- From: <jrmt@almas.co.jp>
- Date: Sun, 22 Nov 2015 10:59:12 +0900
- To: "'Badral S.'" <badral@bolorsoft.com>, "'Greg Eck'" <greck@postone.net>, <public-i18n-mongolian@w3.org>
- Message-ID: <000001d124c9$62b090a0$2811b1e0$@almas.co.jp>
Hi Badral, >We should not use any FVSs for YI diphthongs. It makes not only difficult the input (4 times typing for two characters!) I advise you to solve the issue of more one FVS1 between <U+1836_YA> and <U+1822_I> in your Input method to not typing the FVS1 between <U+1836_YA> and <U+1822_I> You can automatically insert/delete the FVS1 between <U+1836_YA> and <U+1822_I>. Our Mongolian IME will eliminate almost all of the Mongolian control script like NNBSP, MVS, FVS key typing in the normal input process. All of the NNBSP, MVS, FVS will be automatically inserted when you select the word from the option list. >but decrease performance of post-processing like spell checking. The occurrence of diphthongs in Mongolian are incomparable high from just some limited number of regular YI words. This is not an issue. You can optimize your algorithm in any way. >The stems with YI are not more than 20. All words with inflections are listed in email https://lists.w3.org/Archives/Public/public-i18n-mongolian/2015OctDec/0184.html from Siqin. It is originally existing Mongolian regular words. We have no reason to force peoples to accept the regular word use irregular encoding way with extra FVS This is the big issue if we ask Users to accustom the regular writing as irregular encoding / input. You say you can tolerate this, but I think not all Mongolian in Mongolia can tolerate it. In Inner Mongolia it is definitely not acceptable in almost all 5 million Mongolian. It will confuse the original education theory and system in Inner Mongolia. It will cause big damage to Mongolian culture inhibition process. Please consider this situation. This is the reason why I am spending so many time and efforts to change this encoding in the standards. Even it is already written into China National Standards GB26226-2010. It is unacceptable to almost all of Mongolian In Inner Mongolia except a small group of linguists. Maybe the group of linguists just easily compromise to accept the opinion of Mongolian linguists on this point, not totally recognized its damage and harm. Please pickup all of the related articles and interview documents in previous mail. All of them is supporting this point. As I know this encoding changes had not included in the ISO 10646 proposal until 1998. I do not know how it had been included in the standard proposal, and in the MGWBM book of professor Quejingzhabu. But it is just changed the code not changed the name, it is a little bit unbelievable. Jirimutu =============================================================== Almas Inc. 101-0021 601 Nitto-Bldg, 6-15-11, Soto-Kanda, Chiyoda-ku, Tokyo E-Mail: <mailto:jrmt@almas.co.jp> jrmt@almas.co.jp Mobile : 090-6174-6115 Phone : 03-5688-2081, Fax : 03-5688-2082 <http://www.almas.co.jp/> http://www.almas.co.jp/ <http://www.compiere-japan.com/> http://www.compiere-japan.com/ <http://www.mongolfont.com/> http://www.mongolfont.com/ --------------------------------------------------------------- Inner Mongolia Delehi Information Technology Co. Ltd. 010010 13th floor of Uiles Hotel, No 89 XinHua east street XinCheng District, Hohhot, Inner Mongolia Mail: <mailto:jirimutu@delehi.com> jirimutu@delehi.com Mobile:18647152148 Phone: +86-471-6661969, Ofiice: +86-471-6661995 <http://www.delehi.com/> http://www.delehi.com/ =============================================================== From: Badral S. [mailto:badral@bolorsoft.com] Sent: Saturday, November 21, 2015 7:44 PM To: jrmt@almas.co.jp; 'Greg Eck' <greck@postone.net>; public-i18n-mongolian@w3.org Subject: Re: Two Final Threads - Diphthongs / Final glyph checks Hi Greg and Jirimutu, We should not use any FVSs for YI diphthongs. It makes not only difficult the input (4 times typing for two characters!) but decrease performance of post-processing like spell checking. The occurrence of diphthongs in Mongolian are incomparable high from just some limited number of regular YI words. The stems with YI are not more than 20. All words with inflections are listed in email https://lists.w3.org/Archives/Public/public-i18n-mongolian/2015OctDec/0184.html from Siqin. The arguments of Jirimutu are completely solvable by OT rules. They are already solved in Mongolianscript font. Badral On 21.11.2015 05:06, jrmt@almas.co.jp <mailto:jrmt@almas.co.jp> wrote: Hi Greg >But could I ask Jirimutu – is this what you are proposing that ligature sequence <U+1836><U+1822> be encoded as one glyph? >This would be typed as code-point U+1836 plus one code-point U+180C? No. It is not my proposal meaning. The medial form should always be <U+1836><U+1822> exactly. No extra FVS after<U+1836> in anytime and any case. What I am insisting here is that we cannot sacrifice this regular medial form become any kind of irregular encoding. (Like Badral’s propose in recent mail to use FVS2 or FVS3 to over-ride, actually it is not over-riding, it is replacing beams and pillars with inferior ones) Let me clearly summarize about the <U+1836_YA> medial form encoding proposal rule entirely again. 1. We accept the current NP Variant Form encoding for <U+1836_YA> exactly. It is the is the first medial form o and is the second medial form. For the people who want to use <U+1836_YA> and <U+1822_I> to encode . 