- From: Niklas Lindström <lindstream@gmail.com>
- Date: Tue, 18 Jun 2024 12:07:27 +0200
- To: "Peterson, Eric L. [US-US]" <Eric.L.Peterson@leidos.com>
- Cc: "public-rdf-star-wg@w3.org" <public-rdf-star-wg@w3.org>
- Message-ID: <CADjV5jeYEQ6YXqsMZ0B8gk8DE3zPG-Y9KDS1YxZumT4RvbBPjA@mail.gmail.com>
Hi Eric,
Thanks for your input and example!
(The following is my take on where the WG is at in relation to your
example. But as it also reflects my own opinion within the WG, others may
disagree.)
What you are doing is a perfectly valid approach. But it has the generally
major drawback that you now cannot put those quads in a named graph. Thus,
you have to decide on either using the fourth position to name triples (or
sets of them), or to partition a dataset into administrative units.
*If* we could relate graphs, say by stating that one is "owned" by another,
then it *might* be doable. But we spent the latter part of 2023 exploring
ways to do that, and it was deemed impractical, due to 1) lack of named
graph semantics (it is *outside* of the formal interpretation), and 2)
adding semantics and options here without stepping on existing uses of
named graphs, particularly for security and access control, would be
complex if even possible, and 3) could even if so take years to see
possible uptake of in quad stores. It would also 4) be far beyond the
charter of this working group. That does not mean that we don't have a
responsibility to avoid adding more confusion to the mix though -- whatever
is added should be explainable *in relation to* practices for named graphs.
We have also basically agreed that the use cases we must cater for all are
about *some kind* of occurrences
(reifications/qualifications/tokenizations) of triples. (That is essential
for mapping to LPGs, for instance, who are decidedly "instances of an edge
type", or "multisets", in some descriptions thereof.) So we won't (if all
goes well, IMHO) allow triple terms themselves as subjects, since triples
themselves are the atomic, logical axioms we model a particular domain of
discourse with, and do not denote any particular underlying circumstance.
Such circumstances (which can be anything, including but not limited to the
statement tokens of classical reification) are always "reifying" them; so
we call those "reifiers".
Therefore we at the beginning of 2024 tentatively agree that e.g. this:
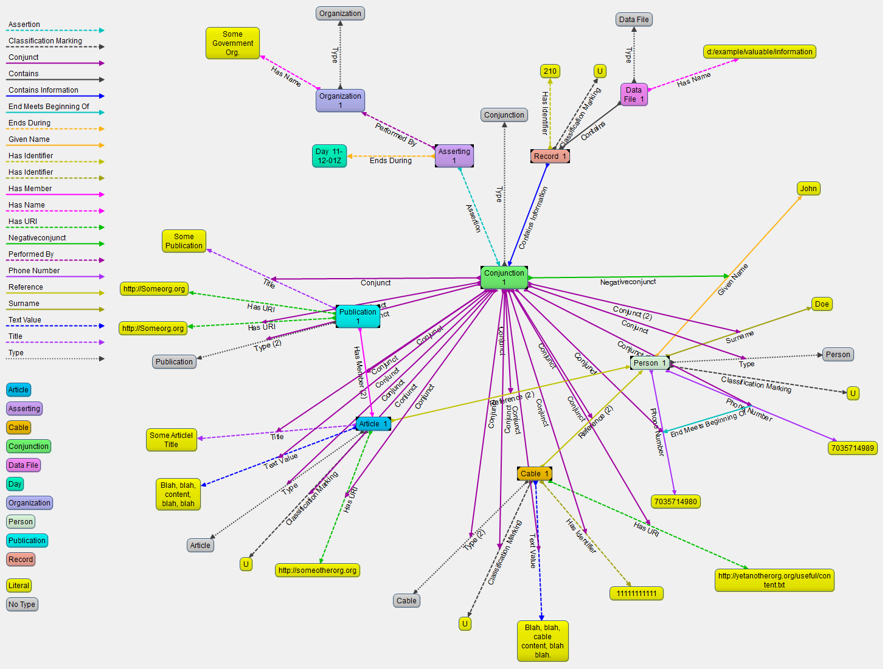
<< _:Person__1 ex:hasPhoneNumber _:11111111111 >> pr:source _:DHS .
Would be shorthand for this (a blank node unless named):
_:b rdf:reifies <<( _:Person__1 ex:hasAddress _:a )>> .
_:b pr:source _:DHS .
Where the triple term itself is only allowed in the object position, and is
in some ways a "literal-like" three-tuple. (The choice of <<( ... )>> is to
distinguish these from the sugar, which has been kept to do minimal
modification at this stage, and stay compatible with the RDF-star CG
syntax.)
There is also the additional annotation sugar:
_:Person__1 ex:hasPhoneNumber _:11111111111 {| pr:source _:DHS |} .
Which means the above plus the assertion itself (the triple being in the
graph), i.e.:
_:Person__1 ex:hasPhoneNumber _:11111111111 .
_:b rdf:reifies <<( _:Person__1 ex:hasPhoneNumber _:11111111111 )>> .
_:b pr:source _:DHS .
But this agreement did not hold. We are now debating whether or not the
fact that it caters for more variations is a good thing, such as this:
_:b rdf:reifies <<( _:Person__1 ex:hasAddress _:a )>> .
