
made since the last draft.
This is a public W3C Working Draft and may be updated, replaced, or
obsoleted by other documents at any time. It is inappropriate to use
W3C Working Drafts as reference material or to cite as other than
"work in progress". A list of current W3C Recommendations and other
technical documents can be found at http://www.w3.org/TR/.
There are no known patent or
IPR
constraints associated with this Working Draft. The
RDF Core Working Group Patent Disclosure
page contains details, in conformance with
W3C policy
requirements.
Comments on this document are invited and should be sent to the
public mailing list
www-rdf-comments@w3.org.
An archive of comments is available at
http://lists.w3.org/Archives/Public/www-rdf-comments/.
This document describes the
XML
[XML]
syntax for RDF as
originally defined in the
RDF Model & Syntax [RDF-MS] W3C
Recommendation. Subsequent implementations of this syntax and
comparison of the resulting RDF graphs have shown that there was
ambiguity - implementations generated different graphs and certain
syntax forms were not widely implemented. These issues were
generally made as either feedback to the
www-rdf-comments@w3.org
(archive)
or from discussions on the RDF Interest Group list
www-rdf-interest@w3.org
(archive)
.
The
RDF Core Working Group
is chartered
to respond to the need for a number of fixes, clarifications and
improvements to the specification of RDF's abstract graph and XML
syntax. The Working Group invites feedback from the developer
community on the effects of its proposals on existing implementations
and documents.
Several decisions including amendments and deletions to the
grammar are referred to
below.
The definitive record of the decisions is the
RDF Core Working Group issues list.
This document revises the
original RDF/XML grammar
in terms of
XML Information Set
[INFOSET] Information Items which moves
away from the rather low-level details of XML, such as particular
forms of empty elements. This allows the grammar to be more
precisely recorded and the mapping from the XML syntax to the RDF
graph more clearly shown. The mapping to the RDF graph is done by
emitting statements in the form defined in the
N-Triples
section of
RDF Test Cases [RDF-TESTS] Working Draft
which creates an RDF graph, that has semantics defined by
RDF Model Theory [RDF-MODEL] Working Draft.
The complete specification of RDF consists of a number of documents:
The
RDF Concepts and Abstract Data Model [RDF-CONCEPTS]
defines the
RDF Graph data model (Section 2.4.1)
and the
RDF Graph syntax (Section 3).
Along with the
RDF Model Theory [RDF-MODEL] this provides an
abstract syntax with a formal semantics for it.
This graph has nodes and labelled directed arcs.
The nodes
can be labeled with URIs, literals or are blank and denote resources.
The arcs connect the nodes and are all
labeled with URIs. This graph is more precisely called a directed
edge-labeled graph; each edge is an arc with a direction (an arrow)
connecting two nodes. These edges can be described as triples of
subject node, at the blunt end of the arrow,
property arc and an object node at the sharp end of
the arrow/arc. The property arc can also be also interpreted as
either a relationship between two resources or as defining
an attribute value (object node) for some resource subject node.
In order to encode the graph in XML, the nodes and arcs have to be
represented by XML element names, attribute names, element content
and attribute content.
The URI labels for properties and object nodes are written in XML via
XML Namespaces [XML-NS]
which allows a namespace URI to be given a short prefix that
is used to namespace-qualify elements and attributes names with
local names. RDF/XML uses (namespace URI, local name) pairs
such that concatenating them forms the original URI that is required.
This shortens the URIs used for property names. URIs labeling
subject and object nodes are stored as XML attribute values.
Nodes labeled by string literals (which are always object nodes)
become element text content or attribute values.
A graph can be considered a sequence of paths of the form Node,
Arc, Node, Arc, Node, Arc, ... which walk the entire graph. In
RDF/XML these turn into sequences of elements inside elements which
alternate between elements for Nodes and Arcs. This has been called
a series of Node/Arc stripes. The Node at the start of the sequence
turns into the outermost element, the next arc turns into a child
element, and so on. The stripes generally start at the top of an
RDF/XML document and always begin with nodes.
The sentence
There is a resource (this one) with a title, "RDF/XML Syntax Specification
(Revised)" and it has an editor, the editor has a name
"Dave Beckett" and a home page http://purl.org/net/dajobe/.
can be written as the RDF graph in Figure 1
where the nodes are represented as ovals and contain
their URI where they have them,
the properties such as "has an editor" have been given URIs
and these have been used to label the appropriate arc,
and the strings have been written in rectangular nodes.
If we follow the Node, Arc ... path through the graph shown in
Figure 2:
This corresponds to the Node/Arc stripes:
- Node
[http://www.w3.org/TR/rdf-syntax-grammar]
- Arc
-[http://example.org/stuff/1.0/editor]->
- Node
[]
- Arc
-[http://example.org/stuff/1.0/homePage]->
- Node
[http://purl.org/net/dajobe/]
In RDF/XML the sequence of 5 nodes and arcs for the
arcs in Figure 2 corresponds to 5
XML elements shown in Example 1:
<rdf:Description>
<ex:editor>
<rdf:Description>
<ex:homePage>
<rdf:Description>
</rdf:Description>
</ex:homePage>
</rdf:Description>
</ex:editor>
</rdf:Description>
There are two types of XML elements in the striping in Example 1 corresponding to the nodes and arcs in
the graph which are conventionally called Node Elements and
Property Elements respectively. Here,
rdf:Description is the node element (used 3 times for
the three nodes) and ex:editor and
ex:homePage are the 2 property elements.
The Figure 2 graph consists of some nodes
labelled with URIs (others that remain blank) and this can be added
to the RDF/XML using the rdf:about attribute on node
elements to give the result in Example 2:
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<ex:editor>
<rdf:Description>
<ex:homePage>
<rdf:Description rdf:about="http://purl.org/net/dajobe/">
</rdf:Description>
</ex:homePage>
</rdf:Description>
</ex:editor>
</rdf:Description>
Adding the other two paths through the Figure 1
graph gives the result in Example 3:
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<ex:editor>
<rdf:Description>
<ex:homePage>
<rdf:Description rdf:about="http://purl.org/net/dajobe/">
</rdf:Description>
</ex:homePage>
</rdf:Description>
</ex:editor>
</rdf:Description>
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<ex:editor>
<rdf:Description>
<ex:fullName>Dave Beckett</ex:fullName>
</rdf:Description>
</ex:editor>
</rdf:Description>
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<dc:title>RDF/XML Syntax Specification (Revised)</dc:title>
</rdf:Description>
There are several abbreviations that can be used to make very
common uses more easy to write down. In particular, it is very
common that a resource is being described with multiple property /
value pairs as in this example. The resource
http://www.w3.org/TR/rdf-syntax-grammar
has two arcs and the blank node resource also has two arcs.
This can be abbreviated by using multiple child property elements
inside the node element describing the resource which
then become properties of that node.
This is shown in Example 4:
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<ex:editor>
<rdf:Description>
<ex:homePage>
<rdf:Description rdf:about="http://purl.org/net/dajobe/">
</rdf:Description>
</ex:homePage>
<ex:fullName>Dave Beckett</ex:fullName>
</rdf:Description>
</ex:editor>
<dc:title>RDF/XML Syntax Specification (Revised)</dc:title>
</rdf:Description>
When an arc points to a node with has no further arcs,
which appears in RDF/XML as an empty node element sequence such as the pair
<rdf:Description rdf:about="...">
</rdf:Description>, this
form can be shortened. This is done by using the URI of the node
as the value of an XML attribute rdf:resource
on the containing property element and making the property element empty.
In this example, the property element ex:homePage
contains an empty node element with the URI
http://purl.org/net/dajobe/. This can be replaced with
the empty property element form giving the result shown in
Example 5:
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<ex:editor>
<rdf:Description>
<ex:homePage rdf:resource="http://purl.org/net/dajobe/"/>
<ex:fullName>Dave Beckett</ex:fullName>
</rdf:Description>
</ex:editor>
<dc:title>RDF/XML Syntax Specification (Revised)</dc:title>
</rdf:Description>
When a property's value is a literal string (not a resource) it
can be encoded in a shorter form as an XML attribute and value of the
node element. This can be done only if the property is not repeated,
which is required by XML - attribute names are unique on an XML
element. This abbreviation is known as a Property Attribute
and can be applied to any node (or see below,
rdf:parseType="Resource" form).
This from can also be used (as a special case)
when the property element is rdf:type,
which always takes a resource node value.
In our example, there are two property elements with literal string
values, the dc:title and ex:fullName
property elements. These can be replaced with property attributes
giving the result shown in Example 6:
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar"
dc:title="RDF/XML Syntax Specification (Revised)">
<ex:editor>
<rdf:Description ex:fullName="Dave Beckett">
<ex:homePage rdf:resource="http://purl.org/net/dajobe/"/>
</rdf:Description>
</ex:editor>
</rdf:Description>
To create a complete RDF/XML document, the graph must be contained
inside an rdf:RDF XML element which becomes the
top-level XML document element. It is conventionally the element on
which the XML namespaces that are used are defined, although that is
not required. Additionally, the XML declaration should also be put
at the top of the document with the XML version and possibly the XML
content encoding (this is optional but recommended).
This could be done for any of the complete graph examples from
Example 3 onwards but taking the smallest
Example 6 and adding the final components,
gives the complete RDF/XML representation of the original
Figure 1 graph
in Example 7:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar"
dc:title="RDF/XML Syntax Specification (Revised)">
<ex:editor>
<rdf:Description ex:fullName="Dave Beckett">
<ex:homePage rdf:resource="http://purl.org/net/dajobe/" />
</rdf:Description>
</ex:editor>
</rdf:Description>
</rdf:RDF>
RDF/XML uses XML's xml:lang attribute as defined by
2.12 Language Identification
of XML 1.0 [XML]
to allow the identification of content language.
This can be added to any XML element to indicate that the included content is
in the given language. The most specific in-scope language present
(if any) is applied to literal property element or
property attribute values. The xml:lang="" form
is used to indicate absence of language.
Some examples of marking content languages for RDF properties are shown in
Example 8:
<?xml version="1.0" encoding="iso-8859-1"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<dc:title>RDF/XML Syntax Specification (Revised)</dc:title>
<dc:title xml:lang="en">RDF/XML Syntax Specification (Revised)</dc:title>
<dc:title xml:lang="en-US">RDF/XML Syntax Specification (Revised)</dc:title>
<dc:description xml:lang="it">Il Pagio di Web Fuba</dc:description>
</rdf:Description>
<rdf:Description rdf:about="http://example.org/buchen/baum" xml:lang="de">
<dc:title>Das Baum</dc:title>
<dc:description>Das Buch ist außergewöhnlich</dc:description>
<dc:title xml:lang="en">The Tree</dc:title>
</rdf:Description>
</rdf:RDF>
RDF allows
XML Literals
([RDF-CONCEPTS] Section 3.2.2)
to be given as the value of arcs.
