- From: Young,Jeff (OR) <jyoung@oclc.org>
- Date: Fri, 21 Jun 2013 15:47:33 +0000
- To: Stephane Fellah <fellahst@gmail.com>, Linked Data community <public-lod@w3.org>
- Message-ID: <785e14822e75492ba007e579cd3d90ab@BY2PR06MB204.namprd06.prod.outlook.com>
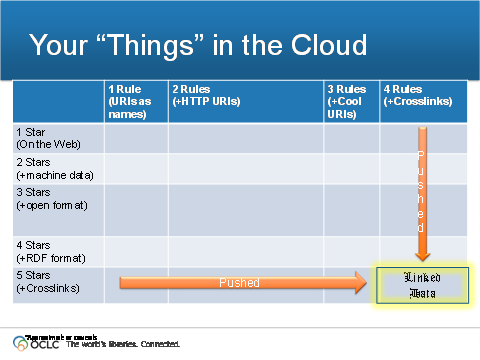
I created ugly slide awhile back to help illustrate TimBL's 4 rules and 5 stars and "Linked Data" into relative perspective. Using this table structure, you can encourage people plot the name of their dataset onto the grid and then encourage them to push it towards the lower right corner. Jeff [cid:image002.png@01CE6E75.1B6361D0] From: Stephane Fellah [mailto:fellahst@gmail.com] Sent: Friday, June 21, 2013 11:25 AM To: Linked Data community Subject: Fwd: Linked Data discussions require better communication Kingsley, Context reminder: I am trying to clarify the definition of Linked Data and argue for the need of URIs, HTTP and RDF Model to create Linked Data (as defined by TBL). I am trying to illustrate what is Linked Data and what is not Lined Data through the use of examples. I also trying to pinpoint the dangers of drifting away from this definition based on my personal experience. On Thu, Jun 20, 2013 at 3:54 PM, Kingsley Idehen <kidehen@openlinksw.com<mailto:kidehen@openlinksw.com>> wrote: On 6/20/13 2:16 PM, Stephane Fellah wrote: Kingsley, On Thu, Jun 20, 2013 at 1:28 PM, Kingsley Idehen <kidehen@openlinksw.com<mailto:kidehen@openlinksw.com>> wrote: On 6/20/13 12:50 PM, Stephane Fellah wrote: Hi, I agree with Luca's viewpoint. The W3C standard RDF model (a.k.a triple model) is one of most fundamental piece of the technology stack defining Linked Data (along with URIs and HTTP). I am not disputing that point. Here's what in dispute, and the topic of debate to me: the misconception that you MUST know anything about RDF en route to creating and publishing Linked Data. RDF is an optional implementation detail with a particular outcome in mind i.e., the ability for humans and machines to understand the entity relationship semantics that constitute the Linked Data. Can you provide some examples to clarify your point here? Do you consider CSV files as Linked Data ? Of course you can produce Linked Data content via a CSV file [1][2]. You have not really answered my question. My question is: Do you consider CSV file as Linked Data ? Your answer should hopefully be NO (it's just data without semantic). I am not asking if CSV can be transformed to Linked Data. Of course it can ! Any data can be transformed to linked data. The point I am trying to make is that CSV files are not by nature Linked Data. To perform the conversion to Linked Data, we could use the following steps: 1) Define a unique URI for each row (Subject) . 2) For each column, define a URI for its semantic (Property). 3) For each cell value, define a literal or URI (in case of a reference to another resource). 4) Make the data accessible through HTTP. The end results is a set of triples that represent a directed labeled graph (RDF Model). I just demonstrated to you that I use the RDF Model (Directed labeled graph composed of triples with URIs). Do you consider RDBMS Tables ( using primary keys of the database as identifiers) as Linked data ? Nice that you asked, I can use RDBMS keys to demonstrate different kinds of Linked Data to you, for sure [3][4][5][6]. Again, you dodged my question by showing me how you convert RDBMS to Linked Data. Again the steps taken to realize your example are similar to the one I described for CSV. The result is a directed label graph (RDF Model). The original RDBMS table are not Linked Data, they are structured data without any semantic. The mapping to URIs and the decomposition of the E-R model to a directed label graph using URIs means that you are using the RDF Model. Turning RDBMS into XML document without URIs (as for example in Geographic Markup Language) is not Linked Data, as the tags have not well defined semantics (XML is actually semi-structured data) and entities are not decomposed into their simplest form (triples). Do you consider XML documents using XPointer and XLink as Linked Data (like in Geographic Markup Language GML) ? By now, you should understand that non of these formats have anything to do with RDF. Exactly ! That was my point: CSV, RDBMS and XML documents have nothing to do with RDF and THUS ARE NOT LINKED DATA. They are just "dumb" data (unstructured (documents), semi-structured (XML for example), structured (RDBMS, Images etc) ) without any semantic, making it impossible for machine to process automatically because you have to write code to interpret the semantic of the information they convey. Do you consider XML documents using local identifier xml:id as Linked Data ? I personally do not consider them as Linked Data because they do not adhere to the RDF model (meaning I cannot harvest them as a set of triples using URIs). If you disagree with my point, then we should have different terminologies to distinguish RDF compliant data versus the rest. Circa. 