- From: Michael Herman (Parallelspace) <mwherman@parallelspace.net>
- Date: Wed, 3 Apr 2019 14:25:48 +0000
- To: jonnycrunch <jonnycrunch@me.com>
- CC: Manu Sporny <msporny@digitalbazaar.com>, W3C Credentials CG <public-credentials@w3.org>
- Message-ID: <BYAPR13MB2837F73B63EA4B8C2696B60FC3570@BYAPR13MB2837.namprd13.prod.outlook.com>
RE: - push the ABNF URL rules to be declared in the individual DID Methods, much like how currently RESTful API document their endpoints
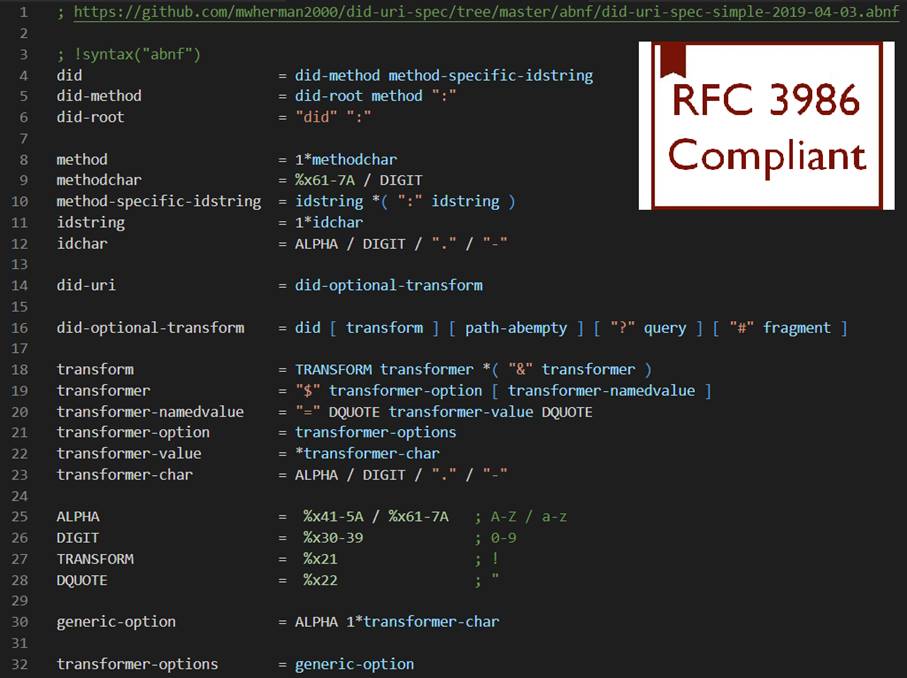
The did-uri-spec fully supports this requirement via something called Domain-Specific DID Grammars. For example, there is a DSDG for “Document Documents”; another for “DID Document Collections”, etc. (and they can be composed). Watch this video to learn more (slightly dated already): https://www.youtube.com/watch?v=IdLm2jHuADg&list=PLU-rWqHm5p45c9jFftlYcr4XIWcZb0yCv&index=4
Also note that except for the Domain-Specific DID Grammar concept, the did-uri-spec grammar is strictly a syntax-level specification. It doesn’t mandate the implementation of any predefined set of $transformer-options. It’s just a set of generic syntax rules for a generic did-uri syntax. I’ve include a copy below. NOTE: This is different from the “DID ABNF” grammar where a strong set of semantics is implied by encoding of the special characters “#”, “!”, and “$”.
[In a few minutes, I’ll be starting a roadtrip to Seattle for the next couple days and won’t be online as much. But feel free to call me in the car – no advance notice required – I’ll welcome the conversation. +1 416-524-7702]
Best regards,
Michael
[cid:image001.jpg@01D4E9F6.D6114670]
Best regards,
Michael Herman (Toronto/Calgary/Seattle)
Independent Blockchain Developer
Hyperonomy Business Blockchain / Parallelspace Corporation
W: http://hyperonomy.com<http://hyperonomy.com/>
C: +1 416 524-7702
From: jonnycrunch <jonnycrunch@me.com>
Sent: April 3, 2019 7:52 AM
To: Michael Herman (Parallelspace) <mwherman@parallelspace.net>
Cc: Manu Sporny <msporny@digitalbazaar.com>; W3C Credentials CG <public-credentials@w3.org>
Subject: Re: A simpler approach to DID services and content-addressing
Both of these approached seem a bit over-engineered and over-reaching for my taste.