These are written in RDF/XML as content of a property element (not
property attribute) and indicated using the
rdf:parseType="Literal" attribute on the containing
property element.
An example of writing an XML literal is given in
Example 9 where
there is a single RDF triple with the subject node labelled with URI
http://example.org/thingy, the arc labelled with URI
http://example.org/stuff/1.0/prop (from
ex:prop) and the object node labelled with XML
content beginning a:Collection
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://example.org/thingy">
<ex:prop rdf:parseType="Literal" xmlns:a="http://example.org/a#">
<a:Collection required="true">
<a:widget size="10" />
<a:grommit id="23" />
</a:Collection>
</ex:prop>
</rdf:Description>
</rdf:RDF>
RDF allows Datatyped Literals to be given as the value of arcs.
These consist of a literal string (with optional language) and a
datatype URI. This is handled by using the same syntax syntax for
literal string nodes in the property element form (not property
attribute) but with an additional
rdf:datatype="datatypeURI"
attribute on the property element. Any URI can be used in the attribute.
An example of an RDF datatyped literal is given in
Example 10 where
there is a single RDF triple with the subject node labelled with URI
http://example.org/thingy, the arc labelled with URI
http://example.org/stuff/1.0/size (from
ex:size) and the object node with the datatype
("123", http://www.w3.org/2001/XMLSchema#int, no language)
intending to be interpreted as a
W3C XML Schema datatype int.
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://example.org/thingy">
<ex:size rdf:datatype="http://www.w3.org/2001/XMLSchema#int">123</ex:size>
</rdf:Description>
</rdf:RDF>
Blank nodes in the RDF graph are distinct but have no URI label.
It is sometimes required that the same blank node is refered to in the
serialization in multiple places, such as at the subject and object
of several RDF triples. In this case, a Blank Node Identifier
(or bnodeID) can be given to the blank node for identifying it
in the document. This identifier does not exist outside a particular
RDF/XML document or serialization. To use a bnodeID for a blank node,
it can be used on a node element to replace rdf:about="URI"
or on a property element to replace rdf:resource="URI".
Taking Example 7 and explicitly giving
a bnodeID of abc to the blank node in it
gives the result shown in Example 11.
The second rdf:Description property element is
about the blank node.
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar"
dc:title="RDF/XML Syntax Specification (Revised)">
<ex:editor rdf:nodeID="abc"/>
</rdf:Description>
<rdf:Description rdf:nodeID="abc"
ex:fullName="Dave Beckett">
<ex:homePage rdf:resource="http://purl.org/net/dajobe/"/>
</rdf:Description>
</rdf:RDF>
Blank nodes (no resource URI) appear often in RDF graphs and
there is a an abbreviation that allows the extra
<rdf:Description>
</rdf:Description> pair to be omitted.
This is done by putting an attribute on the containing
property element rdf:parseType="Resource"
that turns the property element into a property and node element,
which can now have properties (property elements or property attributes).
This causes the node-arc striping to be broken, which can make
the resulting RDF/XML difficult to read.
Taking the earlier Example 7,
the contents of the ex:editor property element
could be alternatively done in this fashion to give
the abbreviation shown in Example 12:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar"
dc:title="RDF/XML Syntax Specification (Revised)">
<ex:editor rdf:parseType="Resource">
<ex:fullName>Dave Beckett</ex:fullName>
<ex:homePage rdf:resource="http://purl.org/net/dajobe/"/>
</ex:editor>
</rdf:Description>
</rdf:RDF>
If all the property elements on a blank node have string literal
values (or at most one is rdf:type), these can be
abbreviated by moving them to be property attributes on the
containing property element which is made an empty element.
Taking the earlier Example 7,
the contents of the ex:editor property element
are two properties. Only one is suitable here for using in this
form, so the ex:homePage property element is being
ignored here. The abbreviated form where the
ex:fullName property element moves to be
a property attribute on the ex:editor property element,
the blank node is implicit. The result is shown in
Example 13.
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar"
dc:title="RDF/XML Syntax Specification (Revised)">
<ex:editor ex:fullName="Dave Beckett" />
<!-- Note the ex:homePage property has been ignored for this example -->
</rdf:Description>
</rdf:RDF>
It is very common for RDF graphs to have rdf:type
arcs from nodes. These are conventionally called Typed Nodes
and have a shorthand in RDF/XML to allow this to be expressed more consisely.
This is done by replacing the rdf:Description node element name
with the namespaced-element corresponding to the URI of the value of
the type relationship. There may, of course, be multiple rdf:type
arcs but only one can be used in this way, the others must remain as
property elements or property attributes.
This form is also commonly used in RDF/XML with the built-in
classes in The RDF Namespace:
rdf:Seq, rdf:Bag, rdf:Alt,
rdf:Statement, rdf:Property and
rdf:List.
For example, the RDF/XML in Example 14
could be written as shown in Example 15.
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://example.org/thing">
<rdf:type rdf:resource="http://example.org/stuff/1.0/Document"/>
<dc:title>A marvelous thing</dc:title>
</rdf:Description>
</rdf:RDF>
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<ex:Document rdf:about="http://example.org/thing">
<dc:title>A marvelous thing</dc:title>
</ex:Document>
</rdf:RDF>
RDF/XML allows further abbreviating URIs in XML attributes in two
ways. The XML Infoset provides a base URI attribute xml:base
that sets the base URI for resolving relative URIs. This applies to
all RDF attributes that deal with URIs which are rdf:about,
rdf:resource and rdf:datatype.
The rdf:ID attribute on a node element (not property
element, that has another meaning) can be used instead of
rdf:about and gives a URI equivalent to #
concatenated with the rdf:ID attribute value. So for
example if rdf:ID="name", that would be equivalent
to rdf:about="#name". This provides an additional
check since the same name can only appear once in a single
RDF/XML document, so is useful for defining a set of distinct,
related terms relative to the same URI.
Example 16 shows abbreviating the node
URI of http://example.org/here/#snack using an
xml:base of http://example.org/here/ and
an rdf:ID on the rdf:Description node element.
The value of the ex:prop property element is also relative
to the xml:base value, and the resulting URI is
http://example.org/here/fruit/apple.
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/stuff/1.0/"
xml:base="http://example.org/here/">
<rdf:Description rdf:ID="snack">
<ex:prop rdf:resource="fruit/apple"/>
</rdf:Description>
</rdf:RDF>
RDF has a set of list properties that are mostly used with the
rdf:Seq, rdf:Bag and rdf:Alt
classes, written as typed nodes typcially. The list properties are
rdf:_1, rdf:_2 etc. and can be written
out explicitly like that as property elements or attributes like in
Example 17. There is a rdf:li
special property element that can handle the counting automatically,
turning into rdf:_1, rdf:_2 in order. The
equivalent graph to Example 17 written
in this form is shown in Example 18.
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Seq rdf:about="http://example.org/favourite-fruit">
<rdf:_1 rdf:resource="http://example.org/banana"/>
<rdf:_2 rdf:resource="http://example.org/apple"/>
<rdf:_3 rdf:resource="http://example.org/pear"/>
</rdf:Seq>
</rdf:RDF>
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Seq rdf:about="http://example.org/favourite-fruit">
<rdf:li rdf:resource="http://example.org/banana"/>
<rdf:li rdf:resource="http://example.org/apple"/>
<rdf:li rdf:resource="http://example.org/pear"/>
</rdf:Seq>
</rdf:RDF>
RDF/XML allows a closed set of nodes to be given as the value of
a property by using the rdf:parseType="Collection"
attribute on a property element. The value is the collection of nodes
given inside. The exact graph generated is described in detail in
Section 7.2.17 Production parseTypeCollectionPropertyElt.
Example 19 shows a collection of three
nodes in a collection at the end of the ex:hasFruit
property element.
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://example.org/basket">
<ex:hasFruit rdf:parseType="Collection">
<rdf:Description rdf:about="http://example.org/banana"/>
<rdf:Description rdf:about="http://example.org/apple"/>
<rdf:Description rdf:about="http://example.org/pear"/>
</ex:hasFruit>
</rdf:Description>
</rdf:RDF>
The rdf:ID attribute can be used on a property
element to reify the triple that it generates (See
section 7.3 Reification Rules for the
full details).
The identifer for the triple is constructed as a relative URI of
# concatenated with the rdf:ID attribute
value. So for example if
rdf:ID="triple", that would be equivalent to the URI
#triple. Each such rdf:ID identifier has
to be unique in the RDF/XML document (from the same set of
identifiers as rdf:bagID).
Example 20 shows a rdf:ID
being used to reify a triple made from the ex:prop
property element giving the reified triple the
URI http://example.org/triples/#triple1.
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/stuff/1.0/"
xml:base="http://example.org/triples/">
<rdf:Description rdf:about="http://example.org/">
<ex:prop rdf:ID="triple1">blah</ex:prop>
</rdf:Description>
</rdf:RDF>
The rdf:bagID attribute can be used on a node element
to give an identifier for a rdf:Bag that lists the
statements generated by the property elements inside the node
element. This allows statements to be made about that bag. The
identifer is constructed as a relative URI of #
concatenated with the rdf:bagID attribute value, like
rdf:ID. So for
example if rdf:bagID="bag", that would be equivalent
to the URI #bag. Each such rdf:bagID
identifier has to be unique in the RDF/XML document (from the same set of
identifiers as rdf:ID).
Example 21 shows a rdf:Bag
with URI http://example.org/bags/#bag1
being made of the triples from inside the rdf:Description
node element.
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/stuff/1.0/"
xml:base="http://example.org/bags/">
<rdf:Description rdf:about="http://example.org/" rdf:bagID="bag1">
<ex:prop1>blah</ex:prop1>
<ex:prop2 rdf:resource="http://example.org/elsewhere/"/>
</rdf:Description>
</rdf:RDF>
The RDF Core Working Group has developed an
RDF Primer
[RDF-PRIMER]
that goes into detail introducing RDF and its applications.
For a longer introduction to the RDF/XML striped syntax
with a historical perspective, see RDF: Understanding the Striped RDF/XML Syntax [STRIPEDRDF].
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL
NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in
this document are to be interpreted as described in
RFC 2119
[KEYWORDS].
