- From: John Madden <john.madden@duke.edu>
- Date: Wed, 6 Jul 2005 09:56:34 -0400
- To: public-swbp-wg@w3.org
- Message-Id: <5766E87A-D4DA-4009-86A9-FCFAFAF2C475@duke.edu>
Natasha, Alan & Pat, and others,
I've been studying the 6/2005 draft on N-ary relations, and I want to
say what an exciting and thought-provoking piece of work it is. This
has resulted in somewhat extended notes. Since the draft internally
invites comment, I hope you might consider the following observations
from a non-member for what they're worth. If there are misconceptions
in what follows, I apologize up front and ask your collective
indulgence.
Best wishes,
John Madden
Duke University
Durham, NC
john.madden@duke.edu
========================================
(1) ABSTRACT: “...more than one individual or value. These relations
are called n-ary relations.”
This is purely stylistic, but... really, unary and binary
relations are also n-ary relations (n=1, n=2). So even though I
understand this has become the "loose" usage in some (database)
circles, I think it's more appropriate to call these “multinary
relations” (some people use “polyary”, but I don't like that;
the “multi-” prefix is in keeping with the Latin-derived pattern
set by unary, binary, ternary, etc.) You could also call them
“(n>2)-ary relations.” Or “relations of arity >2”.
(2) USE CASE EXAMPLES
I think it's a shame to leave out the most classic example
of all (and the one that in my experience most reliably produces
insight): namely the between relation. How about an example like:
“New York is located between Boston and Philadelphia” or “2 is
an integer with magnitude between 1 and 3.”
(3) PATTERN 1: “Christine has a breast tumor with high probability.”
First of all, this is a wonderfully thought-provoking
section, congratulations. But a suggestion: You've specifically
chosen an example of a relation modified with a probability. While I
love the boldness of this, I think the example is infelicitous. For
the unsuspecting reader, it could conflate issues of
representational best practice in RDF-OWL with tough issues of how to
implement probabilistic reasoning in description logics. You leave
yourself open to the objection whether this particular representation
pattern is really suitable for use in construction of knowledge-bases
upon which automated probabilistic inferencing will be performed. (To
which, I think, the most honest answer is, “Nobody knows”; since
we really don't know how probabilistic extensions to description
logics will best be implemented on the Semantic Web. In fact, if I
were making a public OWL ontology today that included probabilistic
info, I'd probably use an annotation property.)
There is also the related but intellectually prior objection, that
the meaning of probability has multiple possible formal semantics. So
it would take more explanation to indicate what formal sense of
“probability” was intended here; and hence by reason of this
vagueness, it’s not an apposite choice as a paradigmatic example for
any particular representation alternative.
But I can think of alternative, less controversial examples of
semantically modifying a relation with this pattern. Look at it this
way: this pattern could be understood as an RDF/OWL-style formal
language replacement for the natural language (NL) adverb
construction. In NL, adverbs specialize or restrict verbs. The
owl:objectProperty can be thought of as loosely analogous (in some
situations) to the verb in a natural language sentence. OWL doesn’t
seem to “like” the idea of modifying owl:objectProperty with other
properties (i.e. while you can define an owl:objectProperty that has
a domain of owl:ObjectProperty—in effect constituting an “adverb
slot” on a property—this offers no obvious---to me---advantages
over simply using the OWL-native strategy of just defining a
subproperty).
By contrast, this pattern might be a reasonable alternative to
subproperties in certain cases where NL would tend to resort to an
“adverb”. For example, suppose you wanted to reason about a world
that included facts like:
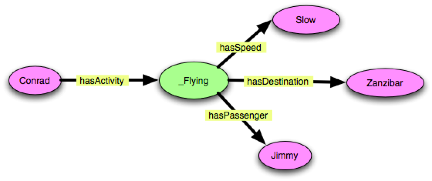
”Conrad is flying slowly to Zanzibar with Jimmy.”
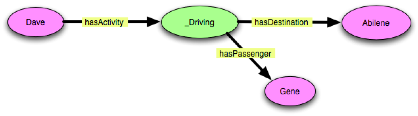
”Dave is driving to Abilene with Gene.”
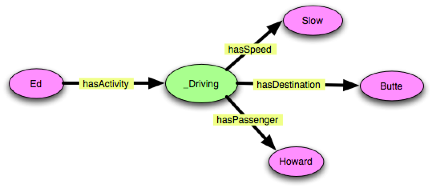
“Ed is driving slowly to Butte with Howard.”
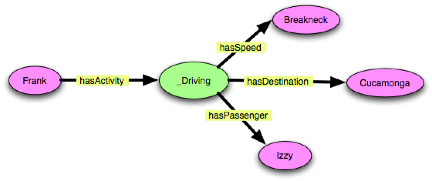
“Frank is driving at breakneck speed to Cucamonga with Izzy.”
