- From: Michael Herman (Parallelspace) <mwherman@parallelspace.net>
- Date: Mon, 8 Apr 2019 03:59:02 +0000
- To: Adrian Gropper <agropper@healthurl.com>, Markus Sabadello <markus@danubetech.com>
- CC: W3C Credentials CG <public-credentials@w3.org>
- Message-ID: <BYAPR13MB2837C89D3C43FE2E28C4EE0DC32C0@BYAPR13MB2837.namprd13.prod.outlook.com>
RE: I can't tell which of these current things will remain when DIDs come online
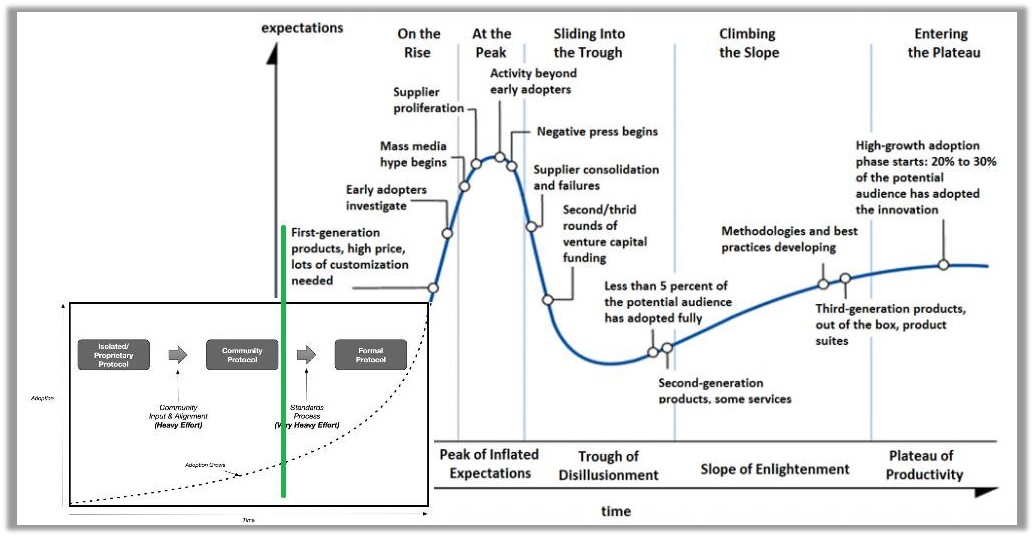
Adrian, we’re much too early in the DID technology adoption lifecycle to tell which competing/overlapping technologies/solutions/specifications will dominate - let alone, which technologies will survive.
Mass acceptance/deployment of Decentralized Identifiers is a long ways away ….TCP-IP took 30 years. I’m willing to wager DIDs won’t reach mass acceptance/deployment until 2030 or later.
Checkout: Phases of Foundational Technology Adoption
https://www.linkedin.com/pulse/blockchain-foundational-technology-michael-herman/
Here’s what I think the hype cycle for DIDs looks like at the beginning of 2019: (https://twitter.com/mwherman2000/status/1103683539592048642)
[cid:image002.jpg@01D4ED84.B8680DC0]
Best regards,
Michael Herman (Toronto/Calgary/Seattle)
Independent Blockchain Developer
Hyperonomy Business Blockchain / Parallelspace Corporation
W: http://hyperonomy.com<http://hyperonomy.com/>
C: +1 416 524-7702
From: Adrian Gropper <agropper@healthurl.com>
Sent: April 7, 2019 2:33 PM
To: Markus Sabadello <markus@danubetech.com>
Cc: W3C Credentials CG <public-credentials@w3.org>
Subject: Re: Notes from 2019-03-21 DID Resolution Spec First Draft Meeting
Markus, thank you so much for picking up on my question!
I went and reviewed a bunch of papers including:
- https://www.w3.org/wiki/WebID
- https://docs.google.com/document/d/1oUDVxWy674ZWG2ElB3YN9bcmSXXR9f2mg60E_Uazigc/edit?ts=5c79597d#heading=h.rfqxmrvt8ml5
- https://techcommunity.microsoft.com/t5/Azure-Active-Directory-Identity/Identity-Hubs-as-personal-datastores/ba-p/389577
I'm more confused than ever.
Here's what I hope I could explain to a patient or a doctor:
* DIDs improve on today's choice of email address or Login with Facebook by adding convenience, privacy, and security.
* DIDs solve the explosion of passwords for authentication, but require you to have a Web browser or mobile app that holds secret keys
* In almost all cases, you will also want to have server / web site / hub somewhere online, away from your Web browser or mobile app
* You can choose where this server is, move it, or host it yourself without having to re-register your ID with every website and merchant that you gave a DID to.
* You can choose how much of the information you attach to a DID is public and how much is private. For example, you may want to attach a photograph to your DID so that people can match it to your in-person face the way they use a driver's license. You may not, however want the search engines and everyone else to be able to add your face and DIDs to a global database of everyone.