The Internet Media Type / MIME type for RDF is
"application/rdf+xml" -
see RFC 3032
(RFC-3023) section 8.18.
The W3C will register this type when this working draft is more stable.
It is recommended that RDF files have the extension
".rdf" (all lowercase) on all platforms.
It is recommended that RDF files stored on Macintosh HFS file
systems be given a file type of "rdf "
(all lowercase, with a space character as the fourth letter).
The
RDF Namespace URI is
http://www.w3.org/1999/02/22-rdf-syntax-ns#
and is typically used in XML with the prefix rdf
although other prefix strings may be used. The namespace contains
the following names only:
- Syntax names (no concepts in the graph)
-
RDF Description ID about bagID parseType resource li
- RDF Classes in the graph
-
Seq Bag Alt Statement Property List
- RDF Properties in the graph
-
subject predicate object type value first rest _n
where n is a non-negative integer.
- RDF Resources in the graph
-
nil
Any other names are not defined and SHOULD generate a warning when
encountered in an application, but should otherwise behave normally,
and treated as properties and/or classes as appropriate for their use.
Throughout this document the terminology rdf:name
will be used to indicate name is from the RDF namespace
and it has a URI of the concatenation of the
·RDF Namespace URI· and name.
For example, rdf:type has the URI
http://www.w3.org/1999/02/22-rdf-syntax-ns#type
Note:
In the 18 December 2001
Working Draft the names aboutEach and aboutEachPrefix were removed
from the language and the RDF namespace by the RDF Core Working Group.
See the resolution of issues
rdfms-abouteach and
rdfms-abouteachprefix
for further information.
Note:
In this version of the working draft, the names List, first,
rest and nil were added to the
RDF namespace by the RDF Core Working Group.
See the resolution of issues
rdfms-seq-representation
for further information.
Group).
Note:
The Working Group invites feedback from the community on the effects
of the removals and additions of these terms on existing
implementations and documents and on the costs and benefits of
adopting a new namespace URI to reflect this change (currently not
proposed by the Working Group).
The
RDF graph
(RDF Concepts and Abstract Data Model Section 3)
uses three types of identifiers (or labels) for nodes and arcs:
- URI references (labeling nodes and arcs)
-
URI references (RDF Concepts and Abstract Data Model Section 3.1)
can be either given as absolute URIs, relative
URIs that have to be resolved to the in-scope base URI
as described in section section 5.3,
constructed from XML Namespace-qualified element and attributes names
(QNames) or from rdf:ID and rdf:bagID attribute values.
XML QNames give URIs by concatenating the namespace URI and
the XML local name. For example, if the XML Namespace prefix
foo has URI http://example.org/somewhere/ then the QName
foo:bar would correspond to the URI
http://example.org/somewhere/bar. Note that this restricts which
URIs can be made and the same URI can be given in multiple ways.
The rdf:ID and
rdf:bagID values generate URIs by
considering them as equivalent to the relative URI "#" concatenated
with the attribute value. This can then be resolved relative to the
in-scope base URI as described in section
section 5.3.
- Literals (labeling object nodes)
RDF Literals (RDF Concepts and Abstract Data Model 3.2) are either
Strings Literals (ibid 3.2.1),
XML Literals (ibid 3.2.2)
or
Datatype Literals
- Blank node Identifiers (labeling nodes)
- These are given local identifiers
in the N-Triples serialization which MUST
match the name
production in
N-Triples.
Note:
In the past, some RDF applications have handled these nodes (then
called anonymous nodes) by generating arbitrary URIs. This
generates a different RDF graph.
See also the Skolemization
section of the RDF Model Theory [RDF-MODEL] Working Draft.
RDF/XML supports
XML Base [XML-BASE]
by being specified in terms of the
XML Information Set
[INFOSET].
This defines a
·base-uri·
accessor for each
·root event· and
·element event·.
RDF/XML uses URI-references throughout
and applies the in-scope Base URI to resolve both
same document references of the forms "#frag"
and "".
An empty same document reference ""
resolves against the URI part of the Base URI; any fragment part
is ignored. See
Uniform Resource Identifiers (URI) [URIS] section 4.2
Implementor Note:
When using a hierarchical base
URI that has no path component (/), it must be added before using as a
base URI for resolving.
- constraint-id
The names used as values of rdf:ID and rdf:bagID
attributes must be unique in a single RDF/XML document since they
come from the same set of names. This applies with respect to the
in-scope
·base-uri·
accessor of the current element; so the same value
can appear on different elements in the same document but
only if the in-scope base-uri values were different.
The syntax of the names must match the
rdf-id production
- constraint-nodeID
The names used as values of rdf:nodeID come from a
set of names that are independent of those of rdf:ID and rdf:bagID.
The syntax of the names must match the
rdf-id production
This syntax is defined in terms of the XML Information Set
represented as objects called Events in the style of the
[XPATH]
Information Set Mapping.
The order of the sequence is XML document order defined below in
Section 6.2 Information Set Mapping.
The sequence of events formed are intended to be similar to the sequence
of events produced by the [SAX2] XML API from
the same XML. These events are then mapped into the RDF Graph
written as N-Triples.
This model is conceptual only and illustrates one way to create
the N-Triples from the XML. It does not mandate any implementation
method - any other method that results in the same N-Triples (RDF
graph) may be used.
In particular:
- The N-Triples may be generated in any order
- Duplicates may be eliminated at any point
- There is no requirement to support N-Triples in any way
- There is no requirement to use [XPATH] or [SAX2]
The syntax does not support non-well-formed XML documents, nor
documents that otherwise do not have an XML Information Set; for
example, that do not conform to
XML Namespaces
[XML-NS].
The Infoset requires support for
XML Base [XML-BASE]
which generates information item properties [base URI] below.
The use of this property in RDF/XML is discussed in
section 5.3
This specification requires an
XML Information Set[INFOSET]
which supports at least the following information items and
properties for RDF/XML:
- Document Information Item
- [document element], [children], [base URI]
- Element Information Item
- [local name], [namespace name], [children], [attributes], [parent], [base URI]
- Attribute Information Item
- [local name], [namespace name], [normalized value]
- Character Information Item
- [character code]
There is no mapping of the following items to data model events:
- Processing Instruction Information Item
- Unexpanded Entity Reference Information Item
- Comment Information Item
- Document Type Declaration Information Item
- Unparsed Entity Information Item
- Notation Information Item
- Namespace Information Item
Other information items and properties have no mapping to
syntax data model events.
There are six types of event defined in the following subsections.
Most events are constructed from an Infoset information item (except
for Identifier,
Literal and
XML Literal). The effect
of an event constructor is to create a new event with a unique identity,
distinct from all other events. Events have accessor operations on them.
and all have the string-value accessor that may be a static value
or computed.
Constructed from an
Document Information Item
and takes the following accessors and values.
- document-element
- Set to the value of document information item property document-element.
- children
- Set to the value of document information item property [children].
- base-uri
- Set to the value of document information item property [base URI].
- language
- Set to the empty string.
Constructed from an
Element Information Item
and takes the following accessors and values:
- local-name
- Set to the value of element information item property [local name].
- namespace-name
- Set to the value of element information item property [namespace name].
- children
- Set to the value of element information item property [children].
- base-uri
- Set to the value of element information item property [base URI].
- attributes
Set to the value of element information item property [attributes].
If the value contains an attribute event xml:lang (that is, the
·local-name·
accessor of the attribute has value "lang" and the
·namespace-name·
accessor of the attribute has value
"http://www.w3.org/XML/1998/namespace"), it is removed
and from the list of attributes and the
·language· accessor is set to the
string-value of the attribute.
All other attributes beginning with xml are then removed
(that is, all attributes with
·namespace-name·
accessors values beginning with
"http://www.w3.org/XML/1998/namespace"). Note: this does not
include xml:base which is already present in the Infoset as the
·base-uri·
accessor.
- URI
- Set to the string value of the concatenation of the
value of the namespace-name accessor and the value of the
local-name accessor.
- li-counter
- Set to the integer value 1.
- bag-li-counter
- set to the integer value 1.
- language
- Set from the
·attributes·
as described above.
If no value is given from the attributes, the value is set to the value of
the language accessor on the parent event (either a
Root Event or an
Element Event), which may be undefined.
- subject
- Has no initial value. Takes a value that is an
Identifier event.
This is used on elements that deal with one node in the RDF graph,
this generally being the subject of a statement.
Has no accessors. Marks the end of the containing element in
the sequence.
Constructed from an
Attribute Information Item
and takes the following accessors and values:
- local-name
- Set to the value of attribute information item property [local name].
- namespace-name
- Set to the value of attribute information item property [namespace name].
- string-value
- set to the value of the attribute information item property [normalized value] as specified by
[XML] (if an attribute whose normalized
value is a zero-length string, then the string-value is also
a zero-length string).
- URI
- Set to a string value of the concatenation of the
value of the
·namespace-name·
and the value of the
·local-name·
accessor.
Constructed from a sequence of one or more consecutive
Character Information Items.
Has the single accessor:
- string-value
- Set to the value of the string made from concatenating the
[character code] property of each of the character information items.
NOTE: This is intended to be identical to how XPath defines this.
A node for a typed identifier which has the following accessors:
- identifier
- Takes a string value.
- identifier-type
- Takes one of the two values "URI" or "bnodeID"
- string-value
The value of this is calculated from the other accessors based on
the ·identifier-type· value as follows.
When "URI", the value is the concatenation of "<", the value of the ·identifier· accessor and ">"
Otherwise ("bnodeID"), the value is the concatenation of "_:" and the value of the ·identifier· accessor.
These events are constructed by giving two values for the
for the ·identifier· and
·identifier-type· accessors.
For further information on identifiers in the RDF graph, see
section 5.2.
An event for a text literal which can have the following accessors:
- literal-value
- Takes a string value.
- literal-language
- Takes a string value.
- literal-datatype
- Takes an optional string value used as a URI.
- string-value
The value is calculated from the other accessors as follows.
If ·literal-language· is empty
then the value is the concatenation of """ (1 double quote),
the value of the
2 ·literal-value· accessor
and """ (1 double quote).
Otherwise the value is the concatenation of """ (1 double quote),
the value of the
·literal-value· accessor
""@" (1 double quote and a '@'),
and the value of the
·literal-language· accessor.
If ·literal-datatype· is not empty
then append to the value calculated above "^^<" concatenated with
the value of the
·literal-datatype· accessor
concatenated with ">".
Note that the double-quoted ·literal-value· string must use the N-Triples
string escapes
for escaping certain characters such as ".
These events are constructed by giving values for the
·literal-value· and
·literal-language· accessors.
