- From: Ketan Singh <singh.ketan7@gmail.com>
- Date: Mon, 24 Sep 2012 07:14:33 +0530
- To: François REMY <fremycompany_pub@yahoo.fr>
- Cc: www-style@w3.org
- Message-ID: <CAH8sMT_Z1M4hQ47Na25uAX-hYvUNMiSMDbufraQYvy-pVVFh0w@mail.gmail.com>
Thanks a lot for the link and the explanation. I'll go through it.
On Mon, Sep 24, 2012 at 2:33 AM, François REMY <fremycompany_pub@yahoo.fr>wrote:
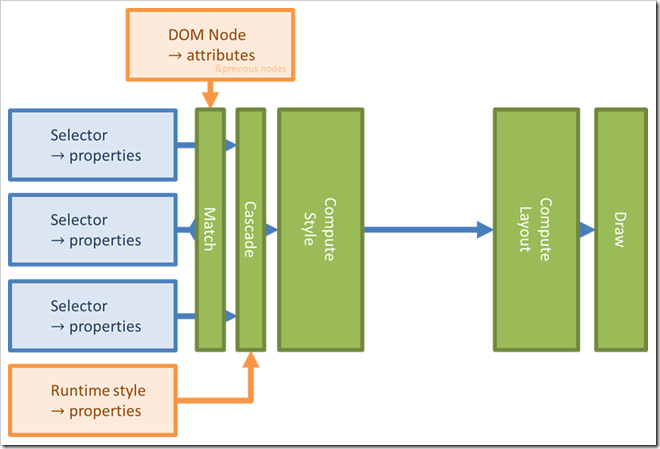
> Albeit incomplete (and yet not beginner-oriented), [1]<http://taligarsiel.com/Projects/howbrowserswork1.htm#Render_tree_construction>is a good document to understand how browsers work.
>
> However, in this specific case, a simpler explaination may be sufficient.
> Here’s how CSS work:
>
> [image: image]
>
> *MATCH*:
>
> For each node of your HTML document, the browser check the CSS rules that
> matches the element (like “span” or “div > span” or ...) and collect them
> all in a list where they are sorted by priority (“#theSpan” will be first
> and “div > span” second). After that, the ‘runtimeStyle’ which comes from
> scripts and the content of the ‘style’ attribute are added to the list in
> first position.
>
> *CASCADE*:
>
> For each property in CSS, the value of the property is selected from the
> first rule from the matched ones which defined its value, or is either
> ‘initial’ or ‘inherit’ if none of them defines it. At this point, the
> “currentStyle” of the element has been computed. As a side note, only
> Internet Explorer exposes the ‘current style’ of an element to JavaScript.
>
> *COMPUTE STYLE*:
>
> At this point, ‘inherit’ and functions are replaced by their value (when
> it’s possible). The style is made more usable for the underlying layout
> engine. This is the first time that any sense is made from the actual value
> of the properties. If we were to support a ‘css-ignore’ property, it would
> be taken in consideration now. However, there’s no way to tell from where
> the value of any property originate so we would need to return to the match
> phase to honnor ‘css-ignore’. This is not strictly impossible, but is not
> desirable as I’ll explain later.
>
> *LAYOUT*:
>
> The values are translated into real “pixel” values, the position of
> elements on the screen are computed.
>
> *DRAW:*
>
> The screen is drawn via CPU/GPU and you see the end result on the screen.
>
> ------------------------------
>
> *Why is it bad to support css-ignore?*
>
> If you specify ‘css-ignore: external’ in an external CSS stylesheet, when
> you’ll return to the matching phase, that rule will not be matched anymore.
> That means that ‘css-ignore’ will now default to ‘initial’ which means ‘do
> not ignore anything’. So, you’ve to restart matching everything including
> external stylesheets. Which will lead to ‘css-ignore: external’. In fact,
> you just made an infinite loop. But, even if you find a solution to avoid
> to loop infinitely, you just made the browser throw a lot of work and as
> such waste a lot of time, which is really bad.
>
> The only good solution to this problem is to know *before* the matching
> phase that we don’t need to perform the matching. This is exactly what Web
> Components (will) offer you. However, in your case, you need even more
> because you probably need to have an HTML compatibility mode for your
> Word-generated HTML. If this is true, that means you need a seamless
> iframe <http://benvinegar.github.com/seamless-talk/#/>.
>
> As a rule of thumb: a CSS Property should not interact with selector
> matching. The only known selector which depends on CSS properties is
> :hover. Try element:hover { display: none } and move your mouse on the
> matched element. Do you see how buggy this is? Because ‘:hover’ is a really
> strong use case, it was not possible for the W3C to do anything else than
> to support it, even if it was known ‘bad’. Also, they are mitigations that
> makes ‘:hover’ not so bad, actually. But that’s a bit too long to explain.
>
> ------------------------------
>
> Best regards,
> François
>
Attachments
- image/png attachment: image_7_.png
Received on Monday, 24 September 2012 01:45:00 UTC