- From: <henry.story@bblfish.net>
- Date: Mon, 23 Mar 2015 10:45:57 +0100
- To: Erik Wilde <dret@berkeley.edu>
- Cc: Elf Pavlik <perpetual-tripper@wwelves.org>, Halpin Harry <hhalpin@w3.org>, Ann Bassetti <ann.bassetti@boeing.com>, Social Web Working Group <public-socialweb@w3.org>, Social Interest Group <public-social-interest@w3.org>, "Martin, Julie" <julie.martin@boeing.com>, "Donovan, Andrew R" <andrew.r.donovan@boeing.com>
- Message-Id: <651DC5D8-ED71-4EAF-A57A-1D47EF526EC6@bblfish.net>
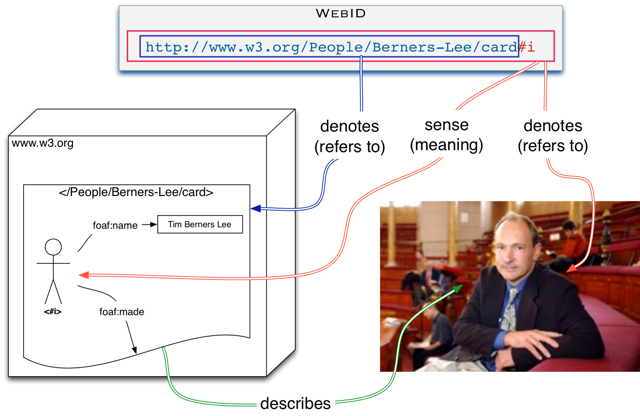
> On 23 Mar 2015, at 10:23, Erik Wilde <dret@berkeley.edu> wrote: > > hello elf. > > On 2015-03-23 10:07, ☮ elf Pavlik ☮ wrote: >> On 03/23/2015 09:56 AM, Erik Wilde wrote: >>> i am wondering if/why semantic tooling would even be required. if we say >>> that AS2 is JSON-based, then there's no requirement to define new >>> vocabularies with RDF, correct? semantic tooling would be necessary for >>> those who *want* to use it, but that would be outside of AS's scope. >> If we design RDF Ontologies, those who want to use them as still JSON >> can do that thanks to JSON-LD. It comes with certain limitations but we >> can consider it a Lite mode which will not provide all the robust >> features. If we don't keep RDF in mind while designing, it may not work >> very well if someone wants to use more powerful features and treat it as >> Linked Data. > > that's the point i've been trying to make, and decision we've been dancing around for a couple of months. is AS2 JSON-based, or is it RDF-based. saying that it's "JSON-LD based" really doesn't solve the problem, it simply provides rhetoric to justify our inability to decide. > >>> the approach follows the idea of https://github.com/dret/sedola, which >>> has the same idea of providing a basic documentation harness (in the >>> case of sedola it's used for for media types, HTTP link headers and link >>> relation types), without forcing people to subscribe to a single >>> modeling framework that's required to formally describe these things. >> Could you please give an example of how those who want to treat it as >> Link Data can simply do so? Once again, we can not just say "we don't >> mind if you try to use it as Linked Data", but if we want to make it >> possible we must keep it in mind when we design things. > > it all comes down to how things are defined. if we *require* all identifiers to be dereferencable, then we (probably) require people to publish RDF at those URIs. if one the other hand we treat identifiers as identifiers, then it is outside of the scope of AS2 if people decide to publish RDF at those URIs. if they do, they're welcome to do so, but if they don't, that's fine, too. For obvious pragmatic reasons, it helps a lot in adoption of vocabularies if the descriptions for those vocabularies is published at the location of the vocabularies, as developers and tools can quickly find out the definitions automatically. So vocabularies that follow this obvious pattern have a great selective advantage. It can be explained in terms of a very old sense/reference distinction. If you can find the sense of a URL easier then you can more easily work with that URI. See http://www.w3.org/2005/Incubator/webid/spec/identity/ Of course that is why the web is so successful, because people who put documents at the end of their URLs make the whole web more useful. ( You can of course decide to build a web page full of URLs or even URNs that have no way of being dereferences, but you'd find nobody would link to your web site ) Note that RDF like HTML can be defined without requiring you to publish the documents at the URL. So we can get a long way in describing vocabularies in RDF without deciding about where the vocabulary should be published. In any case if these vocabularies have a W3C name space, this will be a problem for the W3C to deal with and so this discussion is out of scope for this WG. > > conflating the concepts of identifiers and links can be risky. if AS2 says that concepts such as activity types and object properties are identifiers, then everything works just fine. if otoh AS2 says that those concepts must be treated as links, that's a very different design. > > practically speaking, many linked data implementations treat core concepts as identifiers anyway, because otherwise the web would melt down under the constant load of implementations pulling in all interlinked concepts every time they encounter them, to check if they may have changed. What happens is that an application that wants to survive site outages, and other misshaps, should of course not dereference constantly its core ontologies, but should keep a cache of them, or have its logic implicit in its software. Software that does not do that will - i.e.. that dereferences all vocabularies will 1) be slow 2) be prone to be blocked by web sites if it is really spammy This will simply lead to the death of the said software. So you don't need to give up on making something understandable, by making it opaque. You can publish your ontologies correctly and of course guide developers to writing good clients. A good client could update these ontologies from time to time, and there also HTTP caching information can be very helpful. > >>> as an experiment, i have created sedola documentation for many W3C and >>> IETF specs, and despite the fact that these are using different (and >>> often no) formalisms, this still results in a useful list of the >>> concepts that matter: >>> * https://github.com/dret/sedola/blob/master/MD/mediatypes.md >>> * https://github.com/dret/sedola/blob/master/MD/headers.md >>> * https://github.com/dret/sedola/blob/master/MD/linkrels.md >> Looks cool! I guess meant for human consumption and not for machine >> processing? > > so far i'm just publishing MD because it's easy and it's good to look at. it would be trivial to transform it into other metamodels, such as JSON, XML, or RDF. yes, that is probably the best way to do knowledge engineering. 1) you get domain experts to agree on what the core concepts are by pubishing them in a wik 2) you get ontologists to formalise those intutions allowing them to uncover hidden assumptions which allows them to go back to the experts in 1) 3) the formalised vocabularies can then be tested against real world use case > > wrt to human consumption vs machine consumption: machines can understand the concepts that have been defined somewhere, so that's already pretty useful. and that's really all there practically is, because the vast majority of meaningful concepts on the internet and the web today have only textual descriptions, so there's nothing to consume for machines other than a distilled list of the concepts defined in those specs. > > cheers, > > dret. > > -- > erik wilde | mailto:dret@berkeley.edu - tel:+1-510-2061079 | > | UC Berkeley - School of Information (ISchool) | > | http://dret.net/netdret http://twitter.com/dret | > Social Web Architect http://bblfish.net/
Attachments
- text/html attachment: stored
- image/png attachment: PastedGraphic-1.png
Received on Monday, 23 March 2015 09:46:31 UTC