Note:
Literals beginning with a Unicode combining character are
allowed however they may cause interoperability problems.
See [CHARMOD] for further information.
An event for an XML literal which can have the following accessors:
- literal-value
- Takes a string value.
- literal-language
- Takes a string value.
- string-value
The value is calculated from the other accessors as follows.
If ·literal-language· is empty
then the value is the concatenation of
"xml"" ('x', 'm', 'l', and 1 double quote),
the value of the
·literal-value· accessor
and """ (1 double quote).
Otherwise the value is the concatenation of
"xml"" ('x', 'm', 'l', and 1 double quote),
the value of the
·literal-value· accessor
""@" (1 double quote and a '@'),
and the value of the
·literal-language· accessor.
Note that the double-quoted literal-value string must use the N-Triples
string escapes
for escaping certain characters such as ".
These events are constructed by giving values for the
·literal-value· and
·literal-language· accessors.
Note:
Literals beginning with a Unicode combining character are
allowed however they may cause interoperability problems.
See [CHARMOD] for further information.
To transform the Infoset into the sequence of events
in document order, each
information item is transformed as described above to generate a
tree of events with accessors and values. Each element event is
then replaced as described below to turn the tree of events
into a sequence in document order.
- The original element event
- The value of the
children
accessor, a possibly empty ordered list of events.
- An end element event
The following notation is used for matching the sequence
of events generated as described in Section 6
and describing the actions to perform for the matches.
The RDF/XML grammar is defined here in terms of its
data model events, using statements of the form:
number event-type event-content
where the event-content is an expression, which may refer
to other event-types (as defined in
Section 6.1),
using constructs of the form given in the
following table. The number is used for reference purposes.
The action may include generating
new triples to the graph, written in
N-Triples
format.
Notation for matching events and grammar actions.
| General Notation |
| Notation |
Meaning |
| event.accessor |
The value of an event accessor. |
| rdf:X |
A URI as defined in section 5.1. |
| "ABC" |
A string of characters A, B, C in order. |
| concat(A, B, ..) |
A string created by concatenating the terms in order. |
| Notation for Matching Events |
| Notation |
Meaning |
| A == B |
A is equal to B. |
| A != B |
A is not equal to B. |
| A | B | ... |
The A, B, ... terms are alternatives. |
| A - B |
The term A but not the term B. |
| anyURI. |
Any legal URI. |
| anyString. |
Any string. |
| list(item1, item2, ...); list() |
An ordered list of events. An empty list. |
| set(item1, item2, ...); set() |
An unordered set of events. An empty set. |
| * |
Zero or more of preceding term. |
| ? |
Zero or one of preceding term. |
| + |
One or more of preceding term. |
root(acc1 == value1,
acc2 == value2, ...) |
Match a Root Event with accessors.
|
start-element(acc1 == value1,
acc2 == value2, ...)
children
end-element() |
Match a sequence of
Element Event with accessors,
a possibly empty list of events as element content and an
End Element Event.
|
attribute(acc1 == value1,
acc2 == value2, ...) |
Match an Attribute Event
with accessors. |
| text() |
Match a text event. |
| Notation for Grammar Actions |
| Notation |
Meaning |
| A := B |
Assigns A the value B. |
| event.accessor := value |
Sets an event accessor to the given value. |
identifier(identifier := value,
identifier-type := value, ...) |
Create a new Identifier Event. |
literal(literal-value := string,
literal-language := language, ...) |
Create a new Literal Event. |
xml(literal-value := string,
literal-language := language, ...) |
Create a new XML Literal Event. |
| 7.2.2 syntaxTerms | rdf:RDF | rdf:ID | rdf:about | rdf:bagID | rdf:parseType | rdf:resource | rdf:nodeID | rdf:datatype |
| 7.2.3 nodeElementURIs | anyURI - ( syntaxTerms | rdf:li ) |
| 7.2.4 propertyElementURIs | anyURI - ( syntaxTerms | rdf:Description | rdf:nil) |
| 7.2.5 propertyAttributeURIs | anyURI - ( syntaxTerms | rdf:Description | rdf:li | rdf:nil) |
| 7.2.6 doc | root(document-element == RDF,
children == list(RDF)) |
| 7.2.7 RDF | start-element(URI == rdf:RDF,
attributes == set())
nodeElementList
end-element() |
| 7.2.8 nodeElementList | ws* (nodeElement ws* )* |
| 7.2.9 nodeElement | start-element(URI == nodeElementURIs
attributes == set((idAttr | nodeIdAttr | aboutAttr )?, bagIdAttr?, propertyAttr*))
propertyEltList
end-element() |
| 7.2.10 ws | White space as defined by
[XML] definition White Space
Rule [3] S
in section
Common Syntactic Constructs |
| 7.2.11 propertyEltList | ws* (propertyElt ws* ) * |
| 7.2.12 propertyElt | resourcePropertyElt |
literalPropertyElt |
parseTypeLiteralPropertyElt |
parseTypeResourcePropertyElt |
parseTypeCollectionPropertyElt |
parseTypeOtherPropertyElt |
emptyPropertyElt |
| 7.2.13 resourcePropertyElt | start-element(URI == propertyElementURIs ),
attributes == set(idAttr?))
ws* nodeElement ws*
end-element() |
| 7.2.14 literalPropertyElt | start-element(URI == propertyElementURIs ),
attributes == set(idAttr?, datatypeAttr?))
text()
end-element() |
| 7.2.15 parseTypeLiteralPropertyElt | start-element(URI == propertyElementURIs ),
attributes == set(idAttr?, parseLiteral))
literal
end-element() |
| 7.2.16 parseTypeResourcePropertyElt | start-element(URI == propertyElementURIs ),
attributes == set(idAttr?, parseResource))
propertyEltList
end-element() |
| 7.2.17 parseTypeCollectionPropertyElt | start-element(URI == propertyElementURIs ),
attributes == set(idAttr?, parseCollection))
nodeElementList
end-element() |
| 7.2.18 parseTypeOtherPropertyElt | start-element(URI == propertyElementURIs ),
attributes == set(idAttr?, parseOther))
propertyEltList
end-element() |
| 7.2.19 emptyPropertyElt | start-element(URI == propertyElementURIs ),
attributes == set(idAttr?, ( resourceAttr | nodeIdAttr )?, bagIdAttr?, propertyAttr*))
end-element() |
| 7.2.20 idAttr | attribute(URI == rdf:ID,
string-value == rdf-id) |
| 7.2.21 nodeIdAttr | attribute(URI == rdf:nodeID,
string-value == rdf-id) |
| 7.2.22 aboutAttr | attribute(URI == rdf:about,
string-value == URI-reference) |
| 7.2.23 bagIdAttr | attribute(URI == rdf:bagID,
string-value == rdf-id) |
| 7.2.24 propertyAttr | attribute(URI == propertyAttributeURIs,
string-value == anyString) |
| 7.2.25 resourceAttr | attribute(URI == rdf:resource,
string-value == URI-reference) |
| 7.2.26 datatypeAttr | attribute(URI == rdf:datatype,
string-value == URI-reference) |
| 7.2.27 parseLiteral | attribute(URI == rdf:parseType,
string-value == "Literal") |
| 7.2.28 parseResource | attribute(URI == rdf:parseType,
string-value == "Resource") |
| 7.2.29 parseCollection | attribute(URI == rdf:parseType,
string-value == "Collection") |
| 7.2.30 parseOther | attribute(URI == rdf:parseType,
string-value == anyString - ("Resource" | "Literal") ) |
| 7.2.31 URI-reference | An attribute ·string-value· interpreted as a URI reference defined in
Uniform Resource Identifiers (URI) [URIS]
BNF production URI-reference. |
| 7.2.32 literal | Any XML element content that is allowed according to
[XML] definition Content of Elements
Rule [43]
content.
in section
3.1 Start-Tags, End-Tags, and Empty-Element Tags |
| 7.2.33 rdf-id | An attribute ·string-value·
matching any legal
[XML] token
Nmtoken |
If the RDF/XML is a standalone XML document
(known by having been given the RDF MIME Type)
then the grammar starts with Root Event
doc.
If the content is known to be RDF/XML by context, such as when
RDF/XML is embedded inside other XML content, then the grammar
can either start
at Element Event
RDF
(only when an element is legal at that point in the XML)
or at production nodeElementList
(only when element content is legal, since this is a list of elements).
For such embedded RDF/XML, the
·base-uri·
value on the outermost element must be initialized from the containing
XML since no
Root Event will be available.
Note that if such embedding occurs, the grammar may be entered
several times but no state is expected to be preserved.
rdf:RDF | rdf:ID | rdf:about | rdf:bagID | rdf:parseType | rdf:resource | rdf:nodeID | rdf:datatype
These are the core terms from the RDF Namespace in
section 5.1
that are part of the RDF/XML syntax and never handled as
RDF properties or classes.
The URIs that are allowed on node elements.
The URIS that are allowed on property elements.
The URIs that are allowed on property attributes.
For element e, the processing of some of the attributes
have to be done before other work such as dealing with children events
or other attributes. These can be processed in any order:
If e.subject
is empty, generate a local blank node identifier i
and n := identifier(identifier := i, identifier-type:="bnodeID"). Then e.subject := n.
The following can then be performed in any order:
If an attribute a with
a.URI == rdf:bagID
is present,
n := identifier(identifier:=concat(e.base-uri, "#", a.string-value), identifier-type:="URI")
then in any order:
S5 Add the following statement to the graph:
n.string-value <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://www.w3.org/1999/02/22-rdf-syntax-ns#Bag> .
-
For the generated statements above
(excluding S5)
in the following order
- S1
- Statements from S2 and S3 in any order
- Statements generated by the propertyEltList children by S4 in document order
If the statement was generated by
S4 from a
propertyElt
and has an existing identifier
e.subject
then s := e.subject.
Otherwise generate a local blank node identifier i
and s := identifier(identifier := i, identifier-type:="bnodeID")
Then reify the statement with event s using the reification
rules in section 7.3
and apply the bag expansion rules in
section 7.5
on event n to give a URI u. Then
the following statement is added to the graph:
If element e has
e.URI =
rdf:li then apply the list expansion rules on element e.parent in
section 7.4
to give a new URI u and
e.URI := u.
For element e, and the single contained nodeElement n
the following statement is added to the graph:
If the rdf:ID attribute a is given, the above
statement is reified with
i := identifier(identifier:=concat(e.base-uri, "#", a.string-value), identifier-type:="URI")
using the reification rules in
section 7.3
and e.subject := i
For element e, and the text event t.
