- From: Benedikt Kaempgen <kaempgen@fzi.de>
- Date: Thu, 28 Feb 2013 17:03:37 +0000
- To: Dave Reynolds <dave.e.reynolds@gmail.com>, "Government Linked Data Working Group" <public-gld-wg@w3.org>
- Message-ID: <0D7BFFD7C415144DA75C3D49C46AC21512AB3017@ex-ms-1a.fzi.de>
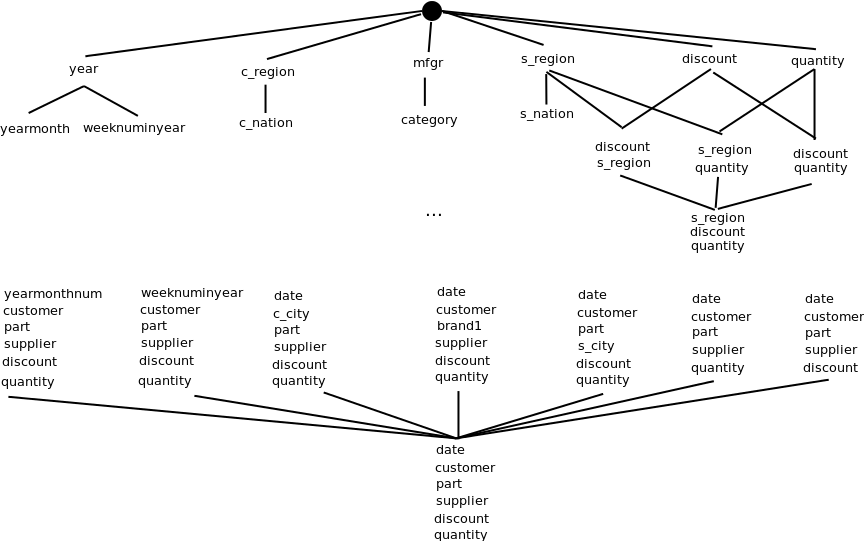
Hi, I see a possible use case of qb:subSlice: In OLAP systems one often tries to materialise parts of the entire data cube to optimise query processing. This materialisation can be done along a "data cube lattice" of views on the data cube. See attached a figure of such a possible lattice. Assuming the node on the very bottom of the figure is the original dataset (with date, customer... as dimensions). Then, the nodes connected to this base node are "slices", aggregating the original dataset on a certain dimension (i.e., slicing this dimension to an ALL value). Every node reachable from these slices further up are "sub-slices" that further slice dimensions. In this sense, the relationship qb:slice or qb:subSlice between dataset, slice, and subslice would mean something like "derived from via slicing a dimension". This may be helpful in applications to quickly find the ideal slice for answering a query. I would be in favour of keeping the option of representing such a use case. There are at least two options: 1) Remove qb:subSlice and allow qb:slice both on qb:DataSet and qb:Slice. 2) Leave qb:subSlice. Best, Benedikt ________________________________________ Von: Dave Reynolds [dave.e.reynolds@gmail.com] Gesendet: Mittwoch, 27. Februar 2013 15:52 An: Government Linked Data Working Group Betreff: [QB] ISSUE-34 proposed resolution As it says in the ISSUE description ... """ The Data Cube slice mechanism allows hierarchical organization of slices though the use of qb:subSlice. However, it is not possible to distinguish between different levels of sub-slice when defining attachment levels, which in terms makes abbreviated formats for such cubes under-defined. """ While it would be possible to fix the issues the subslice mechanism is not part of SDMX and I've not seen its use in "in the wild" Data Cubes, perhaps because of the lack of clarity. Proposal: remove qb:subSlice (leaving it in the ontology but marked as deprecated and removing mention of it from specification document). Dave
Attachments
- image/png attachment: cube_lattice_ssb.png
Received on Thursday, 28 February 2013 17:04:04 UTC