- From: Sergey Melnik <melnik@db.stanford.edu>
- Date: Wed, 24 Oct 2001 20:45:51 -0700
- To: RDFCore WG <w3c-rdfcore-wg@w3.org>
- Message-ID: <3BD78AEF.82B2D21E@db.stanford.edu>
CONTENTS
--------
In this posting I suggest to narrow down the range of options of how
datatyping is introduced in RDF. It may be premature to vote on the
suggestions <SUG1>,<SUG2> and <SUG3> (see below) at the upcoming
telecon, but I'd like you to think about them and form an opinion.
In (1), I propose to use the existing standards XML Schema, UML, and
CWM as a foundation of our datatyping discussion. Ideally, any
(primitive) datatypes defined by these standards should be usable in
RDF.
In (2), I formulate the suggestion to focus on the triple structure as
a datatyping vehicle.
In (3), I summarize my understanding of how datatypes and datatyping
are dealt with in XML Schema and UML.
Finally, in (4) I examine a number of examples that involve types,
units, xml:lang, etc. and several ways of how these can be represented
within the boundaries set by <SUG2> and <SUG3>.
1 FOUNDATION
------------
<SUG1>: I'd like to propose to use the standards specs listed below as a
foundation of our work on datatyping:
[XSD] XML Schema Part 2: Datatypes. http://www.w3.org/TR/xmlschema-2/
(May 2001)
[UML] Unified Modeling Language 1.4.
ftp://ftp.omg.org/pub/docs/formal/01-09-67.pdf (Sep 2001)
[CWM] Common Warehouse Metamodel 1.0.
ftp://ftp.omg.org/pub/docs/ad/01-02-01.pdf (Feb 2001)
To my knowledge, we already reached a concensus on that we want to
exploit [XSD]. Additionally, I believe we should leverage the efforts
of the OMG that resulted in [UML] and [CWM]. The committees that
produced these specs spent a lot of thought and sweat on
datatyping. Furthermore, I'd like us to investigate whether and how
the datatypes defined in the above specs (at least the primitive
types) can be used in RDF.
2 FOCUSING ON TRIPLE STRUCTURE
------------------------------
As of now, we identified two fundamental (orthogonal) dichotomies with
respect to datatyping:
a) we can either have a literal as a structured entity, of which the
type is a part, or the typing info can be represented in the triple
structure. (Quoted from Brian's posting).
b) typing information can either be represented in an instance graph
only,
in a schema graph only, or both.
The suggestion that I'd like you to think about concerns the dimension
(a).
<SUG2>: to focus on representing typing info in the triple structure
and keep literals atomic.
3 DATATYPES AND DATATYPING
--------------------------
3.1 Value spaces and lexical spaces in [XSD]
--------------------------------------------
A nice conceptual intro to the datatyping issue is provided in the
[XSD] document. According to [XSD], each datatype is characterized by
a *value space* and a *lexical space*. For example, take the type
"decimal". Its value space are all arbitrary precision decimal
numbers, whereas its lexical space includes all character strings that
match a certain pattern. In [XSD], a datatype definition specifies a
mapping between the value space of the datatype and its lexical
space. Notice that in general more than one lexical token may map to
the same data value.
My working understanding of the [XSD] document in terms of the current
model theory draft is that the elements of a lexical space are literal
values.
3.2 Datatypes as classifiers in [UML,CWM]
-----------------------------------------
[UML] and [CWM] treat datatypes as some kind of classes (or
classifiers in UML terminology). In other words, datatypes have
"instances" which are called *data values*. Here are the relevant
quotes:
[UML], Sec 2.5.2.14: "Datatype"
A data type is a type whose values have no identity; that is, they
are pure values. Data types include primitive built-in types (such
as integer and string) as well as definable enumeration types
(such as the predefined enumeration type boolean whose literals
are false and true).
[CWM], Sec 7.6.1.1: "DataValue"
A data value is an instance with no identity. In the metamodel,
DataValue is a child of Instance that cannot change its state,
i.e. all operations that are applicable to it are pure functions
or queries that do not cause any side effects. DataValues are
typically used as attribute values. Since it is not possible to
differentiate between two data values that appear to be the same,
it becomes more of a philosophical issue whether there are several
data values representing the same value or just one for each
value. In addition, a data value cannot change its data type and
it does not have contained instances.
[UML], Sec 2.5.2.34: "Primitive"
A Primitive defines a predefined DataType, without any relevant
UML substructure; that is, it has no UML parts. A primitive
datatype may have an algebra and operations defined outside of UML
(for example, mathematically). Primitive datatypes used in UML
itself include Integer, UnlimitedInteger, and String. The
run-time instances of a Primitive datatype are DataValues. The
values are in many-to- one correspondence to mathemetical elements
defined outside of UML (for example, the various integers).