If the rdf:datatype attribute d is given
then o := literal(literal-value := t.string-value, literal-language := e.language, literal-datatype := a.string-value)
otherwise o := literal(literal-value := t.string-value, literal-language := e.language)
and the following statement is added to the graph:
If the rdf:ID attribute a is given, the above
statement is reified with
i := identifier(identifier:=concat(e.base-uri, "#", a.string-value), identifier-type:="URI")
using the reification rules in
section 7.3
and e.subject := i.
For element e and the literal l,
then o := xml(literal-value := l.string-value, literal-language := e.language)
and the following statement is added to the graph:
If the rdf:ID attribute a is given, the above
statement is reified with
i := identifier(identifier:=concat(e.base-uri, "#", a.string-value), identifier-type:="URI")
using the reification rules in
section 7.3
and e.subject := i.
Open Issue:
The result of a literal from
rdf:parseType="Literal" content has been generally decided by the RDF
Core Working Group but all the cases have not been entirely resolved at this
time. The solution will be based on serializing the XML element
content in l to a string in a form defined by
Exclusive XML Canonicalization W3C Candidate Recommendation.
For element e with possibly empty element content c.
Generate a local blank node identifier i
and n := identifier(identifier := i, identifier-type:="bnodeID").
Add the following statement to the graph:
If the rdf:ID attribute a is given, the
statement above is reified with
i := identifier(identifier:=concat(e.base-uri, "#", a.string-value), identifier-type:="URI")
using the reification rules in
section 7.3
and e.subject := i.
If the element content c is not an empty, then use event
n to create a new sequence of events as follows:
Then
process the resulting sequence using production
nodeElement.
For element event e with possibly empty
nodeElementList l. Set
s:=list().
For each element event f in l,
generate a local blank node identifier i,
n := identifier(identifier := i, identifier-type:="bnodeID") and append n to
s to give a sequence of identifier events.
If s is not empty, n is the first event identifier in
s and the following statement is added to the graph:
otherwise the following statement is added to the graph:
If the rdf:ID attribute a is given, the above
statement is reified with
i := identifier(identifier:=concat(e.base-uri, "#", a.string-value), identifier-type:="URI")
using the reification rules in
section 7.3.
If s is empty, no further work is performed.
For each identifier event n in s,
the following statement is added to the graph:
n.string-value <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://www.w3.org/1999/02/22-rdf-syntax-ns#List> .
For each identifier event n in s and the
corresponding element event f in l, the following
statement is added to the graph:
For each consecutive, overlapping pairs of identifier events
(n, o) in s, the following statement is
added to the graph:
If s is not empty, n is the last event identifier
in s, the following statement is added to the graph:
n.string-value <http://www.w3.org/1999/02/22-rdf-syntax-ns#rest> <http://www.w3.org/1999/02/22-rdf-syntax-ns#nil> .
All rdf:parseType attribute values other than the strings
"Resource", "Literal" or "Collection" are treated as if the value was
"Literal". Processing MUST continue at production
parseTypeLiteralPropertyElt.
No extra triples are generated for other rdf:parseType values.
-
If there are no attributes or only the
optional rdf:ID attribute i
then o := literal(literal-value:="", literal-language := e.language)
and the following statement is added to the graph:
and then if i is given, the above statement is reified with
identifier(identifier:=concat(e.base-uri, "#", i.string-value), identifier-type:="URI")
using the reification rules in
section 7.3.
-
Otherwise
If optional rdf:bagID attribute b is given,
n := identifier(identifier:=concat(e.base-uri, "#", b.string-value), identifier-type:="URI")
The following can then be done in any order:
Add the following statement to the graph:
and then if rdf:ID attribute i is given, the above statement is
reified with
identifier(identifier:=concat(e.base-uri, "#", i.string-value), identifier-type:="URI")
using the reification rules in
section 7.3.
-
For all propertyAttr
attributes a (in any order)
If Identifier event n was created, then
generate a local blank node identifier i
and s := identifier(identifier := i, identifier-type:="bnodeID").
Each statement above is then reified with event s
using the reification rules in
section 7.3
and the bag expansion rules in
section 7.5
is applied on event n to give URI u. Then
the following statement is added to the graph:
If Identifier event n was created, add the
following statement to the graph:
n.string-value <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://www.w3.org/1999/02/22-rdf-syntax-ns#Bag> .
Constraint:: constraint-id
applies to the values of rdf:ID attributes
Constraint:: constraint-nodeID
applies to the values of rdf:nodeID attributes
Constraint:: constraint-id
applies to the values of rdf:bagID attributes
For a statement with terms s, p and o
corresponding to the N-Triples:
add the following statements to the graph using the given
Identifier Event r:
r.string-value <http://www.w3.org/1999/02/22-rdf-syntax-ns#subject> s .
r.string-value <http://www.w3.org/1999/02/22-rdf-syntax-ns#predicate> p .
r.string-value <http://www.w3.org/1999/02/22-rdf-syntax-ns#object> o .
r.string-value <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://www.w3.org/1999/02/22-rdf-syntax-ns#Statement> .
For the given element e, generate a new URI u :=
concat("http://www.w3.org/1999/02/22-rdf-syntax-ns#_",
e.li-counter),
increment the
e.li-counter
property by 1 and return u.
For the given element e, generate a new URI u :=
concat("http://www.w3.org/1999/02/22-rdf-syntax-ns#_",
e.bag-li-counter),
increment the
e.bag-li-counter
property by 1 and return u.
There are some
RDF graphs
as defined in the
RDF Concepts and Abstract Data Model Working Draft.
that cannot be serialized in RDF/XML. These are those that:
- Use property names that cannot be turned into XML namespace-qualified names.
- An XML namespace-qualified name
(QName)
has restrictions on the legal characters such that not all property URIs
can be expressed as these names.
It is recommended that implementors of RDF serializers in order to
break a URI into a namespace name and a local name, split it after
the last XML non-Name
character, ensuring that the first character of the name is a
Letter or '_'.
If the URI ends in a
non-Name
character then throw a "this graph cannot be serialized in RDF/XML"
exception or error.
- Use inappropriate reserved names as properties
- For example, a property with the same URI as any of the
syntaxTerms production.
A more detailed discussion of the issues of serializing the RDF graph
to RDF/XML is given in [UNPARSING].
This describes using the original syntax without the subsequently
added rdf:nodeID attribute that now allows all graphs
with blank nodes to be serialized.
If RDF/XML is embedded inside HTML or XHTML this can
add many new elements and attributes, many of which will not be
in the appropriate DTD. This causes validation against the DTD to fail.
The obvious solution of changing or extending the DTD is not practical
for most uses. This problem has been analysed extensively by Sean B. Palmer in
RDF in HTML: Approaches[RDF-IN-XHTML]
and it concludes that there is no single embedding
method that satisfies all applications and remains simple.
The recommended approach is to not embed RDF/XML in HTML/XHTML but
rather to use <link> element in the <head>
element of the HTML/HTML to point at a separate RDF/XML document.
This has been used for several years by the
Dublin Core Metadata Initiative (DCMI)
on its Web site.
To use this technique, the <link> element
href should point at the URI of the RDF/XML content
and the type attribute should be used with the value of
"application/rdf+xml", the proposed MIME Type for
RDF/XML, see Section 4
The value of the rel attribute may also be set to
indicate the relatioship; this is an application dependent value.
The DCMI has used and recommended rel="meta" when linking
in RFC 2731 - Encoding Dublin Core Metadata in HTML[RFC-2731] however
rel="alternative" may also be appropriate.
See
HTML 4.01 link types
and
XHTML Modularization - LinkTypes
for further information.
10 Acknowledgments (Informative)
The following people provided valuable contributions to the document:
- Dan Brickley, W3C/ILRT
- Jeremy Carroll, HP Labs Bristol
- Bijan Parsia, MIND Lab at University of Maryland at College Park
This document is a product of extended deliberations by the RDF
Core working group, whose members have included: Art Barstow (W3C)
Dave Beckett (ILRT), Dan Brickley (W3C/ILRT), Dan Connolly (W3C),
Jeremy Carroll (Hewlett Packard), Ron Daniel (Interwoven Inc), Bill
dehOra (InterX), Jos De Roo (AGFA), Jan Grant (ILRT), Graham Klyne
(Clearswift and Nine by Nine), Frank Manola (MITRE Corporation),
Brian McBride (Hewlett Packard), Eric Miller (W3C), Stephen
Petschulat (IBM), Patrick Stickler (Nokia), Aaron Swartz (HWG), Mike
Dean (BBN Technologies / Verizon), R. V. Guha (Alpiri Inc), Pat Hayes
(IHMC), Sergey Melnik (Stanford University), Martyn Horner (Profium
Ltd).
This specification also draws upon an earlier RDF Model and Syntax
document edited by Ora Lassilla and Ralph Swick, and RDF Schema
edited by Dan Brickley and R. V. Guha. RDF and RDF Schema Working
group members who contributed to this earlier work are:
Nick Arnett (Verity), Tim Berners-Lee (W3C), Tim Bray (Textuality),
Dan Brickley (ILRT / University of Bristol), Walter Chang (Adobe),
Sailesh Chutani (Oracle), Dan Connolly (W3C), Ron Daniel
(DATAFUSION), Charles Frankston (Microsoft), Patrick Gannon
(CommerceNet), RV Guha (Epinions, previously of Netscape
Communications), Tom Hill (Apple Computer), Arthur van Hoff
(Marimba), Renato Iannella (DSTC), Sandeep Jain (Oracle), Kevin
Jones, (InterMind), Emiko Kezuka (Digital Vision Laboratories), Joe
Lapp (webMethods Inc.), Ora Lassila (Nokia Research Center), Andrew
Layman (Microsoft), Ralph LeVan (OCLC), John McCarthy (Lawrence
Berkeley National Laboratory), Chris McConnell (Microsoft), Murray
Maloney (Grif), Michael Mealling (Network Solutions), Norbert Mikula
(DataChannel), Eric Miller (OCLC), Jim Miller (W3C, emeritus), Frank
Olken (Lawrence Berkeley National Laboratory), Jean Paoli
(Microsoft), Sri Raghavan (Digital/Compaq), Lisa Rein (webMethods
Inc.), Paul Resnick (University of Michigan), Bill Roberts
(KnowledgeCite), Tsuyoshi Sakata (Digital Vision Laboratories), Bob
Schloss (IBM), Leon Shklar (Pencom Web Works), David Singer (IBM),
Wei (William) Song (SISU), Neel Sundaresan (IBM), Ralph Swick (W3C),
Naohiko Uramoto (IBM), Charles Wicksteed (Reuters Ltd.), Misha Wolf
(Reuters Ltd.), Lauren Wood (SoftQuad).
