- From: Michael Kifer <kifer@cs.sunysb.edu>
- Date: Mon, 15 May 2006 22:08:04 -0400
- To: public-rif-wg@w3.org (RIF WG)
- Message-ID: <5170.1147745284@kiferserv.kiferhome.com>
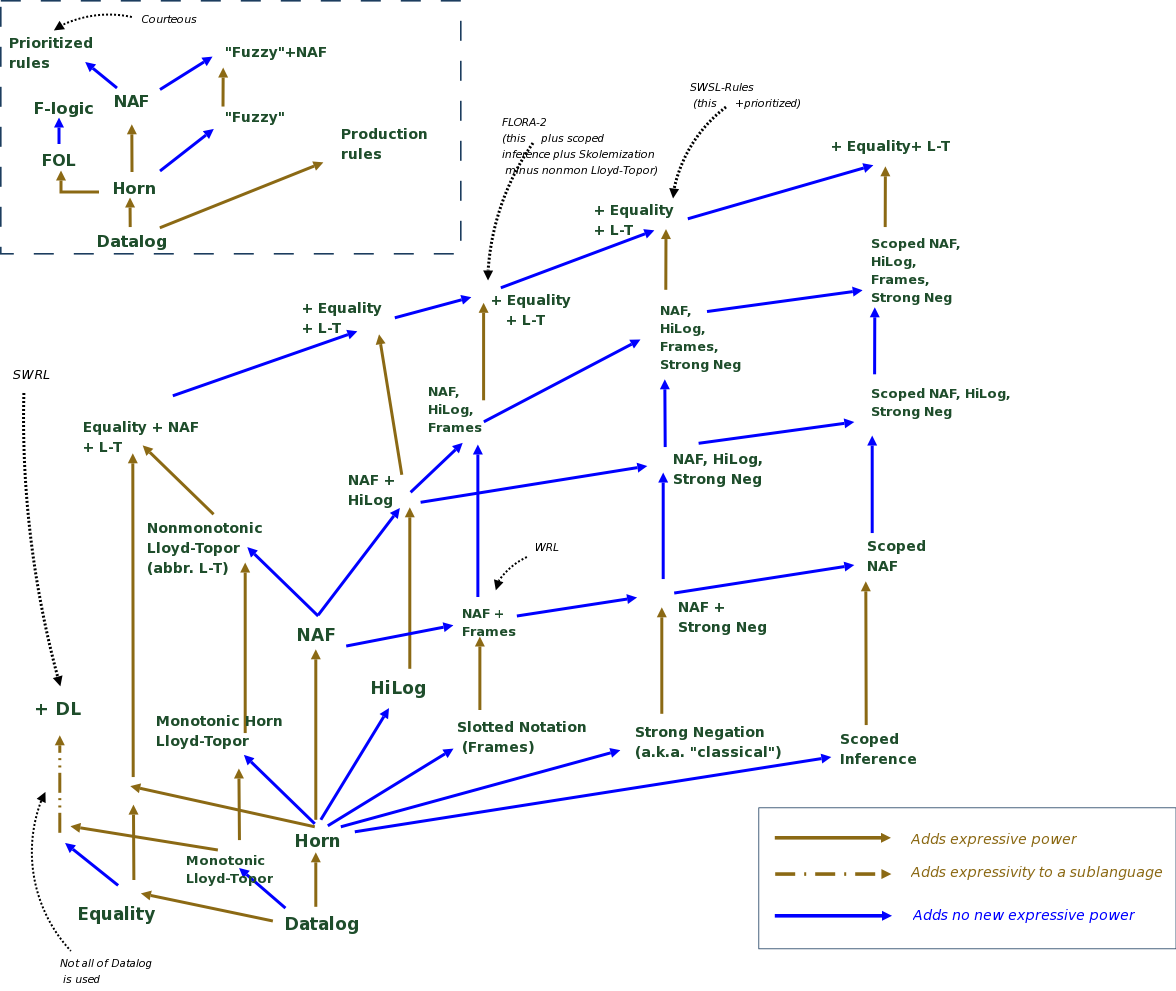
I've used some of the RIFRAF classification to put together a preliminary taxonomy of features that are of interest to the RIF. While this pictorial taxomony is much easier to grasp than the RIFRAF description, I realized that drawing it is very hard because of the inevitable clutter. I had to omit a number of combinations of various features, which make sense both semantically and syntactically. (This doesn't mean that RIF should endorse all combos, but having a comprehensive diagram could be useful.) I used 2 kinds of arrows. One denotes extensions that add expressive power and one that doesn't. I avoided calling them "semantic" vs. "syntactic" extensions, because these things are not well-defined. In one case I used a third kind of arrow (extension of a sublanguage) because I had to cut off a subset of Datalog that uses only binary and unary predicates in order to reduce clutter (SWRL is sitting directly on top of this). I also tried to place various languages at their appropriate places in this taxonomy. I was fuzzy about the "fuzzy" extensions, because there are several, and also vague about what is meant by NAF (there are 2 most popular ones and several others). This is all very prelim and I am a bad diagram drawer. Hopefully someone here is better at this. I am attaching a png, which can be used in any browser; and SVG file, which can be edited and displayed in the browser with an appropriate plugin (despite the claimed Firefox 1.5 support for SVG, it can't display that one); and the source file for the DIA tool, which I used to draw all that. --michael
Attachments
- image/png attachment: taxonomy.png
- application/octet-stream attachment: taxonomy.svg
- application/x-gzip attachment: taxonomy.dia
{kind=link}
Received on Tuesday, 16 May 2006 02:08:28 UTC