- From: Aaron Goldman <goldmanaaron@gmail.com>
- Date: Mon, 1 Jul 2024 09:42:25 -0700
- To: Joe Andrieu <joe@legreq.com>, public-did-wg@w3.org
- Message-ID: <CAE6sXqivYt6C1SCnP4x6sn4MaunHmH18nwJPq2KxWSRpf3NgwQ@mail.gmail.com>
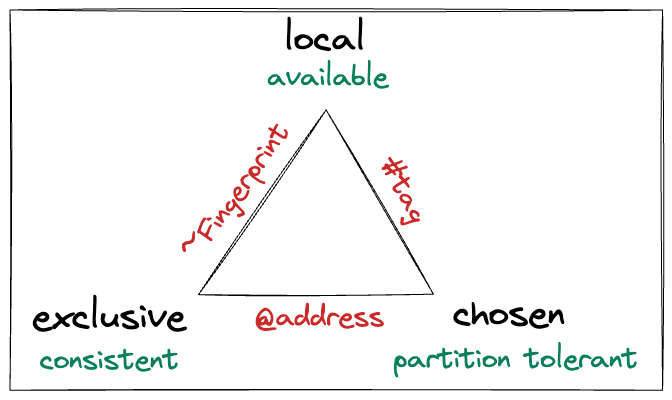
Thanks for the response, Joe, but I don't agree. I don't think that that is abandoning our fundamental goals. Take for example RFC 6920 Naming Things with Hashes ( https://www.rfc-editor.org/rfc/rfc6920.html). The URI ni:///sha-256;UyaQV-Ev4rdLoHyJJWCi11OHfrYv9E1aGQAlMO2X_-Q This URI relies on the fact that `*ni://*` is defined as a rfc6920 uri It relies on the fact that `*sha-256*` is reserved for ``` [SHA-256] NIST, "Secure Hash Standard", FIPS 180-3, October 2008, <http://csrc.nist.gov/publications/fips/fips180-3/ <http://csrc.nist.gov/publications/fips/fips180-3/fips180-3_final.pdf>fips180-3_final.pdf <http://csrc.nist.gov/publications/fips/fips180-3/fips180-3_final.pdf>>. ``` This does not imply that `*ni://*` URIs are centralized. If what we wanted was to have strings that where only meaningful in the context of the applicationthen simple strings would be sufficient. The reason we want to have a DID specification at all is to agree on what a `*did:**` means. just as it was fine to have the hashing method `*sha-256*` reserved for the sha-256 algorithm it is reasonable to reserve method strings for `did:` is for example `did:key:*` has a defined meaning that does not necessarily mean that DIDs are centralized. Anyone with access to the specification can still make a `did:key:*` without needing permission. Each *method* needs to make the tradeoffs for method specific identifiers that are consistent, chosen, or decentralized. [image: image.png] e.g. did:key is a fingerprint and is decentralized and exclusive but you can't pick the string. did:web is an address and is chosen and exclusive but you need to rely on the CA and DNS systems. But the methods can only make those tradeoffs if the method string itself can be defined to be a specified method. On Mon, Jul 1, 2024 at 9:02 AM Joe Andrieu <joe@legreq.com> wrote: > Unfortunately, you just made a concise and reasonable argument for > centralizing decentralized identifiers, which is a non-starter. > > There is no requirement per RFC3986 that the beginning of a URL be unique. > > There is also no requirement that DID methods have a unique method name, > precisely because enforcing such a requirement creates a centralized > dependency on the registry that performs that task. This is a non-starter. > > I realize a lot of people think the uniqueness of method names is a > requirement for some reason. It is, in fact, an anti-pattern we are trying > to get beyond. > > To wit: if you are comfortable with a centralized naming authority, DNS > and IP addresses work great. They are both operationally decentralized > through federation and have proven themselves to work. What makes DIDs > decentralized is that there is no the root authority, nor is there the > hierarchy of trust that is the fundamental centralizing element in DNS that > DIDs are designed to address. If centralized authority is OK, we have no > need for Decentralized Identifiers at all. > > The challenge in our work is to build something that doesn't defer to a > centralized root authority. > > That's the point. > > It is impossible to achieve that point if we create a centralized > registry, and we can't ensure a claimed namespace without a centralized > registry. So, requiring a first-to-claim namespace and its necessary > registry is simply antithetical to the work. > > There are a number of efforts to resolve this, some of which use > cryptographic commitments instead of method names, others require each > method to provide its own mechanism for disambiguating from other known > mechanisms. None of these are ideal and certainly none are widely accepted. > We still have work to do. > > However, we should not abandon our fundamental goals just because an > incomplete solution appears to be simpler and more easily realized. > > -j > > > > On Mon, Jul 1, 2024 at 8:36 AM Aaron Goldman <goldmanaaron@gmail.com> > wrote: > >> There is some requirement for exclusivity. >> If a DID is to be exclusive the method strings must be exclusive. >> `did:method_a:specific_identifier` and `did:method_b:specific_identifier` >> should be as exclusive as the respective methods allow. >> just as `http:` `ftp:` `mailto:` need to not be overloaded with multiple >> specifications `did:method_a` should have a single specification as to >> what that method means. The need for a registry is as simple as preventing >> competition for a method string and providing a link to a specification for >> how to turn a DID_String into a DID_Document. >> >> Now if you wanted a ` >> did:self-descriptive:self-discoverable:specific_identifier` and then >> have a weather exclusivity guarantee for that "method" you could put the >> discoverable methods under it. >> >
Attachments
- image/png attachment: image.png
Received on Monday, 1 July 2024 16:42:41 UTC