_:b rdf:reifies <<( _:a :streetAddress "SomeStreet 1" )>> .
_:b rdf:reifies <<( _:a :city <SomeCity> )>> .
_:b pr:clearance _:UNCLASSIFIED ;
pr:source _:DHS ;
pr:likelihood 0.8 ;
pr:dataSet _:someDataSet ;
pr:sourceRecord _:PERSON ;
pr:sourceRecordID 329 .
Or if that is a problem. It has been deemed, by some, a problem since LPGs
cannot handle that, and possibly since classical reification was decidedly
one reifier per statement. But the important question is whether or not it
*makes sense*. In general reification (e.g. in UML and some forms of N-ary
relations) and philosophy (see "truth-makers" [1] [2]) it appears to do so.
A third objection is that this blurs the line between reification and named
graphs.
But IMHO your example is actually a good example of why perhaps we *should*
"blur" that line. Since named graphs, as per above, cannot be used
simultaneously for recording detailed sub-graph provenance *and* be outside
of interpretation, as they are today, we have the opportunity to address
this shortcoming with this. (Named graphs are then, effectively, mostly for
working with dataset management (such as in quad stores and the LDP); with
the upshot that such a mechanical, "opaque" treatment is critical for
access control (secured private graphs, etc.)).
Another, related, contentious issue is whether triple terms should
themselves be "opaque" or not (or if the same triple could be either opaque
and transparent, such as *in a way* is the case with graphs -- since
they're *outside* of semantics, you can decide whether to interpret them or
just treat them as sets of triples). It is still unclear if this opacity is
*needed* (to avoid entailment) or a nice-to-have (if so, you could instead,
for instance, record in a reifier representing a statement token exactly
what syntactic form was used, but using your own terms, not any particular
syntactic sugar or datatype semantics thereof).
Again, thanks for your input! If you have further practical use cases for
triple provenance, please share what you can. And if through these you have
any opinion also on the "reifier for multiple triples" and "opacity"
questions, please let us know.
(Aside: Please note that there is an issue with using pipes for naming the
reifier [3], at least for the annotation form; so don't rely on it yet
other than for discussion.)
Best regards,
Niklas
[1]: <
https://www.researchgate.net/publication/325995356_Reification_and_Truthmaking_Patterns
>
[2]: <https://plato.stanford.edu/entries/truthmakers/>
[3]: <https://github.com/w3c/rdf-star-wg/issues/116>
On Tue, Jun 18, 2024 at 8:46 AM Peterson, Eric L. [US-US] <
Eric.L.Peterson@leidos.com> wrote:
> I live happily without RDF named graphs by constructing provenance
> networks which are much richer than RDF graphs. And they are optimizable.
> I claim we should put the optimization burden on the SPARQL query tool
> before we complicate RDF - like named graphs did and like the RDF-star
> proposal threatens to do.
>
> Please consider quads, my friends.
>
> Just add a new SPARQL term called *EDGE*. It would be completely
> synonymous with *GRAPH. *
>
> The fourth member of the quad is a terrible thing to waste.
>
>
>
> ------------------------------
> *From:* Peterson, Eric L. [US-US] <Eric.L.Peterson@leidos.com>
> *Sent:* Monday, June 17, 2024 3:26 PM
> *To:* public-rdf-star-wg@w3.org <public-rdf-star-wg@w3.org>
> *Subject:* Re: Naming triples
>
> I have been naming my triples for many years.
>
> I just use the fourth member of the quad for the triple name (URI):
>
> ------------------------------
> *From:* Peterson, Eric L. [US-US] <Eric.L.Peterson@leidos.com>
> *Sent:* Monday, June 17, 2024 3:04 PM
> *To:* public-rdf-star-wg@w3.org <public-rdf-star-wg@w3.org>
> *Subject:* Naming triples
>
> Hi folks;
>
> Thanks for working on getting us something better than triple reification
> for edge metadata!
>
> Would I be justified in being very disappointed in a spec that didn't
> allow me to name triple terms?
>
> For simplicity below, I didn't model this example the way I would at
> work. But look at all the notational duplication. Can we have a spec that
> allows that naming of triple terms and the subsequent referencing of the
> name in place of a triple term?
>
> I'm very new to RDF-star/SPARQL-star. Please forgive me if I've missed
> some way around this issue.
>
> <<_:Person__1 ex :hasPhoneNumber _:11111111111>> pr:clearance
> _:UNCLASSIFIED .
> <<_:Person__1 ex :hasPhoneNumber _:11111111111>> pr:source _:DHS .
> <<_:Person__1 ex :hasPhoneNumber _:11111111111>> pr:likelihood 0.8
> <<_:Person__1 ex :hasPhoneNumber _:11111111111>> pr:dataSet _:someDataSet .
> <<_:Person__1 ex :hasPhoneNumber _:11111111111>> pr:sourceRecord _:PERSON .
> <<_:Person__1 ex :hasPhoneNumber _:11111111111>> pr:sourceRecordID 329 .
>
>
> Thanks!
>
> -Eric
>
Attachments
- image/png attachment: image.png

- image/png attachment: 02-image.png
Received on Tuesday, 18 June 2024 10:08:03 UTC