- From: Michael Herman (Trusted Digital Web) <mwherman@parallelspace.net>
- Date: Thu, 2 Sep 2021 14:51:15 +0000
- To: Orie Steele <orie@transmute.industries>, "W3C Credentials CG (Public List)" <public-credentials@w3.org>
- CC: "tantek@tantek.com" <tantek@tantek.com>
- Message-ID: <MWHPR1301MB2094DC1111FCBE9D6F5ED6EDC3CE9@MWHPR1301MB2094.namprd13.prod.outlook.>
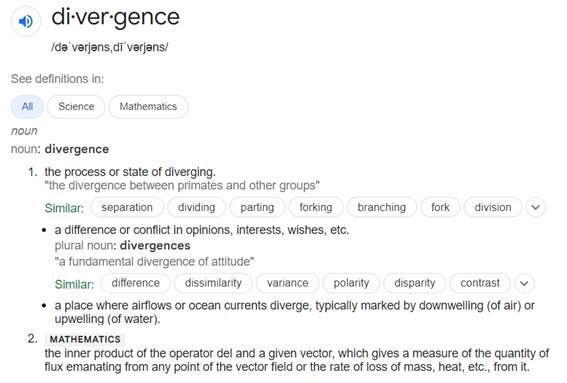
CC: Tantek I find the Mozilla Foundation’s equivalence between the DID scheme and the other RFC 1738 schema confusing and not well served. In general, I don’t find any of the 4 issues to be compelling or justifiable. I don’t find any of the 4 issues to be justifiable reasons for blocking the DID v1.0 W3C Proposed Recommendation. * No practical interoperability. First and foremost, a DID URN is an identifier …DIDs are a way to construct names for people, places, organizations, and things …and not a resource locator in the traditional sense when compared to the 10 schemes in RFC 1738. Conceptually, DIDs have a closer relationship to, for example, email addresses than they do to HTTP URLs. The fact that DIDs can be used as a resource locator for DID Documents (via DID Resolution protocols) is secondary and somewhat incidental – in a similar incidental way of email addresses are used as login identifiers for Facebook, Google, apple.com, microsoft.com, etc. NOTE: I’m not trying to denigrate the importance, utility, and purpose of DID Documents and the DID Resolution protocols, I’m just placing them in perspective relative to the importance of DIDs themselves (the decentralized string identifier). With respect to methods (what I call method spaces), method spaces are more akin to DNS domain names or .NET or Java namespaces. “Over the fullness of time”, IMO, there will be (and should be) hundreds, thousands, and millions of method spaces. I discuss the Musicians’ use case and justification here: https://youtu.be/J6n9TvxA93I?t=253 (watch for 2-3 minutes). Did anyone in history try to limit the number of second or third level, etc. domain names? No, there’s an infinite number of possibilities and an entire global commercial and governance world was built to support these. DIDs can, will, and do interoperate using the DID Resolution protocols. DIDs can also be resolved using Internet standard DNS protocols. Here’s a working example that runs on my laptop every day: https://hyperonomy.com/2019/12/03/trusted-digital-web-first-trusted-web-page-delivered-today-dec-3-2019/ * Encourages divergence rather than convergence. The word “divergence” is used without being defined. Whether intended or not, IMO, I find this to be a diversionary use of the term intended to distract from the topic at hand. Here’s a copy of the definitions from Google… [cid:image003.jpg@01D79FD7.ADE303C0] Divergence is, in fact, good …depending on your definition and the metrics used; in the same way, that diversity is good. I refer again to the Musicians use case (see link above) as a proof point. In terms of Tantek’s representation discussion, IMO the discussion is mixing apples and oranges: mixing DIDs and DID Documents. DID identifiers are what is at the core (i.e. the formatted string identifiers). DID Documents and their various representations are secondary. DID Documents are allowed to have various logical/physical serializations as long as they can be mapped (both ways) to the underlying DID data model (Hyperledger Indy on-ledger data model is the global proof point for this). The conventional DNS entry model allows for various representations not just at the server and client level but also the data formats used by the various DNS protocols. * Centralized methods allowed, in contradiction to WG & spec goals & name. I have to concur that there are some centralized method spaces but it is better to think of these as *private* method spaces more than they are “centralized method space”. The code in every app has public namespaces as well as private namespaces. So too with DIDs. Although the wording in the specification could better reflect this, I feel this objection is a bit of a red herring. In the Trusted Digital Web, a developer can create a new method spaces whenever they want to (https://github.com/mwherman2000/TrustedDigitalWeb) in the same way they create a new .NET namespace whenever they want to. * Proof-of-work methods (e.g. blockchains) are harmful [to] sustainability(s12y). “I live in a world of computing abundance.” (Credit: https://github.com/w3c/vc-data-model/issues/796#issuecomment-909271998) What if the sustainability argument was used to thwart the advances made in computing since the very first card punches appeared on the market (1949)? What if card punches (http://www.columbia.edu/cu/computinghistory/026.html) were allowed to set power consumption restrictions for every advance in computing from that point onwards)? Tantek’s argument, IMO, is a concern but not one that can be justifiably used to prematurely block a W3C proposed recommendation. The real-world marketplace will either find an alternate solution (in the fullness of time) or perhaps (and hopefully not) it will languish. * Conclusions I don’t find any of the above 4 issues to be compelling or justifiable. I don’t find any of the above 4 issues to be justifiable reasons for blocking the DID v1.0 W3C Proposed Recommendation. * In closing, I’m reminded of Sam Curran’s Openness to Innovation Principle (https://hyperonomy.com/2019/03/12/internet-protocols-and-standards-not-only-need-to-be-open-but-more-importantly-open-to-innovation/): “If you look at important Internet protocols like TCP-IP that enable packets on a network to carry any type of data including text, email messages, web pages, etc, and, later on, streaming audio and streaming video, who could have imagined it? It’s vitally important for Internet protocols to not only be open but open to innovation …innovations that might succeed as well as innovations that might fail. No one can foretell how the specifications we’re creating today will be used in the future.” Sam Curren<https://www.linkedin.com/in/samcurren/>, March 11, 2019 Best regards, Michael Herman Far Left Self-Sovereignist First Principles Thinker Self-Sovereign Blockchain Architect Trusted Digital Web Hyperonomy Digital Identity Lab Parallelspace Corporation [cid:image005.jpg@01D79FD7.ADE303C0] From: Orie Steele <orie@transmute.industries> Sent: September 1, 2021 8:12 PM To: W3C Credentials CG (Public List) <public-credentials@w3.org> Subject: Mozilla Formally Objects to DID Core https://lists.w3.org/Archives/Public/public-new-work/2021Sep/0000.html The objection mentions comments from Google and Microsoft, but does not link directly to them. Does anyone have a direct link to the comments from Google and Microsoft? OS -- ORIE STEELE Chief Technical Officer www.transmute.industries<http://www.transmute.industries> [https://drive.google.com/a/transmute.industries/uc?id=1hbftCJoB5KdeV_kzj4eeyS28V3zS9d9c&export=download]<https://www.transmute.industries/>
Attachments
- image/jpeg attachment: image003.jpg
- image/jpeg attachment: image005.jpg

Received on Thursday, 2 September 2021 14:51:35 UTC