11 References
Normative References
-
[RDF-MS]
-
Resource Description Framework (RDF) Model and Syntax Specification, O. Lassila and R. Swick, Editors. World Wide Web Consortium. 22 February 1999. This version is http://www.w3.org/TR/1999/REC-rdf-syntax-19990222. The latest version of RDF M&S is available at http://www.w3.org/TR/REC-rdf-syntax.
-
[XML]
-
Extensible Markup Language (XML) 1.0, Second Edition, T. Bray, J. Paoli, C.M. Sperberg-McQueen and E. Maler, Editors. World Wide Web Consortium. 6 October 2000. This version is http://www.w3.org/TR/2000/REC-xml-20001006. latest version of XML is available at http://www.w3.org/TR/REC-xml.
-
[XML-NS]
-
Namespaces in XML, T. Bray, D. Hollander and A. Layman, Editors. World Wide Web Consortium. 14 January 1999. This version is http://www.w3.org/TR/1999/REC-xml-names-19990114. The latest version of Namespaces in XML is available at http://www.w3.org/TR/REC-xml-names.
-
[INFOSET]
-
XML Information Set, J. Cowan and R. Tobin, Editors. World Wide Web Consortium. 24 October 2001. This version is http://www.w3.org/TR/2001/REC-xml-infoset-20011024. The latest version of XML Information set is available at http://www.w3.org/TR/xml-infoset.
-
[URIS]
- RFC 2396 - Uniform Resource Identifiers (URI): Generic Syntax, T. Berners-Lee, R. Fielding and L. Masinter, IETF, August 1998. This document is http://www.isi.edu/in-notes/rfc2396.txt.
-
[RDF-CONCEPTS]
-
RDF Concepts and Abstract Data Model, G. Klyne, J. Carroll, Editors, World Wide Web Consortium W3C Working Draft, work in progress, 29 August 2002. This version of the RDF Concepts and Abstract Data Model is http://www.w3.org/TR/2002/WD-rdf-concepts-20020829/. The latest version of the RDF Concepts and Abstract Data Model is at http://www.w3.org/TR/rdf-concepts/.
-
[RDF-TESTS]
- RDF Test Cases, A. Barstow and D. Beckett, Editors. Work in progress. World Wide Web Consortium, 15 November 2001. This version of the RDF Test Cases is http://www.w3.org/TR/2001/WD-rdf-testcases-20011115/. The latest version of the RDF Test Cases is at http://www.w3.org/TR/rdf-testcases.
-
[KEYWORDS]
-
RFC 2119 - Key words for use in RFCs to Indicate Requirement Levels, S. Bradner, IETF. March 1997. This document is http://www.ietf.org/rfc/rfc2119.txt.
-
[RFC-3023]
-
RFC 3032 - XML Media Types, M. Murata, S. St.Laurent, D.Kohn, IETF. January 2001. This document is http://www.ietf.org/rfc/rfc3023.txt.
-
[XML-BASE]
-
XML Base, J. Marsh, Editor, W3C Recommendation. World Wide Web Consortium, 27 June 2001. This version of XML Base is http://www.w3.org/TR/2001/REC-xmlbase-20010627/. The latest version of XML Base is at http://www.w3.org/TR/xmlbase/.
Informational References
-
[CHARMOD]
-
Character Model for the World Wide Web 1.0, M. Dürst, F. Yergeau, R. Ishida, M. Wolf, A. Freytag, T Texin, Editors, World Wide Web Consortium Working Draft, work in progress, 20 February 2002. This version of the Character Model is http://www.w3.org/TR/2002/WD-charmod-20020220/. The latest version of the Character Model is at http://www.w3.org/TR/charmod/.
-
[RDF-MODEL]
-
RDF Model Theory, P. Hayes, Editor. Work in progress. World Wide Web Consortium, 14 February 2002. This version of the RDF Model Theory is http://www.w3.org/TR/2002/WD-rdf-mt-20020214. The latest version of the RDF Model Theory is at http://www.w3.org/TR/rdf-mt/.
-
[RDF-PRIMER]
-
RDF Primer, F. Manola, E. Miller, Editors, World Wide Web Consortium W3C Working Draft, work in progress, 19 March 2002. This version of the RDF Primer is http://www.w3.org/TR/2002/WD-rdf-primer-20020319/. The latest version of the RDF Primer is at http://www.w3.org/TR/rdf-primer/.
-
[RDF-VOCABULARY]
-
RDF Vocabulary Description Language 1.0: RDF Schema, D. Brickley, R.V. Guha, Editors, World Wide Web Consortium W3C Working Draft, work in progress, 30 April 2002. This version of the RDF Vocabulary Description Language is http://www.w3.org/TR/2002/WD-rdf-schema-20020430/. The latest version of the RDF Vocabulary Description Language is at http://www.w3.org/TR/rdf-schema/.
-
STRIPEDRDF
- RDF: Understanding the Striped RDF/XML Syntax, D. Brickley, W3C, 2001. This
document is http://www.w3.org/2001/10/stripes/.
-
XPATH
- XML Path Language (XPath) Version 1.0, J. Clark and S. DeRose, Editors. World Wide Web Consortium, 16 November 1999. This version of XPath is http://www.w3.org/TR/1999/REC-xpath-19991116. The latest version of XPath is at http://www.w3.org/TR/xpath.
-
SAX2
- SAX Simple API for XML, version 2, D. Megginson, SourceForge, 5 May 2000. This document is http://sax.sourceforge.net/.
-
- RDF Site Summary (RSS) 1.0, G. Beged-Dov, D. Brickley, R. Dornfest, I. Davis, L. Dodds, J. Eisenzopf, D. Galbraith, R.V. Guha, K. MacLeod, E. Miller, A. Swartz, E. van der Vlist, 2000. This document is http://purl.org/rss/1.0/spec.
-
CC/PP
- Composite Capability/Preference Profiles (CC/PP): Structure and Vocabularies, G. Klyne, F. Reynolds, C. Woodrow, H. Ohto, World Wide Web Consortium Working Draft, work in progress, 15 March 2001. This version is http://www.w3.org/TR/2001/WD-CCPP-struct-vocab-20010315/. The latest version of CC/PP structure and Vocabularies is available at http://www.w3.org/TR/CCPP-struct-vocab.
-
UNPARSING
- Unparsing RDF/XML, J. J. Carroll, HP Labs Technical Report, HPL-2001-294, 2001.
This document is available at http://www.hpl.hp.com/techreports/2001/HPL-2001-294.html.
-
RELAXNG
- RELAX NG Specification, James Clark and MURATA Makoto, Editors, OASIS Committee Specification, 3 December 2001. This version of RELAX NG is http://www.oasis-open.org/committees/relax-ng/spec-20011203.html. The latest version of the RELAX NG Specification is at http://www.oasis-open.org/committees/relax-ng/spec.html.
-
RELAXNG-COMPACT
- RELAX NG Compact, James Clark, Editor. OASIS Working Draft, 7 June 2001. This document is http://www.oasis-open.org/committees/relax-ng/compact-20020607.html.
-
XML Schema Part 0: Primer
-
XML Schema Part 0: Primer - W3C Recommendation, World Wide Web Consortium, 2 May 2001.
-
XML Schema Part 1: Structures
-
XML Schema Part 1: Structures - W3C Recommendation, World Wide Web Consortium, 2 May 2001.
-
XML Schema Part 2: Datatypes
-
XML Schema Part 2: Datatypes - W3C Recommendation, World Wide Web Consortium, 2 May 2001.
-
Schematron
- Schematron, Rick Jelliffe, Academia Sinica Computing Centre, Taibei.
-
[RDF-IN-XHTML]
-
RDF in HTML: Approaches, Sean B. Palmer, 2002
-
[RFC-2731]
-
RFC 2731 - Encoding Dublin Core Metadata in HTML, John Kunze, DCMI, December 1999.
This section records local issues to be resolved
and issues that were reported to the RDF Core Working Group
related to the XML syntax and their disposition. This section is not
the definitive list or description of the latter - see the
RDF Core Working Group issues list.
Decided issues may also have associated test cases which can be
found in the RDF Test Cases
W3C Working Draft.
None.
None.
- rdfms-syntax-incomplete
-
The RDF/XML syntax can't represent an an arbritary graph structure.
On 26th July 2002, the WG
decided
to re-open this issue and accept the
proposal
(as amended)
to add an rdf:nodeID to the syntax for specifying
blank nodes in triple subject and object positions.
On 26th October 2001, the WG
decided that this issue was postponed for consideration by
a future Working Group.
Action:
Added constraint constraint-nodeID
and Production nodeIdAttr,
and amended productions
syntaxTerms,
nodeElement and
emptyPropertyElt
to take rdf:nodeID.
- rdf-namespace-change
-
Should the rdf: and/or rdfs: namespace URI refs be changed?
On 17th June 2002, the RDFCore WG
resolved
to modify the existing RDF and RDFS namespaces rather than create
new ones and seek implementor feedback on this decision.
Action:
None needed.
- rdfms-seq-representation
-
The ordinal property representation of containers does not support recursive processing of containers in languages such as Prolog.
On 31st May 2002 the WG
resolved:
- Approve Jos's test case as the basis for resolving this issue
- Add the new names [rdf:List, rdf:first, rdf:rest and rdf:nil] to the rdf namespace
- use rdf:parseType="Collection"
- typed nodes are permitted as collection members
Action:
Added 7.2.17 Production parseTypeCollectionPropertyElt,
7.2.28 Production parseCollection
and updated
7.2.12 Production propertyElt to use this.
- rdf-ns-prefix-confusion
-
On 25th May 2001, the WG decided that ALL attributes must be namespace qualified. There is a description of the decision, including detail on the grammar productions affected and a collection of test cases
Action:
Removal of original grammar productions 6.6, 6.7, 6.8, 6.9, 6.11, 6.18, 6.32, 6.33
- rdfms-duplicate-member-props
-
may a container have duplicate containerMembership properties?
On 3rd May 2002, the WG
resolved:
<rdf:Bag rdf:about="http://example.org/foo">
<rdf:_1 rdf:resource="http://example.org/a" />
<rdf:_1 rdf:resource="http://example.org/b" />
</rdf:Bag>
is syntactically legal RDF.
Action:
None needed.
- rdfms-abouteachprefix
-
On 1st June 2001, the WG decided that aboutEachPrefix would be
removed from the RDF Model and Syntax Recommendation on the grounds
that there is a lack of implementation experience, and it therefore
should not be in the recommendation. A future version of RDF may
consider support for this feature.