[UML], Sec 2.5.4.10: "Miscellaneous"
... A data type is a special kind of classifier, similar to a class,
but whose instances are primitive values (not objects). For
example, the integers and strings are usually treated as primitive
values. A primitive value does not have an identity , so two
occurrences of the same value cannot be differentiated. Usually,
it is used for specification of the type of an attribute. An
enumeration type is a user-definable type comprising a finite
number of values. ...
Translated into RDF terms, a data value corresponds to a bNode in a
graph.
3.2 Datatyping: classes or mappings?
------------------------------------
As pointed out above, reading [XSD] gives an impression that
datatyping is a kind of mapping that establishes a relationship
between data values and literal values. In contrast, [UML] talks
merely about the value spaces of datatypes and does not say anything
about their lexical spaces. As a consequence, [UML] does not establish
any mappings between value spaces and lexical spaces of the primitive
datatypes. Still, [UML] does define the "features" of value spaces
that include ordering, operations etc.
To sum up, the specs [XSD,UML,CWM] utilize two abstract concepts:
- datatype as a class(ifier)
- datatyping as a mapping between a value space and a lexical space
My feeling is that both views may be useful for representing typed
data (just as wave-particle dualism is helpful for explaining
different phenomena in physics ;). On the one hand, if data values do
not have fixed URI identifiers, we need a *mapping* that allows us to
identify resources as data values using their lexical representations.
On the other hand, for defining and resticting datatypes, the class
view is superior (although it looks like the class view is in
principle dispensable).
3.3 Literal properties as "datatyping mappings"?
------------------------------------------------
One final point that I'd like to make before turning to examples is
that properties with literal values possess a high resemblance to
datatyping mappings. Assume that the interpretation of each literal
symbol is fixed and is determined by its textual contents. Then, since
each literal symbol denotes just a lexical token, it presumably does
not make sense to use it as object for properties like "age", "size",
"price", "weight", etc. In fact, such use would suggest that e.g. the
weight of a thing is a lexical token; typically, we'd like it to
denote some abstract entity that corresponds to say 5 pounds.
In other words, for most meaningful representations, we can think of a
property whose objects are literals as a mapping that associates a
value space with some lexical space. In yet other words, each
literal-valued property may be though of (by convention) as a
"datatyping property" (also referred to as "interpretation property"
by TimBL).
If <SUG2> turns out to be acceptable, the next thing I would suggest
to nail down is the nature of literals. A further proposal from my
side would therefore be
<SUG3>: the interpretation of each literal symbol is fixed
and is determined by its textual contents.
4 EXAMPLES
----------
Alright, enough babble is enough. Below, I've picked some examples
that illustrate several use cases of datatyping.
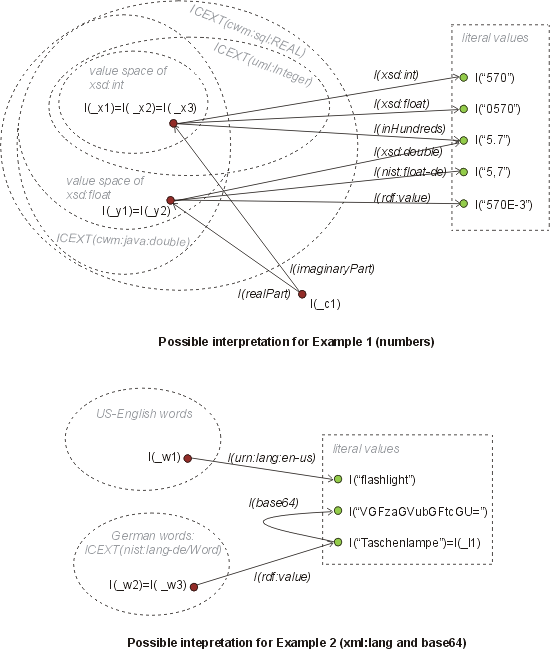
Example 1: numbers
------------------
This first example illustrates the use of value spaces and "datatyping
properties":
_x1 xsd:int "570"
_x2 xsd:float "0570"
_x3 rdf:type uml:Integer
_x3 inHundreds "5.7"
_y1 rdf:type cwm:java:double
_y1 rdf:value "5.7"
_y2 rdf:type cwm:sql:REAL
_y2 rdf:value "570E-3"
_y2 nist:float-de "5,7"
_c1 realPart _x1
_c1 imaginaryPart _y2
A possible interpretation for the above set of statements is shown in
the figure below (see Appendix). In the figure, the red and green dots
represent entities in the domain of discourse (resources and literal
values). The arcs connecting the dots represent elements of the
corresponding property extensions. For instance, the arc labeled with
I(xsd:int) in the figure represents pair <I(_x1),I("570")> contained
in IEXT(I(xsd:int)). The subdivision into lexical spaces is omitted
for clarity (recall that each lexical space is a set of literal
values).