* In order to decide who gets to see your face or anything much else about you, you will have some authorization features on your mobile device and / or on your sever.
* When this authorization feature is on your mobile device, you will be asked and have to click something.
* When this authorization feature is on your server online, the server can act on your behalf without bothering you as long as it can understand and trust the credentials presented by whoever is asking and depending on what they are asking for.
* DIDs also help the person who is asking you or your server for authorization present their credentials in a way that protects your privacy as well as theirs.
Right now, I believe that all of the above is true but if someone asked me to explain how this relates to WebID, OIDC, UMA, X509, FIDO, I would tell them it's too complicated for me to understand. I can't tell which of these current things will remain when DIDs come online. Why would anyone ever use Sign In with Facebook? Would I still need my 1Password or will 1Password change to list a bunch of DIDs instead of usernames and passwords?
Adrian
On Fri, Apr 5, 2019 at 1:02 PM Markus Sabadello <markus@danubetech.com<mailto:markus@danubetech.com>> wrote:
Adrian,
I just realized nobody had responded to this question, sorry about that.
We were talking about WebIDs on that earlier call, because just like DIDs, WebIDs are also URIs that are designed to identify an individual in the real world (e.g. Alice).
And just like a DIDs can be resolved to a DID document, a WebID can be resolved to a WebID profile.
In my mind, the difference between a DID or WebID, and e.g. an OpenID Connect UserInfo Endpoint, is that the latter is not an identifier for Alice.
Instead it's a URL of a service associated with Alice that can be used to authenticate or interact with Alice.
An OpenID Connect UserInfo Endpoint can be discovered from a DID or from a WebID.
Those distinctions are important if we want to be 100% in line with (Semantic) Web architecture and principles.
Does that make sense?
Markus
On 3/22/19 12:32 PM, Adrian Gropper wrote:
Question:
Along with WebID, might we also consider DID Resolution for folks familiar with OpenID Connect UserInfo Endpoint?
Adrian
On Fri, Mar 22, 2019 at 6:46 AM Markus Sabadello <markus@danubetech.com<mailto:markus@danubetech.com>> wrote:
Zoom recording, chat logs, and slides for the (now weekly) DID Resolution Spec First Draft Meeting are here:
https://github.com/w3c-ccg/meetings/tree/gh-pages/2019-03-21-did-resolution
List of attendees and call notes are here below. You can also read them on the meeting page<https://docs.google.com/document/d/1BKbwWCS9ZT1Aawxv2YVvGUUOv9WfPqMK9MiWh1s9dLo/>.
Markus
DID Resolution Spec First Draft Meeting Page
This page is for taking notes of weekly meetings held in 2019 of members of the W3C Credentials Community Group<https://www.w3.org/community/credentials/> who are collaborating to complete the First Draft of the DID Resolution specification<https://w3c-ccg.github.io/did-resolution/>. Meeting notes are listed in reverse chronological order.
Note: This meeting directly follows the weekly DID Spec Community Final Draft Meeting<https://docs.google.com/document/d/1qYBaXQMUoB86Alquu7WBtWOxsS8SMhp1fioYKEGCabE/>.
Call Information
Time: Every Thursday, 14:00-15:00 PT
https://zoom.us/j/7077077007
Or iPhone one-tap:
US: +16465588656,,7077077007# or +16699006833,,7077077007#
Or Telephone:
Dial (for higher quality, dial a number based on your current location):
US: +1 646 558 8656 or +1 669 900 6833
United Kingdom: +44 (0) 20 3051 2874 or +44 (0) 20 3695 0088
Meeting ID: 707 707 7007
International numbers available: https://zoom.us/u/q6mghCSZ
Links (Generally Useful to the Group)
* DID Spec<https://w3c-ccg.github.io/did-spec/>
* DID Resolution Spec<https://github.com/w3c-ccg/did-resolution/>
Thursday 21 March 2019
Attending
* Markus Sabadello
* Jonathan Holt
* Drummond Reed
* Joe Andrieu
* Michael Herman
* Stephen Curren
* Dmitri Zagidulin
* Dan Burnett
* Nader Helmy
* Amy Guy
* Adrian Gropper
* Chris Boscolo
* Yancy Ribbens
Agenda
1. Community governance: issue resolution and closure policies
2. What does it mean to dereference a DID URL?
3. Presentation of the above README: did-url-spec - Decentralized Identifier URL (did-url) Specification as well as the spreadsheet: https://github.com/mwherman2000/did-url-spec/tree/master/src (latest numbered version)
Meeting Notes
Topic #1: Understanding DID URLs and “Resolution” and “Dereferencing”
Markus explained the overall topic using this slide:
[https://lh5.googleusercontent.com/R3Q0ScmPMHPDLrxRLuHDhbOSD7s0ixR4xKUieyJl8pQKzCzZbo14v6odleeBecAgq4mEmaSN6lVjC61pqiPTafgjM_6KFUM4DkewhWLqtvKP9I7gqqCyn0HcOgbIMpdpFZaEhKql]
Michael pointed out that the “defererencing” category also splits into two:
1. A DID URL that dereferences to a subcomponent of a DID document.
2. A DID URL that undergoes a transformation to address a resource external to the DID document via a service endpoint.
Markus went on to explain the following slide:
[https://lh4.googleusercontent.com/UTicihWqBhrN4B0vzJu4ST8s9EKoBpPXDBQ67nqKvvH0szxyaRh0on7iDM3HShxQdTDXWXvraHKmCysVr_OOD3dv4kkJEaFo8qTKMvc2dT18r-NW6Bs2qAzSnBoPyvnjLwv7reFc]
Jonny asked how much DID resolution is actually parallel to DNS resolution.