Action:
Removal of original grammar production 6.8
- rdf-containers-syntax-ambiguity
rdf-containers-syntax-vs-schema
-
On 29th June 2001, the WG decided that containers will match the typed node production in the grammar (production 6.13) and that the container specific productions (productions 6.25 to 6.31) and any references to them be removed from the grammar. rdf:li elements will be translated to rdf:_nnn elements when they are found matching either a propertyElt (production 6.12) or a a typedNode (production 6.13). The decision includes a set of test cases.
Action:
Removal of original grammar productions 6.25, 6.26, 6.27, 6.28, 6.29, 6.30, 6.31
- rdfms-empty-property-elements
-
On 8th June 2001 the WG decided how empty property elements should be interpreted. The decision is fully represented by the test cases.
Action:
Inserted pointers to the the test cases into the grammar at the
places where empty property elements are recognized.
- rdfms-aboutEach-on-object
-
On 29th June 2001, the WG decided that rdf:aboutEach attributes
are not allowed on an rdf:Description (or typed node) element which
is the object of a statement.
Action:
None needed - rdf:aboutEach removed from the language on 7th December 2001.
- rdfms-syntax-desc-clarity
-
The language describing the syntax is unclear [in section 6]
On 26th October 2001, the WG
decided that this issue is closed by the new approach
to defining the syntax in this document.
Action:
A main goal of this document is to make the syntax clearer and
more precise. In particular
the grammar section and the
pointers to schemas for XML validation
help address this.
- rdfms-formal-grammar
-
A formal grammar for RDF.
On 26th October 2001, the WG
decided that this issue is closed by the new approach
to defining the syntax in this document.
Action:
A main goal of this document is to make the syntax clearer and
more precise. In particular
the grammar section and the
pointers to schemas for XML validation
help address this.
- rdfms-validating-embedded-rdf
-
On 9th November 2001, the RDFCore WG resolved to postpone
the issue "for later consideration on the grounds that it is out of
scope of its current charter to change the current RDF/XML syntax to
the extent necessary to address it."
Action:
None needed.
- rdfms-rdf-names-use
-
On 30th November 2001, the WG
decided that this issue was closed by the following resolution.
The use of rdf:RDF, rdf:ID, rdf:about, rdf:resource, rdf:bagID,
rdf:parseType, rdf:aboutEach and rdf:li except as reserved names as
specified in the grammar is an error. [Later rdf:aboutEach was
removed from the language on 7th December 2001]
On 25th February 2002, the WG further
resolved that:.
The WG reaffirmed its decision not to restrict names in the RDF
namespaces which are not syntactic. The WG decided that an RDF
processor SHOULD emit a warning when encountering names in the RDF
namespace which are not defined, but should otherwise behave
normally.
Action:
Added note to section 5.1 RDF Namespace
- rdfms-abouteach
-
processing rdf:aboutEach requires a processing of sub-property relations.
On 7th December 2001, the WG
resolved
to remove rdf:aboutEach from the language.
Action:
Removed from the grammar.
- rdfms-propElt-id-with-dr
-
On 7th December 2001, the WG
decided
to remove rdf:aboutEach from the language and consequently
this issue was closed.
Action:
None needed.
- rdfms-difference-between-ID-and-about
-
What is the difference between using and ID attribute to 'create' a new resource and an about attribute to refer to it?
On 14th December 2001, the WG
decided that this document resolves the issue.
Action:
See section on Identifiers for details.
- rdfms-qname-uri-mapping
-
On 11th January 2002, the WG
resolved (revised) "to not change the algorithm for mapping qnames to uris and close this issue on the grounds":
- Such a change would be a major change to the mapping of
RDF/XML syntax to the model and would be beyond our charter.
- It would cause the same RDF/XML to generate a different
graph from existing versus revised implementations
- Existing code may generate wrong (illegal) graphs for some RDF/XML.
Action:
None needed.
- rdfms-reification-required
-
On 11th January 2002, the WG
resolved (revised) "that a parser is not required to create bags of reified statements for all rdf:Description elements, only those which are
explicitly reified using an rdf:ID on a propertyElt or by an rdf:bagID
on the rdf:Description.
Existing test cases such as rdf-ns-prefix-confusion
test0001 (test0001.rdf, test0001.nt)
demonstrate this resolution."
Action:
None needed - matches the existing syntax description.
- rdfms-replace-value
-
On 11th January 2002, the WG
resolved (revised) "to not change the name of this property at this time on the grounds:
- insufficient reasons to make this change
- will cause existing uses to be illegal - such as examples in M&S.
and resolves to recast the issue as a need to clarify the
semantics of rdf:value."
At the February 2002 face to face meeting, the RDFCore WG resolved:
- that rdf:value is a property defined in the RDF namespace
- that the model theory state that rdf:value is a property
- that no other model theory semantics is defined specifically for it
- the issue be closed.
Action:
None needed.
- mime-types-for-rdf-docs
-
On 18th January 2002, the WG
authorized
the removal of this issue from this document by the adding a new
section with the wording
proposed
now included in the RDF MIME type section.
When the WG is ready (documents are stable), the MIME content-type
registration for application/rdf+xml will proceed.
Action:
Added RDF MIME type section.
- rdfms-xml-base
-
On 18th January 2002, the WG
decided
that "xml:base be allowed, and honored, anywhere in an RDF document".
On 25th February 2002, the WG decided
(1)
that xml:base applies to RDF's use of document references (fragments)
(2)
that xml:base hierarchical URIs without a path component shall have it
set to /.
(3)
the scope of xml:base attributes should be taken into account when checking
for duplicate rdf:ID values
Action:
Added details in
Section 6 Data Model
near introduction of Infoset and added new
Section 5.3 Base URIs
- rdfms-nested-bagIDs
-
What triples are generated for nested description elements with bagIDs?
On 25th February 2002, the WG
decided that this issue was closed by the following resolution.
A bagID reifies the property attributes on the same element as the
bagid, the type node and statements immediately arising from property
elements that are immediate children of the element containing the
bagId. In particular a property element whose statement is part of
the bag, which has property attributes, those statements are not part
of the bag.
Action:
bagID algorithm added to nodeElement
emptyPropertyElt.
- rdfms-not-id-and-resource-attr
-
The propertyElt production 6.12 of the grammar does not allow both an ID attribute and a resource attribute to be specified.
On 25th February 2002, the WG
decide that this issue was closed by making rdf:ID always specify the ID of the reified statement (parent node, property element, node).
Action:
Updated 7.2.19 Production emptyPropertyElt
and Relax NG schema
to reflect decision.
- rdfms-xmllang
-
Why isn't xml:lang information represented within the RDF data model?
On 25th February 2002, the WG
decided that this issue was closed by the following resolution.
A literal consists of three components:
- A representation of the parseType, which is a single bit
- A language indicator which is a string as defined in XML
- A fully normalized UNICODE string.
Action:
Added the language node term from
the value of xml:lang attributes, added
sections Literal Node,
and XML Literal Node
and updated
parseTypeOtherPropertyElt
for parseType.
- rdfms-xml-literal-namespaces
-
How should a parser process namespaces in a literal which is XML markup?
On 15th March 2002, the WG
decided that this issue was closed by the following resolution.
- The exact form of the string value corresponding to any given XML
Literal within RDF/XML is implementation dependent.
- the string value is well-balanced XML
- taking the exclusive canonicalization of both the original XML
Literal in its containing document, and the string value of the
literal produce the same character string. This will be used as
the basis for test cases.
- The canonicalization above is without comments i.e.
CONFORMANCE should be tested without comments; dropping
comments was NOT mandatory.
- this issue is closed
- to raise a comment on the XQuery/XPath 2.0 data model that it
does not adequately address the handling of namespace prefixes
appearing in attribute values.
Action:
Discussed in
RDF Concepts and Abstract Data Model [RDF-CONCEPTS]
Section 3.2.2 XML Literals
and
Section 4.1 Character normalization
- rdf-charmod-literals
-
Does the treatment of literals conform to charmod ? [CHARMOD]
On 5th April 2002, the RDFCore WG resolved this issue by
approving
test cases
white,
black 1
and
black 2
submitted
for consideration. The grey test cases were not approved; instead the
WG decided to add text to the syntax specification pointing out that
literals beginning with a combining character may not be serializable
in RDF/XML, depending on the outcome of
[CHARMOD],
and may cause interoperability problems.
Action:
Notes added: 1, 2
Discussed in
RDF Concepts and Abstract Data Model [RDF-CONCEPTS]
Section 4.1 Character normalization
- rdf-charmod-uris
-
Does the treatment of uri-references conform with charmod? [CHARMOD]
On 26th April 2002, the WG
decided to:
Action:
leave URI references as un-escaped Unicode
and approved
test cases,
later moved into the
rdf-charmod-literals test cases area.
- rdfms-quoting
-
The syntax needs a more convenient way to express the
reification of a statement.
On 26th October 2001, the WG
decided that this issue was postponed for consideration by
a future Working Group.
Action:
None needed.
- rdfms-qnames-cant-represent-all-uris
-
The RDF XML syntax cannot represent all possible Property URI's.
On 26th October 2001, the WG
decided that this issue was postponed for consideration by
a future Working Group.
Action:
None needed.
- rdfms-qnames-as-attrib-values
-
Suggestion that Qnames should be allowed as values for attributes such as rdf:about.
On 26th October 2001, the WG
decided that this issue was postponed for consideration by
a future Working Group.
Action:
None needed.
B Syntax Schemas (Non-Normative)
Two schema language authors submitted schemas for RDF/XML based on
the revised grammar in the previous version of this draft. We
include pointers to these schemas for information purposes and an
example schema; they are not part of this specification.
B.1
RELAX NG Compact Schema (Non-Normative)
This is an example schema in RELAX NG Compact (for ease of reading)
but applications can also use the
RELAX NG XML version.
These formats are described in
RELAX NG ([RELAXNG])
and RELAX NG
Compact ([RELAXNG-COMPACT]).
