- From: Katrien Depuydt <Katrien.Depuydt@ivdnt.org>
- Date: Tue, 9 Mar 2021 10:52:21 +0000
- To: Declerck Dfki <declerck@dfki.de>, Christian Chiarcos <christian.chiarcos@web.de>, Fahad Khan <anasfkhan81@gmail.com>
- CC: public-ontolex <public-ontolex@w3.org>, Valeria Quochi <vquochi@gmail.com>
- Message-ID: <33da53bd4de24d10b4cb920ed5ad1076@ivdnt.org>
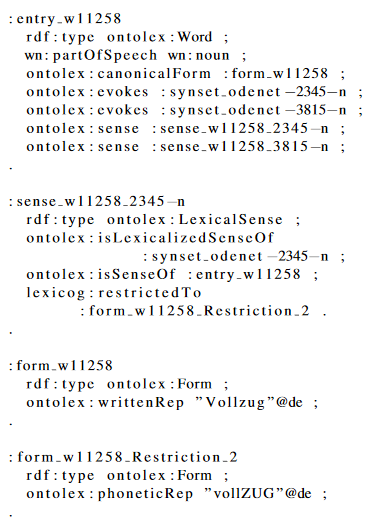
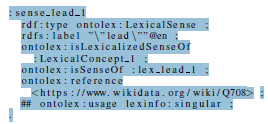
Hi Fahad, Our approach is similar to what Christian has suggested below, each distinct variant form gets its own form resource. Kind regards, Katrien Katrien Depuydt Senior onderzoeker/taalkundige Senior researcher/linguist Tel.: +31 71 527 24 79 Mob.: +31 6 53627318 Instituut voor de Nederlandse Taal / Dutch Language Institute Postbus 9500 / P.O. Box 9500 2300 RA Leiden / NL 2300 RA Leiden Bezoekadres/address: Rapenburg 61 2311 GJ Leiden Van: Thierry Declerck <declerck@dfki.de> Verzonden: maandag 8 maart 2021 19:43 Aan: Christian Chiarcos <christian.chiarcos@web.de>; Fahad Khan <anasfkhan81@gmail.com> CC: public-ontolex <public-ontolex@w3.org>; Valeria Quochi <vquochi@gmail.com> Onderwerp: Re: FRaC Faliscan language Example Dear All, Thanks for the interesting discussion. Just to mention that I had similar issues: with Forms that have the same writtenRep, the same case/gender, but different pronunication of different stress (https://de.wiktionary.org/wiki/Vollzug -- Wiktionary has 2 entries for this example). I played with this kind of representation (making use of Lexicog: [cid:image001.png@01D714DA.A8D64640] Similar with "lead" in English, with two pronunciations, where I tried something a bit different, with two entries and two forms: [cid:image002.png@01D714DA.A8D64640] [cid:image003.png@01D714DA.A8D64640] Well I do not know if this fits in this thread. Cheers Thierry Am 08.03.2021 um 18:42 schrieb Christian Chiarcos: Am Mo., 8. März 2021 um 18:07 Uhr schrieb Fahad Khan <anasfkhan81@gmail.com<mailto:anasfkhan81@gmail.com>>: Dear Christian, all, Il giorno lun 8 mar 2021 alle ore 16:54 Christian Chiarcos <christian.chiarcos@web.de<mailto:christian.chiarcos@web.de>> ha scritto: Hi Fahad, dear all, Am Mo., 8. März 2021 um 12:17 Uhr schrieb Fahad Khan <anasfkhan81@gmail.com<mailto:anasfkhan81@gmail.com>>: Hi Everyone, I have been working on modelling an entry from a lexicon currently being compiled as part of an Italian project on Italic languages and I think it potentially shows some limitations in the current ontolex/FRaC approach. I would like to discuss this at the next telco but I will give a description here in order to get some feedback from the list too. In the example in question we have a Faliscan word, ekupetaris, which has different attested representations for the same form (or same morphological variant). That is, the masculine, nominative, singular form has been attested in the following written variants: "ECVPETARIS", "EQUPETARS", "ekupetaris", "ekvopetaris", "ekvopetars", "epetaris", "eppetaris". Each of these written variants has at least one attestation in some inscription. In the case of "ekupetaris" there are four different attestations; the others have one apiece. According to the ontolex-lemon model these are all written representations of the same Form element (the masculine, nominative, singular form of the noun). You seem to assume that the same features for the same lexical representation lead to exactly one Form. I don't think this is required. In fact, we can have different forms with identical features but differences in usage. Think of English "has" and "hath", which probably should be two forms. Despite both being 3.sg.ind.prs, they are not interchangeable. Looking at your examples, these forms also differ *phonologically*, not just orthographically. There are at least five phonologically differentiable forms here: "ECVPETARIS", "ekupetaris", "EQUPETARS", "ekvopetaris", "ekvopetars", "epetaris", "eppetaris" Everything else is just orthography. If your resource *decides* to define forms as phonologically-based (this is not required), these would probably be it. However, this is pre-standardized writing, and you could go as far as to distinguish every attested form simply because you can *never* be certain whether there really are no phonological differences (epe- vs. eppe- may be a difference, for example). The ontolex guidelines are seemingly clear on this: that Form should be used only for morphological or grammatical variation (which afaik is usually defined as morphosyntactic variation). To underline this, the example of "privacy" is given as a Form with two different phonetic representations (Lexicon Model for Ontologies: Community Report, 10 May 2016 (w3.org)<https://www.w3.org/2016/05/ontolex/#forms>). If you are suggesting that we could consider other kinds of relevant variation (e.g., representing phonological differences) in defining forms then the guidelines should probably