2013, RDF isn't bound to any data serialization format (it never really was). RDF isn't bound to any concrete syntax for graphical expression of structured data. It has an abstract syntax that outlines the grammar to be used when representing entity relationships using triples (or 3-tuples). The greatest feature of RDF is that it is self-describing, described, and understandable by an RDF processor sucking in RDF's own vocabulary [7]. You didn't answer my question. You state something that everyone already knows in this mailing list. The whole point of RDF model is to decompose any piece of data into its simplest and most atomic form (the triple form) and to convey meanings by the use of unique identifiers (URIs). The triple model and directed label graph is not the invention of RDF (as you stated in one of your previous message). Similarly unique identifiers is not the invention of URIs. However it is the model used for Linked Data and the W3C standard that defines it is the RDF model specification. Making the claim that Linked data does not need RDF is just confusing, misleading, and is counter productive for the community. I think it is important to make understand the community that Linked Data can be serialized into different representations (Turtle, RDF/XML, JSON-LD, N3, NTriples, TrigG, and any future formats) , as long as they are isomorphic to RDF model (meaning data can be converted to a set of triples and identifiers are based on URIs). I really don't believe that I am disputing this point. Neither do I believe the point (above) is new to anyone on this list. If the data are NOT convertible to RDF model, I do not consider it as Linked Data. And that assertion is inaccurate. It is also indefensible. The World Wide Web as it already exists is full of Linked Data for which RDF processors may or may not exist. It functions, humans and programs understand the "LinksTo" relation etc.. That's why it works and scales the way it does. That is where I differ with you: The World Wide Web as it already exists is full of "Data", not "Linked Data". Well, we just disagree. I don't know what you think HTML represents, or why you feel documents aren't entities worthy of ambiguous denotation or structured-machine-readable description etc. HTML is certainly not Linked Data (contents and hyperlinks don't have explicit semantic) and machine cannot interpret the information that the document conveys without extra additional information (such as RDFa, GRDDL). In my eyes, the World Wide Web is just medium with evolving resolution. As it evolves the resolution of its constituency (its webby entity relations) simply increases. RDF simply provides a way for us (via RDF processors) to increase the resolution of web-like structured data (which includes the mesh we know as the World Wide Web). I agree with this. To become Linked Data they need to be converted to RDF Model, meaIning be compliant with triple model and uses URIs and HTTP to be linkable. "RDF Model" doesn't become meaningful by will. You sentence about doesn't mention a single defining characteristic of RDF. Doesn't HTML leverage HTTP and URIs? Please read again my sentence. It defines three characteristics of RDF : the triple model, use of URIs and HTTP. I am not sure why you asking about HTML ? Do you consider HTML as Linked Data ? CSV files, XML with local identifier files, Database tables are NOT linked data until they adhere to the Triple Model and uses URI for identification (thus being compliant with the RDF Model). You make Linked Data by making a commitment to the following during the act of creating and publishing web-like structured data: 1. dereferencable URIs as the denotation mechanism for entities being described 2. a data model (basic entity relationship graph *OR* enhanced RDF variant) for structured data representation 3. actual document content comprised of statements that represent entity relationships (and if using RDF said relationship semantics become *explicit* rather than *implicit*). I do not agree with point 2. There is only one model for Linked Data: Directed Labeled Graph with use of URIs to denote the meaning of resources and properties. Any other model E-R, Tuples model, binary model (images) should be decomposed into its most atomic form (triple forms) to become Linked data. Failure to do so will prevent interoperability by creating new islands of interoperability based on alternative models (see my anecdote below). I don't know what you mean by "Enhanced RDF Variant" . Directed Labeled Graph is the simplest model that can truly scale. Guess what, even though the World Wide Web is dominated by HTML content, it was bootstrapped on the back of a draconian mandate that everything MUST be interpretable as HTML. Ironically, DBpedia most powerful deliverable was the use of HTML to expose the concept of Linked Data. We stuck RDF/XML and other formats in the footer pages of said documents. To make the system works, you need some set of standards on which everyone agree: HTTP, URIs, RDF are fundamental to Linked Data. URIs and web-liked structured data representation are fundamental to Linked Data. RDF is fundamental to Blogic. RDF is fundamental to build the "Global Linked Data Graph" (Directed Labeled Graph model based on URIs). Inferencing, ontologies, SPARQL, BLogic, are just value-adds capabilities on top of Linked Data. You do