#
# RELAX NG Schema (non-XML) for RDF/XML Syntax
#
# This schema is for information only and NON-NORMATIVE
#
# It is based on one originally written by James Clark in
# http://lists.w3.org/Archives/Public/www-rdf-comments/2001JulSep/0248.html
# and updated with later changes.
#
namespace local = ""
namespace rdf = "http://www.w3.org/1999/02/22-rdf-syntax-ns#"
datatypes xsd = "http://www.w3.org/2001/XMLSchema-datatypes"
start = doc
doc =
RDF
RDF =
element rdf:RDF { nodeElementList }
nodeElementList =
nodeElement*
# Should be something like:
# ws* , ( nodeElement , ws* )*
# but RELAXNG does this by default, ignoring whitespace separating tags.
nodeElement =
element * - (local:*
|rdf:RDF
|rdf:ID|rdf:about
|rdf:bagID|rdf:parseType|rdf:resource
|rdf:li ) {
(idAttr | aboutAttr )?, bagIdAttr?, propertyAttr*, propertyEltList
}
# It is not possible to say "and not things
# beginning with _ in the rdf: namespace" in RELAX NG.
ws =
" "
# Not used in this RELAX NG schema; but should be any legal XML
# whitespace defined by http://www.w3.org/TR/2000/REC-xml-20001006#NT-S
propertyEltList =
propertyElt*
# Should be something like:
# ws* , ( propertyElt , ws* )*
# but RELAXNG does this by default, ignoring whitespace separating tags.
propertyElt =
resourcePropertyElt |
literalPropertyElt |
parseTypeLiteralPropertyElt |
parseTypeResourcePropertyElt |
parseTypeOtherPropertyElt |
emptyPropertyElt
resourcePropertyElt =
element * - (local:*
|rdf:RDF|rdf:Description
|rdf:ID|rdf:about
|rdf:bagID|rdf:parseType|rdf:resource) {
idAttr?, nodeElement
}
literalPropertyElt =
element * - (local:*
|rdf:RDF|rdf:Description
|rdf:ID|rdf:about
|rdf:bagID|rdf:parseType|rdf:resource) {
idAttr?, text
}
parseTypeLiteralPropertyElt =
element * - (local:*
|rdf:RDF|rdf:Description
|rdf:ID|rdf:about
|rdf:bagID|rdf:parseType|rdf:resource) {
idAttr?, parseLiteral, literal
}
parseTypeResourcePropertyElt =
element * - (local:*
|rdf:RDF|rdf:Description
|rdf:ID|rdf:about
|rdf:bagID|rdf:parseType|rdf:resource) {
idAttr?, parseResource, propertyEltList
}
parseTypeOtherPropertyElt =
element * - (local:*
|rdf:RDF|rdf:Description
|rdf:ID|rdf:about
|rdf:bagID|rdf:parseType|rdf:resource) {
idAttr?, parseOther, any
}
emptyPropertyElt =
element * - (local:*
|rdf:RDF|rdf:Description
|rdf:ID|rdf:about
|rdf:bagID|rdf:parseType|rdf:resource) {
idAttr?, resourceAttr?, bagIdAttr?, propertyAttr*
}
idAttr =
attribute rdf:ID {
IDsymbol
}
aboutAttr =
attribute rdf:about {
URI-reference
}
bagIdAttr =
attribute rdf:bagID {
IDsymbol
}
propertyAttr =
attribute * - (local:*
|rdf:RDF|rdf:Description
|rdf:ID|rdf:about
|rdf:bagID|rdf:parseType|rdf:resource
|rdf:li) {
string
}
resourceAttr =
attribute rdf:resource {
URI-reference
}
parseLiteral =
attribute rdf:parseType {
"Literal"
}
parseResource =
attribute rdf:parseType {
"Resource"
}
parseOther =
attribute rdf:parseType {
text
}
URI-reference =
string
literal =
any
IDsymbol =
xsd:NMTOKEN
any =
mixed { element * { attribute * { text }*, any }* }
B.2 Other Syntax Schemas (Non-Normative)
Two schema language authors submitted schemas for RDF/XML based on
the new grammar in previous versions of this draft. The pointers to
these schemas are included here for information purposes only; they
are not part of this specification.
Changes since the 25 March 2002 working draft
(Newest at top)
- FIXME updated to CVS 1.349
- Added Section 2 sub-sections to table of contents
- Added Section 2.12 Omitting Blank Nodes - Property Attributes on an empty Property Element
with example.
- Cut down Section 8 Serializing an RDF Graph to RDF/XML now that
rdf:nodeID
allows many more graphs to be serialized.
- Update for N-Triples syntax for datatype literals: "foo"@en^^<datatypeURI>
- Added lots of pointers to RDF Concepts and Abstract Data Model working draft
- Massive update to Section 2 - An XML syntax for RDF - added 20 examples to cover hopefully all of RDF/XML
- Added rdf:datatype to the syntax
- Issue rdfms-duplicate-member-props closed - no action needed.
- Issue rdfms-seq-representation closed
Added rdf:parseType="Collection" to the syntax.
Added
parseTypeCollectionPropertyElt,
parseCollection
to grammar and updated propertyElt.
- Issue rdf-namespace-change closed - no action needed.
- Reordered the document structure.
3 to 6,
3.1 to 6.1,
3.2 to 6.2,
3.3 to 4,
3.4 to 5.1,
3.5 to 5.2,
3.6 to 5.4,
3.7 to 5.3,
4 --,
4.1 to 3,
4.2 to 6.3,
5 to 7,
5.0 to 7.1,
5.1..5.25 to 7.2.x,
5.26 to 7.3,
5.27 to 7.4,
5.28 to 7.5,
5.29 to 7.6,
X to 8,
6 to 9,
7 to 10,
8 to 11
- Issue rdfms-syntax-incomplete
(reopened, updated)
Added rdf:nodeID attribute and
constraint-nodeID.
Updated nodeElement,
emptyPropertyElt grammar terms.
Added nodeIdAttr.
- Issue faq-html-compliance closed
Added Section 9 Using RDF/XML with HTML and XHTML
- Section 6.3 Notation
Split into general, matching and action notations.
Renamed start_element to start-element and end_element to end-element.
Changed notation of equality to == and assignment to :=
- Many rewordings and changes after extensive feedback from Bijan Parsia.
- Issue rdfms-seq-representation closed
Section 5.1 RDF Namespace - Added
rdf:List, rdf:first, rdf:rest, rdf:nil
- Renamed Nodes throughtout with Events.
- Updated after
comments by Brickley, 2002-03-24
Replaced model with graph throughout.
Section 8 Serializing
Updated to reword the introduction and added a note that information
is lost when blank nodes are labeled with URI-refs.
- Update after
comments by Patel-Schneider, 2002-05-21
outlined in
response 1 and
response 2.
nodeElement -
moved "if e.subject is empty" point to after
rdf:ID and rdf:about processing.
Section 5.4 Constraints -
added and moved the
rdf:ID and rdf:bagID constraints
there linked from the old location in the grammar.
Section 2 Updates on abbreviation of
properties into XML attributes
- Section 6 Serializing Changed "not used" to "no mapping" for other infoitem types.
- Changed data model 'property'/'properties' to 'accessor'/'accessors'
- Issue rdf-charmod-literals closed
Added note 1
and node 2
near literal event descriptions.
- Section 6 Serializing
Ensure spliting a URI results in a legal XML name;
it must start with a letter or _ following XML's
Name
production.
- Section 6.1.7, Section 6.1.8: Added note 1,
note 2
warning about literals beginning with combining chars
- Issue rdfms-xmllang closed.
Added the language node term from
the value of xml:lang attributes.
Added sections Literal Node,
and XML Literal Node
and updated
parseTypeOtherPropertyElt
for rdf:parseType.
Changes since the 18 December 2001 working draft
(Newest at top)
- Updated status and abstract for this WD
- Updated table of contents to include substructure of section 7
- Require that URIs MUST NOT be generated for blank identifiers
- Specify syntax/non-syntax parts of RDF namespace
- Use RDF graph rather than RDF model throughout
- Sections Literal Node,
and XML Literal Node that
N-Triple string escape rules
are required when generating N-Triple strings
- Remove xml* attributes that are not used (we use xml:lang, Infoset uses xml:base)
- Added references to
RDF Primer
[RDF-PRIMER] working draft
- Section 2: Added more examples to illustrate
some (not all) syntax abbreviations
- Added xml:lang support by adding a new element property, using it
throughout to generate literal() or xml() literals
- Added a grammar summary section (experimental)
- Added an explicit constraint on rdf:ID and rdf:bagID values, and with
respect to the base URI
- Updated notation for A:=B assignment, string literal and xml literals
- Removed note on propertyElt about
potential future parseTypes values
- Correct the illegal rdf:* names on node and property elements
- List all infoitems indicating ones that
are not used; and note that all infoitems must be preserved inside
parseTypeLiteral
- In rdf-id production, kept rdf:ID as XML Nmtoken
- Added style from XSD for term definition and reference
- Introduction gained pictures taken from draft primer
- Added Nodes for all SAX-like nodes
- Added rdf:bagID rules in nodeElement
and emptyPropertyElt
- Added Section 5.3 Base URIs for XML Base support, updated other sections and added to references
- emptyPropertyElt: Allow rdf:ID and rdf:resource together; updated Relax NG schema to match
- Section 5.1: Noted unknown rdf: names generate a warning
- Section 5.3: Made parseType only take "Resource", "Literal" and other values are
always the same as "Literal"
- Added Section 4 RDF MIME Type to note proposed mime type
- Updated issues list to record closed and postponed issues
- Removed original grammar (Appendix C), updated grammar (Appendix D) sections
Changes since the 06 September 2001 working draft
- Most of the document is new
- Original document grammar sections moved to appendices
- Expressed in more detail the use of the XML Infoset as used here
in a SAX-like manner
- Grammar updated to remove rdf:aboutEach - see
rdfms-abouteach for details.
- Added the mapping to the RDF Model as expressed by N-Triples
- Added the non-normative RELAX NG schema
- Added Issue sections
- Added serialization section
- Added introduction to the RDF/XML syntax
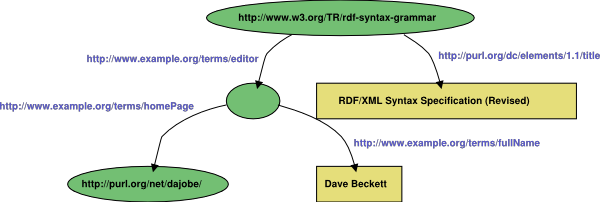
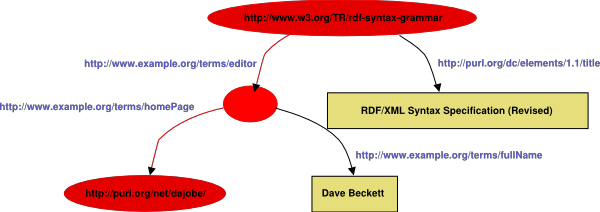
{kind=link}
{kind=link}