One way would be to define properties isDrivingTo and isFlyingTo with
domain Person and range Place, and then subproperties
isFlyingSlowlyTo, isDrivingSlowlyTo and isDrivingAtBreakNeckSpeedTo.
You’d still have to come up with a way of representing the passenger
relation. You could define a second property isTravellingWith with
domain and range Person, but that seems to introduce some semantic
redundancy that invites mismodelling.
A very reasonable alternative is to nominalize or “gerund-ify” the
verb (recall that a gerund is noun formed from a verb, typically
using the “-ing” ending) and represent this way:




These examples are very close in spirit to Example 1, but they avoid
the complications of using probability. They also show how this
pattern can circumvent a “combinatorial explosion” of
subproperties by allowing re-use of the hasSpeed property and its
associated value partition.
(4) USE CASE 2:
This one is very similar to Use Case 1, but I agree that
it’s distinguishable. In fact, I think it’s the most familiar and
broadly applicable of all the use cases presented, and I’d give it
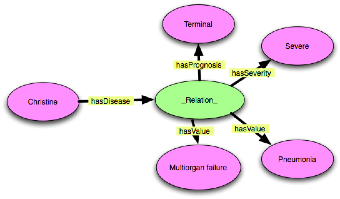
first priority in the exposition. For example, Christine has severe,
terminal pneumonia with multiorgan failure could be represented many
ways, but one (by my lights) good one would be to interpret it as:
“Christine’s got disease situation going on: it’s pneumonia,
it’s multiorgan failure, it’s severe, and it’s terminal”. So
it's a kind of pattern that will get used all the time in actual
knowledgebases.

(5) USE CASE 3: Considerations when introducing a new class…
In the diagrams, you use the “_:” notation in the
“aggregating” node. This suggests these should be implemented as
blank nodes. You address this, where you say “we did not give
meaningful names” to them. Then at the end of the draft, just before
the notes, you then add some more discussion of this issue in
“Anonymous vs. named instances in these patterns”. These two
sections do not quite make the same suggestions, and ought to be
reconciled and merged into a single discussion, in my view. I see
several issues:
(a) A blank node does not merely lack a “meaningful name”---blank
nodes have no names at all, and are referenceable only indirectly, by
querying their properties. I think underlying this discussion,
there’s an important distinction that is not coming through clearly
between “blank” nodes and “without-explicitly-named-type” nodes.
(b) If the aggregating node is implemented as a blank node, then I
would just like to raise a possible concern about staying within OWL
DL. In OWL DL there are certain constraints (that I don't claim to
fully understand) on making a blank node the object of more than one
triple (see the “Avoid structure sharing section in the OWL
reference, and see also Bechhofer & Carroll, Parsing OWL DL: Trees or
Triples?, WWW2004, May 2004). In the examples given, it strikes me as
pretty likely that the aggregating node would be a juicy target to be
the object of other triples. (For example, in a medical knowledgebase
with a terminology and with an assertional store comprised of many
subdocuments, it would be natural to want to refer to "Christine's
disease situation" from later OWL subdocuments.) So it might (please,
check with an expert from S & AS) be preferable therefore to make it
a named node in order to stay within OWL DL. (Apololgize if this is a
red herring.)
(c) You mention “a special subclass of the n-ary relation class”,
and you comment that maintenance could become an issue. Does this
mean you actually recommend having a named “utility” class in your
ontology (something like NAryRelation), and to make these anonymous
individuals be instances of this class?
Well, what I see this pattern as doing is creating an anonymous
individual that need not be an instance of any explicitly named
class. Whether that individual has inferred type owl:Thing or some
subtype of it (or, even, of owl:Class, in which case we’re in OWL
Full)—to my mind, that’s something that a classifier should infer
(in DL at least), and would depend a lot on what other constraints
already exist in the ontology, especially, what domain and range
constraints pre-exist on the properties that reference this unnamed
individual (here: has_temperature, temperature_value,
temperature_trend). In other words, at least in DL, why worry about
maintaining the type of the unnamed node (because the classifier
could do the maintaining)?.
(d) At the very end of the draft where you discuss the utility of
blank nodes, you say that blank nodes would be appropriate for cases
where you want to indicate equivalency. But I disagree; by my lights,
that would actually be a great case for named nodes, because then you
could explicitly state an owl:sameAs relation among several such
nodes. So, for example, in a medical record comprised of many OWL
subdocuments, you could use sameAs to indicate that the “disease-
situation” node characterized in document A was actually referring
to the the same “disease situation” characterized in document B
using a different node—-but this would be convenient and reliable
only if the nodes in question were named.
Attachments
- text/html attachment: stored
- image/png attachment: image003.png
- image/png attachment: image006.png
- image/png attachment: image009.png
- image/png attachment: image012.png
- image/png attachment: image015.png
- application/pkcs7-signature attachment: smime.p7s
Received on Wednesday, 6 July 2005 13:56:53 UTC