For argument's sake, assume that xsd:int, xsd:float are properties
that map between values spaces and lexical spaces (must not be that
way). The domains of these properties are the value spaces of 64-bit
integers and 64-bit floats, as defined in [XSD]. In contrast,
uml:Integer, cwm:java:double, and cwm:sql:REAL denote "classes", i.e.
the value spaces themselves.
In the interpretation shown in the figure, bNodes _x1,_x2,_x3 map to
the same resource in the domain of discourse, as do _y1 and _y2.
Property "inHundreds" illustrates a datatyping property that
associates the value spaces of UML Integers with a lexical
representation in which the number is represented by a different
lexical token (this token, by the way, looks more like a proper real
number!). If the domain of inHundreds is defined to be an integer
value space, than the statement (_x3, rdf:type, uml:Integer) seems
like an overspecification. However, such overspecification may still
be of some limited use for applications that just understand
uml:Integer and know nothing about the property inHundreds.
Notice that the property rdf:value is used to map literal value "5.7"
to a double-precision number _y1 instead of using some special
"datatyping property". Such approach seems possible when we assume
that there exists some "default" datatyping mapping for a certain
datatype. Such "default" mapping may be defined by the value-space
class (like cwm:java:double) in a schema. In the above example the
"default" datatyping mapping for cwm:java:double may correspond to the
mapping induced by say xsd:double. In turn, the property/mapping
xsd:double is defined pseudo-axiomatically in [XSD].
The complex number _c1 is represented using two real numbers.
Example 2: xml:lang and base64
------------------------------
_w1 urn:lang:en-us "flashlight"
_w2 rdf:type nist:lang-de/Word
_w2 rdf:value _l1
_l1 base64 "VGFzaGVubGFtcGU="
_w3 urn:lang:de "Taschenlampe"
A possible interpretation for the above statements are shown in the
figure. Notice that similarly to the distinction between datatypes and
datatyping, language tagging can be realized using properties or using
classes. Analogously, rdf:value is used in the example using the
assumption that some schema describes what the default type mapping is
for the class nist:lang-de/Word (alternatively, this information can
be considered "built-in").
Furthermore, note that in this example the literal value
"Taschenlampe" appears as a sort of a "subject of an interpreted
statement" even if it is not used as a subject node in a graph or at a
subject position in the Ntriple notation (this supports Pat's point
that allowing literal symbols in subjects is fine).
Example 3: units
----------------
Well, once we have a way to represent numbers, representing units may
be a less of a pain. Again, several alternatives are possible, for
example:
_x1 weight _x2
_x2 rdf:type WeightInPounds
_x2 numeric _x3
_x3 xsd:int "5"
OR
_x1 weightInPounds _x2
_x2 numeric _x3
_x3 rdf:type uml:Integer
_x3 rdf:value "5"
etc. The property "numeric" is used to relate the concept of "5
pounds" to a numeric data value.
Example 4: constants
--------------------
Some datatypes define fixed constants. For example, [UML] defines a
concept of an infinitely large integer. Instantiation (rdf:type) could
be used for this purpose as in
uml-dt:* rdf:type uml-dt:UnlimitedInteger
(as appears in
http://www-db.stanford.edu/~melnik/rdf/uml/uml-datatypes-20000507.rdf)
CONCLUSION
----------
The purpose of the examples above is to illustrate how datatyping may
be introduces and interpreted semantically by utilizing value spaces,
lexical spaces and mappings between them, and to support the
suggestions <SUG2>, <SUG1>, and <SUG3>.
I do recognize that datatyping remains a hard issue. Specifically, it
is not clear how structured or derived datatypes defined say by means
of [XSD] can be used meaningfully in RDF. Another stumbling block in
datatyping are parameterized datatypes, or templates, like CHAR(20) in
SQL. A basic problem is that enumerating all character datatypes
CHAR(N) is impractical. After reading [UML,CWM] it is still unclear to
me how templates can be interpreted semantically.
Regarding the model theory for datatyping, I don't think that
datatyping needs some special treatment if we go along with <SUG2> and
<SUG3>. Of course, it would be fine to introduce a "shortcut" notation
for datatyping in the model theory if necessary, just like ICEXT is
defined as a shortcut in the MT draft.
For now, that's all folks!
Sergey
Attachments
- image/gif attachment: rdf-literals3.gif
Received on Wednesday, 24 October 2001 23:19:29 UTC