- From: Johnston, Patrick - Hoboken <pjohnston@wiley.com>
- Date: Tue, 19 Jan 2016 16:17:01 +0000
- To: Holger Knublauch <holger@topquadrant.com>, "public-data-shapes-wg@w3.org" <public-data-shapes-wg@w3.org>
- Message-ID: <E78A127E-4764-4009-B01E-7087870ED224@wiley.com>
Thanks for your patience, that was very helpful. I have some final comments (PJ2 below), but don’t feel obliged to answer. If you guys do want to use the tests (minus the ones that don’t pass muster), let me know.
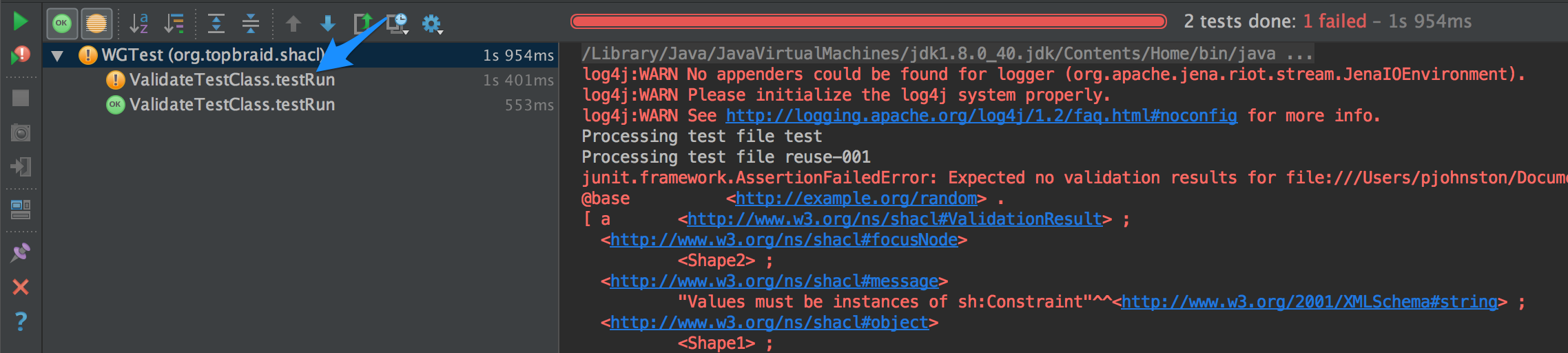
In terms of outputting the file being processed in the case of passed tests, I did a little bit of research, and it looks like using the junit framework limits one’s ability to do this. The problem is that the tests just show up as instances of testRun (here in Intellij IDEA, but I imagine similar for other IDEs), and junit does not allow for any output on a successful test (it would have to be a failing assertion). Short of getting more sophisticated with reflection and creating classes at runtime, or overriding the internals of junit, the best I managed so far was to println the file being tested immediately after line 64 of WGTest (you could also instantiate it as Logger.info…), which at least works on the summary view:
for(Resource list : JenaUtil.getResourceProperties(manifest, MF.entries)) {
for(RDFNode member : list.as(RDFList.class).asJavaList()) {
if(!member.isLiteral()) {
Resource test = (Resource) member;
System.out.println("Processing test file " + test.getLocalName());
if(test.hasProperty(RDF.type, SHT.MatchNodeShape)) {
addTestIfSupported(new MatchNodeTestClass(test));
Which at least gives you this in the summary view:
[cid:A996B23F-F239-4198-A2F5-587EC4C32D01]
The other alternative would be to switch to something like log4unit (http://www.openfuture.de/Log4Unit/), which provides more flexibility for this sort of thing, but that is more involved.