not need BLogic for Linked Data. If you didn't need Blogic, then why bother giving entities unambiguous names. Why bother having such a concept? Why bother with relationship roles like Subject, Predicate, and Object? I mean, we can just rely on the mysterious magic of the literals "RDF" and poof! All is understood, on this Giant Global (entity relationship) Graph of Linked Data, by humans and machines. Unique identifier has nothing to do with blogic. Unique identifier is used to denote the meaning of something (in case of RDF a concept). Unique identifiers are used in many other systems (telephone numbers, social security number, ISBN numbers) and are fundamental to have a scalable system. It has nothing to do with BLogic. BLogic (or any other form of logics) is used to perform interpretation of the information. It is orthogonal to RDF model. Saying we do not need RDF model for Linked Data is like saying we do not need URL or HTTP for the web of documents. Again, here is what I am saying: You don't need to know anything about RDF to create and publish Linked Data. Please read my words, don't react to them. Based on my comments, I disagree with you on this point. Clearly you do, but at some point, you will realize what I am trying to unveil here. By the way, I wasn't born with a *unique* understanding of these matters, I came to understand data representation, access, integration, and management over many years of learning from others, across many scenarios and projects. I have been working on interoperability issues over the last 15 years (mainly in geospatial domain). I have been advocating the use of RDF for the last 13 years after realizing that it was the only truly scalable model that could solve the data integration problem. It has also been many years of frustration trying to convince that RDF model was the right model for data integration. To close this discussion, I wanted to share with you an anecdote to illustrate the risk of fragmentation of the web when introducing alternative models (as David Booth mentioned in his excellent writing at the beginning of this thread) and the importance to stick to our guns with the need of RDF Model for Linked Data. Back in 2000, I started to be involved in Open Geopatial Consortium. The goal of the consortium was to define a set of standards to enable interoperability and integration of geospatial information and services to fullfill the vision of "Geospatial Web". Geographic Markup Language (GML) was proposed by one of the member of the consortium. GML 1.0 was based on RDF. It was a brillant idea and I gave my full support to the effort. Unfortunately, 1 year later, GML 2.0 switched from RDF to XML schema (XML and XML schema were the buzzwords at this time). GML 2.0 took the RDF model and duplicated it using XML Schema. They used different terms (Feature for Resource and Feature Property for RDF Property). Everyone was amazed by the expressiveness of the model and they started to describe every geospatial domain in GML (the last spec of GML 3.0 has more than 600 pages now). The reason of the switch invoked by the author of GML was because RDFS was not expressive enough to convey restrictions on data. I was pointing him out to DAML+OIL effort (which was still in its infancy at the time), but because it's lack of maturity, the consortium decided to use XML Schema. I spent many years trying to convince people that was a mistake and to go back to RDF model (which enforce the use of URIs) and showing how we could express GML semantics with OWL. I hit a wall. GML became overly complicated overtime (use of substitution, schema profiles, lack of tools). GML just focus on structure of the data, not on their semantic. GML was not machine interpretable. I just got a hard time to make them understand that human readable tags do not have semantic. Implementing each profile of GML has become a sisyphean coding work to encode the semantic of each new GML profile (CityML, SensorML, etc...) The end results of that is that OGC has created its own island of interoperabilty and cannot be integrated easily with the Linked Data without performing some mapping to URIs. 13 years of effort of modeling has been captured in XML schema focusing mainly on structured, syntax and validation. The formal semantic of all these models is buried in a 600 pages documents and produced brittle systems due the misinterpretation of specification by coders. Large investment been done by many companies to implement GML, but the dream of realizing the geospatial web is far to be fullfilled and all the semantic still remain to be encoded. The irony of the story is that OGC has produced GeoSPARQL but data are encoded in GML. I am glad to see that after all these years, Linked Data is starting to get at last some traction. The morale of this anecdote is that we have to be very careful not to confuse the community and break apart with some alternative 'fancy' solutions or definitions that are not well thought. Other the last 13 years I have been a strong believer of the Semantic Web and times has proved again and again that it is the best solution to solve integration problems we have today. I urge you to keep the original definition