Michael said that he has a set of proposals for how a set of DID resolution operations can work, e.g., how to query the capabilities of a resolver, or how to get a list of DID documents.
Michael whether returning a DID document is “access”?
Joe responded that access to a DID document is an open issue. Some proposals are to encrypt a DID document.
Drummond proposed that “DID resolution” be the set of steps that a DID method takes to return a DID document. He agreed with Joe that a particular DID method may in fact impose access control on obtaining a DID document. He then said that once a DID document is returned, you move into the “dereferencing” stage, and that can divide into the two types discussed above.
Dan: The DID document is not itself the resource, but a means of determining how to access the identified resource.
Markus next talked about this slide:
[https://lh6.googleusercontent.com/4GGve1LW2xR1BF7HFnBne_ToyZph-y4B_APUcAaW4ZUnxaPEotUmoIE-cg_V1tks5F2uysujqTamYixKNUOfSiva2lFBzy_lx7FGTpgOl0wxhOLjvnVwQShRRr0ppcg_ujQl1f9K]
Drummond: Let’s avoid the HTTP Range 14 rathole! Let’s be clear that a DID never identifies a DID document! A DID identifies a DID Subject. That DID Subject MAY be a network-accessible resource. In that case a DID document describes how to access that resource. But the DID document may identify a non-network resource (like a person), in which case the DID document describes how to access service endpoints associated with the resource.
Jonny: IPLD is a type of resource that a DID may identify.
Joe: The resource when a DID is dereferenced is always on the network.
Markus spoke to this slide:
[https://lh5.googleusercontent.com/m7mvQ0Fma_W-uGb1xQxRsn1SqRY_JEBqDS_HeHQkWkC1a5Pd0aJMeS9Rfj7Q6Jq9xX_ZGOuzT0lhHl5MQHnMxQEElpBqSoM01W58LpCLYWb3QqcJi34Ziacn9QK6p3eg_PJBUjF_]
Joe and Drummond discussed the analogy with DNS and URL-identified resources. Drummond said that the DNS record that is retrieved in order to access the web page or RDF document. The DNS record is not the resource being identified by a URI. Therefore it is the equivalent of a DID document.
Markus next discussed this slide:
[https://lh5.googleusercontent.com/3MHHRVhHrbfTK2Go3c0u-KMFnjLaIJ2vpJfCqrpfpWpNqT5gS7QwH1u8jDE_vXRD6LIVMWb77RMoeNfSPihOL_DvrktVEEei-uonAPuw60EbQaFcrfHD6lbjCz-kfgiIYYxsIBVB]
Dan dove into this “HttpRange-14” issue by suggesting that a DID subject was not actually a person. “+1 that action on a DID for a physical resource could be to return a URL for a file.”
Drummond suggested that if a DID always identifies a DID subject, and that DID subject may be either a real-world resource (non-network-retreivable) or a network resource. If a DID identifies a real-world resource, then the DID document describes options for interacting either with that real-world resource via some type of network connection, or accessing other descriptions of that real-world resource. But the DID itself still identifies the real-world resource.
If the DID identifies a network-retrievable resource, then resolving the DID to the DID document will enable obtaining the actual URL that also identifies that network-retrievable resource. That means the DID and the URL would actually be “synonyms”, but at different layers of abstraction.
Drummond also said this addresses the “two URI” problem from Web ID. The DID that identifies Alice is URI #1, and the URL that identifies some resource describing Alice (not the DID document) is a second URI.
Joe mentioned that this means that a “naked DID” by itself should not be considered a URL. We should need to add a delimiter at the end of the naked DID to turn it into a URL for the DID document.
Drummond seconded that suggestion. It could be either the empty path, or the empty fragment.
Dan said that he had clarity that a DID document is about how to describe how to interact with a resource, but not describing the resource itself. That’s why a DID document is never the resource identified by the DID.
Action Items
--
Adrian Gropper MD
PROTECT YOUR FUTURE - RESTORE Health Privacy!
HELP us fight for the right to control personal health data.
DONATE: https://patientprivacyrights.org/donate-3/
--
Adrian Gropper MD
PROTECT YOUR FUTURE - RESTORE Health Privacy!
HELP us fight for the right to control personal health data.
DONATE: https://patientprivacyrights.org/donate-3/
Attachments
- image/jpeg attachment: image002.jpg
Received on Monday, 8 April 2019 03:59:32 UTC