be adjusted (as GIlles mail and other comments I've heard would seem to suggest there is at least a potential ambiguity in the current wording). Indeed the solution which you suggest in which each variant would be a separate Form, so that we would have seven forms (each of which is marked as singular, masculine, nominative) with their own separate attestations and written representations is the one which we had originally wanted to use before checking what the guidelines said. (In addition instance the OED seems to use Form in the broader sense which you mean Christian, rather than the one in the guidelines) Another possibility could be the creation of a new class (in FRaC), something like AttestedRepresentation which is also a FRaC observable with associated properties attestedRep stringValue such that writtenRep is equivalent to attestedRep o stringValue. I would rather avoid that. For many reasons: I'm not sure we can axiomatize the values of datatype properties in this way. It would create something nearly identical with Attestation, leading to a lot of confusion among users of FrAC. If this is an observable, this would mean that it can have Attestations on its own right -- what is an Attestation of an AttestationRep? It would introduce at least two new properties and one new class (as opposed to just one reifiable vartrans property that uses the same construction template as we previously used for lexical relations), and it would be *highly specific* for a use case relevant for epigraphy -- but not much beyond that (I might be wrong on that one). For a vartrans relation between forms, I can see other uses (e.g., systematic mappings between related forms of different lexemes, e.g., from different languages). For the attestationRepresentation, I'm not sure these do exist. The idea would be for AttestedRepresentation to be a reification of a writtenRep If so, we should probably just reify writtenRep. I can see other uses for that, but it would be a major change to the OntoLex core. And one might wonder what the difference to Form is. I'm actually in favor of rewording the OntoLex spec to make that more explicit. It meets a demand, it seems to follow current practice and (in my reading) it doesn't contradict anything in the spec. The suggested change is minor: "Different forms are used to express different morphological forms of the entry." => "Different forms of the same entry are used to express forms that differ in their (morphological or phonological) structure." Note that "differ in their (phonological) structure" is sufficiently general to admit multiple phonologicalReps for BE and AE at the same form -- if a data provider asserts that these do not differ in their phonological *structure*, but just in their articulation. (All phonemes are 1:1 mappable.) But if data providers *want to actually assert* that these are different in structure (in this case, few people would -- unless you go into dialectology, where these differences are the subject of investigation), they would be able to do so. Personally, I would prefer to keep OntoLex sufficiently flexible to not systematically rule out entire fields of research ;) Best, Christian which we could predicate additional information of, in particular via the use of an Attestation. The Attestation of an AttestationRep would be a text (or locus) in which a form is spelled/written in a certain way. For instance, say we wanted to add information to a lexicon about the first attestation of the spelling of the word colour as "color" to check whether the American or the English spelling was the prior one. Currently we can't do this. Best, Christian Cheers Fahad -- Thierry Declerck Senior Consultant at DFKI GmbH, Multilinguality and Language Technology Stuhlsatzenhausweg, 3 D-66123 Saarbruecken Phone: +49 681 / 857 75-53 58 Fax: +49 681 / 857 75-53 38 email: declerck@dfki.de<mailto:declerck@dfki.de> ------------------------------------------------------------- Deutsches Forschungszentrum für Künstliche Intelligenz GmbH Trippstadter Strasse 122, D-67663 Kaiserslautern, Germany Geschäftsführung: Prof. Dr. Antonio Krüger Vorsitzender des Aufsichtsrats: Dr. Gabriël Clemens Amtsgericht Kaiserslautern, HRB 2313 ------------------------------------------------------------- ________________________________ Aan dit bericht kunnen geen rechten worden ontleend. Het bericht is alleen bestemd voor de geadresseerde. Indien het bericht niet voor u is bestemd, verzoeken wij u dit aan ons te melden en het bericht te verwijderen. This message shall not constitute any obligations. This message is intended solely for the addressee. If you have received this message in error, please inform us and delete the message. ________________________________
Attachments
- image/png attachment: image001.png
- image/png attachment: image002.png
- image/png attachment: image003.png

Received on Tuesday, 9 March 2021 10:52:41 UTC