of Linked Data, as defined by TBL, which mention the need of RDF model and not trying to come out with other interpretations that open the door for fracturing the vision of the Semantic Web, Best regards Stephane Fellah In my world, every day is a new opportunity to discover and learn something new. I am only afraid of the day when that doesn't happen! Links: 1. http://lists.w3.org/Archives/Public/public-lod/2013Jun/0083.html -- post that started this thread (note: it includes links to a CSV Browser) 2. http://bit.ly/18axeTP -- CSV Browser link that handles SPARQL-FED query results returned in CSV format 3. http://bit.ly/18pGTFd -- green links demonstrating Linked Data in a SQL RDBMS silo (a silo because the URNs derived from the DBMS keys only resolve to relational tables based entity descriptions, locally i.e., I can't copy and paste the URIs to an application outside the DBMS e.g. a Web Browser) 4. http://bit.ly/11Brjz7 -- a Relation based on an relational table remapped to an entity relationship model (e.g., EAV) this is deliberately presented as quad so that the sources Tables aid understand of the context flip 5. http://bit.ly/13fnIbr -- introducing blue links, HTTP URIs replacing those DBMS specific URNs with local scope i.e., Web-scale super keys that resolve to descriptions from anywhere via copy and past 6. http://demo.openlinksw.com/OracleHR/employees/EMPLOYEE_ID/101#this -- example of a Linked Data URI that you can click on en route to seeing HTTP URI de-silo-fication in action combined with Linked Data (RDF magic comes later when I seek to merge disparate data across heterogeneous data sources) 7. http://bit.ly/147HINl -- RDF described in RDF and presented using a Linked Data Browser page 8. http://dbpedia.org/resource/Linked_data -- go to the page footer to see the variety of support formats (btw -- RDF appears to be missing from the abstract, at this point in time) 9. http://bit.ly/15ZxzHo -- Vapor (Linked Data principles conformance verifier) report for the DBpedia URI above (also demonstrating the role formats play in this realm distinct from abstract syntax) . Kingsley Kingsley Sincerely Stephane Fellah Stephane On Thu, Jun 20, 2013 at 11:45 AM, Luca Matteis <lmatteis@gmail.com<mailto:lmatteis@gmail.com>> wrote: On Thu, Jun 20, 2013 at 5:02 PM, Melvin Carvalho <melvincarvalho@gmail.com<mailto:melvincarvalho@gmail.com>> wrote: * Restate/reflect ideas that in other posts that are troubling/puzzling and ask for confirmation or clarification. I am simply confused with the idea brought forward by Kingsley that RDF is *not* part of the definition of Linked Data. The evidence shows the contrary: the top sites that define Linked Data, such as Wikipedia, Linkeddata.org and Tim-BL's meme specifically mention RDF, for example: "It builds upon standard Web technologies such as HTTP, RDF and URIs" - http://en.wikipedia.org/wiki/Linked_data "connecting pieces of data, information, and knowledge on the Semantic Web using URIs and RDF." - http://linkeddata.org/ This is *the only thing* that I'm discussing here. Nothing else. The current *definition* of Linked Data. * Restate the actual subject and focus of the discussion; the subject line just doesn't always cut it. Again the subject line is the *definition* of the term Linked Data. More specifically whether it includes (or should include) RDF. * Do more explication with the awareness that we might be talking about two (or more!) related but separate ideas/concepts. Or we could be using the same terms but with slightly different definitions. I want to concentrate on the current definition of the Linked Data term. Why do the main sites built from the Linked Data community *strictly* describe RDF as one of the main technologies that enable Linked Data? * Define the terms inline rather than just linking out. One's interpretation of an external standard or specification could be different from someone else's, so I think it would be good to own it. I simply think RDF is part of Linked Data's definition, because of the evidence I have shown above. If this is not the case, we should discuss it as a community. If we decide that RDF is *not* part of the definition of Linked Data, we should probably remove it from all the top sites, otherwise it will create confusion for newcomers. Also we should make new Linked Data coffee mugs ;-) Luca -- Regards, Kingsley Idehen Founder & CEO OpenLink Software Company Web: http://www.openlinksw.com Personal Weblog: http://www.openlinksw.com/blog/~kidehen<http://www.openlinksw.com/blog/%7Ekidehen> Twitter/Identi.ca handle: @kidehen Google+ Profile: https://plus.google.com/112399767740508618350/about LinkedIn Profile: http://www.linkedin.com/in/kidehen -- Regards, Kingsley Idehen Founder & CEO OpenLink Software Company Web: http://www.openlinksw.com Personal Weblog: http://www.openlinksw.com/blog/~kidehen Twitter/Identi.ca handle: @kidehen Google+ Profile: https://plus.google.com/112399767740508618350/about LinkedIn Profile: http://www.linkedin.com/in/kidehen
Attachments
- application/octet-stream attachment: image001.emz
- image/png attachment: image002.png
- application/octet-stream attachment: oledata.mso
Received on Friday, 21 June 2013 15:48:22 UTC