- From: Holger Knublauch <holger@topquadrant.com>
- Date: Fri, 19 Jun 2015 14:17:43 +1000
- To: public-data-shapes-wg <public-data-shapes-wg@w3.org>
- Message-ID: <558397E7.2080103@topquadrant.com>
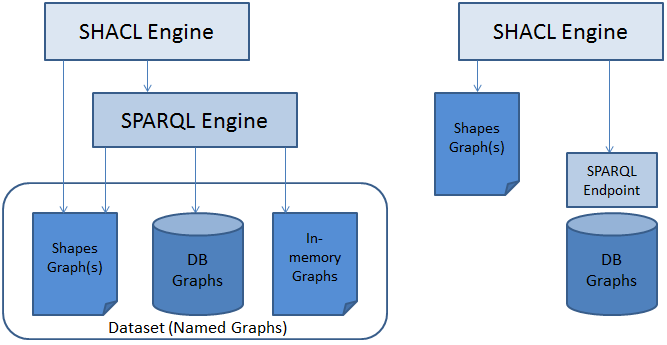
To make sure we are talking about the same things, I am attaching a small illustration of two SPARQL-based engine scenarios. The design on the left hand side is based on a Dataset that provides access to a collection of named graphs. These graphs may include in-memory graphs, virtual graphs, or database-backed graphs. The Dataset is accessed programmatically via a SPARQL engine that sits on the same machine as the engine. Popular choices here are access via the SPARQL APIs of Jena or Sesame. These SPARQL engines are quite easy to extend with new functions, provide the maximum of flexibility and operate on true node objects (including preserving blank node IDs) and have features to pre-bind variables in SPARQL queries. This is the design used in TopBraid server products, Fuseki and similar enterprise tools. The design on the right hand side is based on a SPARQL endpoint, which also contains the SPARQL engine. This takes the SPARQL engine beyond the control of the SHACL engine, i.e. there is in general no way to add functions, no way to control which named graphs are accessible, no way to control inferencing. Due to the serialization of the SPARQL endpoint protocol, blank node IDs cannot be preserved. Variable pre-binding is not possible, everything needs to go through text serialization. This design is simpler but not as flexible as the other option. It can only provide a sub-set of the features of the dataset-based design. These are entirely different setups, for different user groups. This is not a one-size-fits-all discussion. If the SPARQL endpoint people don't need access to ?shapesGraph, SHACL functions, recursion and blank nodes then fine for me, but they should not block the dataset people from covering their use cases. Thanks, Holger On 6/19/2015 9:17, Holger Knublauch wrote: > I believe before we can decide on things like ?shapesGraph access, we > need to clarify the spaces in which SHACL will be used. The platforms > and use cases will be very heterogeneous. > > a) Pure "core" engines that may not support any extension language > - some may include hard-coded support for certain templates (OSLC?) > > b) Engines that can operate against a SPARQL endpoint > > c) Engines that can operate against datasets, accessed via an API like > Jena > - with inferencing support > - without inferencing support > > d) Engines that operate on a client in JavaScript, without SPARQL support > > e) SPARQL-based engines that also support JavaScript, XML Schema etc. > > ... > > Not every one of them will be able to handle all SHACL files, e.g. b) > cannot handle recursion or blank nodes or ?shapesGraph. Some c) will > not handle queries requiring RDFS or OWL inferencing. However, a c) > can in principle handle SPARQL endpoints, by treating the endpoint as > a graph, so there is nothing wrong with it in principle. > > The situation is similar to OWL Lite/DL/Full. Being a consequence of > Design-by-committee, it is natural that not everyone will be perfectly > happy, and it leads to a certain level of mess by default. > > A consequence of this situation is that my proposal uses the "Full" > language as the basis of the spec, but includes error-handling for > cases that certain engines may not handle. Most features can also be > handled by engines that only cover subsets, e.g. sh:allowedValues can > be converted into a FILTER NOT IN ... for SPARQL endpoints, and to > whatever code the ShEx engine uses. > > My proposal remains to write down the SPARQL endpoint support as a > separate deliverable or chapter, similar to how ShEx people will write > down how their implementation works. This way, everyone gets the > features they need. > > Holger >
Attachments
- image/png attachment: SHACL-Engines.png
Received on Friday, 19 June 2015 04:20:04 UTC