p
From: Holger Knublauch <holger@topquadrant.com<mailto:holger@topquadrant.com>>
Date: Monday, January 18, 2016 at 12:08 AM
To: "public-data-shapes-wg@w3.org<mailto:public-data-shapes-wg@w3.org>" <public-data-shapes-wg@w3.org<mailto:public-data-shapes-wg@w3.org>>
Subject: Re: inheritance & reuse
Resent-From: <public-data-shapes-wg@w3.org<mailto:public-data-shapes-wg@w3.org>>
Resent-Date: Monday, January 18, 2016 at 12:08 AM
On 17/01/2016 4:41 PM, Johnston, Patrick - Hoboken wrote:
PJ> OK, not the answer I was hoping for, but so be it. In terms of the test, its purpose was to allow for a class-agnostic shape, Shape1, to be reused by more than one class-scoped shape (here, Shape2). If I were to make Shape1 a superclass of Class1, I would lose that. I admit I find the way section 1.1 is worded really confusing, and the more I read it the less clear it becomes, in particular around the scope of rdfs:subClassOf. I like Peter’s definition approach in one of the earlier threads. Maybe it would be better to come right out and say that RDFS actually plays no part in the construction of shapes and the shapes graph, but that shapes are able to follow rdfs:subClassOf relationships declared against instances in the data graph. The question is then whether these declarations will be processed if they are made in only the data graph, or the shapes graph, or both? What is really unclear is what of OWL can play in here, if at all, for example instances of owl:Class, definitions which might themselves be imported into the shapes or data graphs using owl:imports. I don’t want to reignite what seems to have been a painful debate, but not mentioning OWL is doing your readers a disservice. I see a place for both OWL and SHACL in the work I am doing currently (hence the questions), they achieve different ends.
The way that it is intended to work is that it will indeed only consider rdfs:subClassOf triples. But there are many different ways of how these subclass triples can be produced, including (but not limited to) RDFS and OWL inference engines. And even with OWL there are many dialects and implementations, e.g. based on rules. The question to me is how much of this needs to go into the spec, and how much is better left to tutorials and primers.
PJ2> Fair enough. I do think that if there is a selective reuse of paradigms from other vocabularies, that should be stated unambiguously in the spec, but that’s the WG's call.
1.
2. Having a shape apply to data graph subclasses of a class in its scope (inheritance-003, OK).
3. The ramifications of shape merging through reuse, inheritance, and owl:import.
* The same shape with overlapping constraints (inheritance-002, fails for the same reason inheritance-001 fails)
* Different shapes with the same scope and overlapping constraints (inheritance-004, OK)
* Duplicated triples in data graphs (e.g. If there are instances of shape classes in the owl:import) (duplication-001, OK)
RDF graphs are sets of triples, so it is not possible to have duplicate triples in a single Turtle file. The Jena parser would already remove the duplicates.
PJ> Agreed that this shouldn't happen, but Jena is just one implementation: other implementations may just leave duplicates in (maybe saying the same thing twice means something to somebody), especially if they originate from different graphs in a quad store, say. Using owl:imports isn’t exactly common behavior in regular linked-data-land, so I think it is worth calling out explicitly.
If a graph implementation preserves and returns duplicate triples then the implementation has a serious bug. I don't think we can predict all possible bugs.
PJ2> OK, if you don’t think this is worth specifying, consider this closed. To be specific, I was trying to mimic duplicate triples in multiple named graphs connected through owl:imports, not duplicate triples in a single file (or graph). For example, if the implementation was SPARQL-based and omitted the DISTINCT on the union of graphs.
1.
2. The effect of uniqueLang when language is not specified (uniqueLang-001, fails)
I cannot comment on how common the case you describe will be in practice - having a fallback language and interpreting plain xsd:string literals as having a default language. Maybe you are right, but it will certainly complicate the logic here (e.g. we would need to decide what to do with rdf:HTML triples not just xsd:string). In any case there is the fallback to define your variation of the unique language pattern in SPARQL.
PJ> If the intended scope of sh:uniqueLang are values of type rdf:langString, then the RDF1.1 spec seems to indicate that this also encompasses plain strings (see https://www.w3.org/TR/rdf11-concepts/#dfn-language-tagged-string). In other words, “fred” will validate both as an rdf:langString and as xsd:string.
This is not my understanding. In the text that you quote it states that simple literals are syntactic sugar for xsd:string.
PJ2> I re-read the text, and you’re right. It still doesn’t explain why the modified definition I supplied in my last comment doesn’t fail validation in the current implementation. I can work around this in JSON-LD by supplying a default language in the context for data graphs (I really don’t want to complicate things with SPARQL unless really needed), or using schema:inLanguage for RDFa, I was hoping for something less serialization-specific for shapes.
Regards,
Holger
Attachments
- image/png attachment: A996B23F-F239-4198-A2F5-587EC4C32D01.png
Received on Tuesday, 19 January 2016 16:17:44 UTC