2. No extra contextual rule for if anyone want to use <U+1836_YA> and <U+1822_I> to encode it, the code should be explicitly as <U+1836_YA><FVS1><U+1822_I>. (Note: we do not agree to use contextual rule here like if <U+1836_YA> before <U+1822_I> become , because that will sacrifice The medial form should always be <U+1836><U+1822> requirements.) 3. But the followed after <U+1822_I>, <U+1825_OE>, <U+1826> in first syllable, it will become . We need to explicitly define its encoding for the people who want to use <U+1836_YA> for this long tooth. I have provided examples in previous mail like ᠦᠢᠯᠡᠰ · ᠰᠦᠢᠳᠦᠯ · ᠰᠢᠢᠳᠪᠦᠷᠢ etc. For example, ᠦᠢᠯᠡᠰ should be encoded as <U+1826_UE><U+1836_YA><FVS1><U+182F_L><U+1821_E><U+182F>. The first long tooth is the part of <U+1826_UE> and The second long tooth is <U+1836_YA><FVS1>. We cannot neglect this FVS1 too. For the people who want to use <U+1822_I> to encode . 4. The is encoded as <U+1822_I> and it will follow the <U+1822_I> character rule in here. (I have skip the details here. Please refer previous Greg’s over-riding rule definition document for <U+1822_I>) 5. But in this case the followed after <U+1822_I>, <U+1825_OE>, <U+1826> in first syllable, it will become too. We need to explicitly define its encoding for the people who want to use <U+1822_I> for this long tooth. I have provided examples in previous mail like ᠦᠢᠯᠡᠰ · ᠰᠦᠢᠳᠦᠯ · ᠰᠢᠢᠳᠪᠦᠷᠢ etc. For example, ᠦᠢᠯᠡᠰ should be encoded as <U+1826_UE><U+182F_L><U+1821_E><U+182F>. The first long tooth is the part of <U+1826_UE> and The second long tooth is <U+1822_I>. We do not need any more FVS here. All of Mongolian font should implement all of the encoding rule listed above. No exception here is for we can correctly display each other’s context in any fonts. The same thing will be listed for <U+1838_W>. Let me skip it here for simplify my mail. Thanks and Regards, Jirimutu =============================================================== Almas Inc. 101-0021 601 Nitto-Bldg, 6-15-11, Soto-Kanda, Chiyoda-ku, Tokyo E-Mail: <mailto:jrmt@almas.co.jp> jrmt@almas.co.jp Mobile : 090-6174-6115 Phone : 03-5688-2081, Fax : 03-5688-2082 <http://www.almas.co.jp/> http://www.almas.co.jp/ <http://www.compiere-japan.com/> http://www.compiere-japan.com/ <http://www.mongolfont.com/> http://www.mongolfont.com/ --------------------------------------------------------------- Inner Mongolia Delehi Information Technology Co. Ltd. 010010 13th floor of Uiles Hotel, No 89 XinHua east street XinCheng District, Hohhot, Inner Mongolia Mail: <mailto:jirimutu@delehi.com> jirimutu@delehi.com Mobile:18647152148 Phone: +86-471-6661969, Ofiice: +86-471-6661995 <http://www.delehi.com/> http://www.delehi.com/ =============================================================== From: Greg Eck [ <mailto:greck@postone.net> mailto:greck@postone.net] Sent: Saturday, November 21, 2015 12:44 AM To: <mailto:jrmt@almas.co.jp> jrmt@almas.co.jp; 'Badral S.' <mailto:badral@bolorsoft.com> <badral@bolorsoft.com>; <mailto:public-i18n-mongolian@w3.org> public-i18n-mongolian@w3.org Subject: RE: Two Final Threads - Diphthongs / Final glyph checks Hi Jirimutu, I did not have time to sort through all of the correspondence today as I leave for Hohot tomorrow. But could I ask Jirimutu – is this what you are proposing that ligature sequence <U+1836><U+1822> be encoded as one glyph? This would be typed as code-point U+1836 plus one code-point U+180C? If so, this is highly irregular and has never been done before in Mongolian. Please clarify, Greg >>>>> Sent: Friday, November 20, 2015 6:35 PM Subject: RE: Two Final Threads - Diphthongs / Final glyph checks Let explain my answer clearly. >Could you confirm that the following is our agreed upon specification for the Medial U+1836? Yes. The list provided above is exactly match our requirements. > Badral, > As I understand you are ok with this specification except that you want to add one line >Is that correct? If not, could you modify the above so that it matches your desired specification? We do not accept this over-riding in any kind of design. Because it will discard our request of the medial form should be encoded with no FVS at all. This is widely accepted spelling of Mongolian tradition for medial form of . (U+1836, U1822). we do not allow any extra FVS for YA here. This is mean, the SAYIQAN (means “recently”) should encoded without FVS for YA. It is not just one word. There is a lot kind of this words . please find the attached example list from Siqin before. I would like to remind all that it is impossible to use over-riding rule for this character. The is not irregular case. It is regular case. But for inner Mongolian peopleis irregular case. Should use FVS1 to distinguish if you like use YI to encode it. Jirimutu >>>>> -- Badral Sanlig, Software architect www.bolorsoft.com <http://www.bolorsoft.com> | www.badral.net <http://www.badral.net> Bolorsoft LLC, Selbe Khotkhon 40/4 D2, District 11, Ulaanbaatar
Attachments
- image/png attachment: image018.png
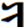
- image/png attachment: image019.png
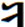
- image/jpeg attachment: image020.jpg
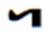
- image/jpeg attachment: image021.jpg
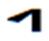
- image/png attachment: image022.png
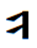
- image/jpeg attachment: image023.jpg

- image/png attachment: image024.png
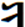
- image/jpeg attachment: image025.jpg

- image/jpeg attachment: image026.jpg

- image/png attachment: image027.png
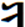
- image/png attachment: image028.png
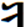
Received on Sunday, 22 November 2015 01:59:45 UTC