I really like the content id and hash-linking approach, and can work some magic to transform and interoperate. however….
My big concern regarding this concept of all DID methods using the same ABNF URL rules to all for “Changing service providers” as that not all service providers will support all methods.
Not to mention in our approach (IPID) there is no service provider. You are your own service provider. It is a distributed, not just decentralized, solution.
This seems to be overreaching authority into each of the DID methods and forcing compliance and thus losing autonomy and self-sovereignty
I’d like to prioritize:
- ABNF rules to separate the naked DID and rest fo the DID URL
- push the ABNF URL rules to be declared in the individual DID Methods, much like how currently RESTful API document their endpoints
- finalizing the DID document spec and clarify the required attributes with hardened rules for a JSON schema declaration and testing
- work on interoperability tests for resolution and validating signatures/proofs issued as verifiable credentials
Best,
Jonny
On Apr 3, 2019, at 12:49 AM, Michael Herman (Parallelspace) <mwherman@parallelspace.net<mailto:mwherman@parallelspace.net>> wrote:
Manu,
Here's simpler solution using the Hyperonomy did-uri-spec specification and grammar. See the attached "Page 47" slide where I've tried to:
1. capture your 3 use cases, then
2. create a did-uri-spec compliant an example did-uri for each use case, and finally
3. added a description of the output.
I've also attached a copy of the did-uri-spec grammar (defined using ABNF notation). See attached image with a black background.
RE: "resolution algorithms"
This is a little more difficult to explain but for the most part, the "resolution algorithms" you describe are actually "parsing algorithms". When using a grammar defined using ABNF notation, the pattern matching, etc. that takes place in the automatically generated parser (automatically generated from the ABNF description of the grammar) as it processes a did-uri is automatic. i.e. there's not need to describe it English if you have a description using ABNF notation. I hope this makes sense.
Best regards,
Michael
________________________________
From: Manu Sporny <msporny@digitalbazaar.com<mailto:msporny@digitalbazaar.com>>
Sent: March 31, 2019 1:38 PM
To: W3C Credentials CG
Subject: A simpler approach to DID services and content-addressing
Apologies for missing the last DID spec call, some of us thought it had
been cancelled due to KNOW2019 and travel. I was reading the minutes
from the last meeting[1] and was happy to see two use cases identified
as driving factors for the DID URI scheme syntax (aka, ABNF) discussion.
I'm also attempting to build on the work that Drummond and Ken did
during RWoT8 (so you two may see some stuff that's familiar in here).
Let me try and summarize the use cases that seem to be driving the DID
URI scheme syntax:
1. Pat wants to publish blogging content in a way where they can switch
service providers, but the relative URLs don't change. For example,
<PORTABLE_SERVICE_PROVIDER_URL>/2019-03-01/lunch-in-barcelona
... which would be transformed to:
<CURRENT_SERVICE_PROVIDER_URL>/2019-03-01/lunch-in-barcelona
2. Yael wants to publish content in a way that ensures the content
integrity of the content. For example,
<CONTENT_URL><SEPARATOR><CONTENT_INTEGRITY_CHECK>
... which would be transformed to:
<PROTECTED_CONTENT_URL> (which returns tamper-evident data)
Now, let's narrow that down to the specification we're talking about,
which is the DID Specification. The pattern would change to something like:
<START_OF_DID><MAGIC><PATH>
and
<START_OF_DID><MAGIC><CONTENT_INTEGRITY_CHECK>
Much of this discussion has been around the <MAGIC> bit above. We know
what we want at the end, but there are many things that could go in the
middle. I should also note that these are two totally different use
cases and the group is probably thrashing because you're attempting to
solve both of them simultaneously. In this case, though, I think there
is at least one simple answer that doesn't require overly-complicated
microsyntaxes. So, here goes:
Use a colon-delimited keyword that you tack on to the end of a "bare DID".
That's it. Here's how it looks in practice for the two use cases above.
For the "Portable URL":
did:example:12345678:path:blog:/2019-03-01/lunch-in-barcelona
... which would be transformed to:
https://example.org/2019-03-01/lunch-in-barcelona
For the "DID with Content-addressing" (example assumes a Sovrin-like
requirement to get a content addressed schema):
did:example:schema:hl:z3aq31uzgnZBuWNzUB
... which would enable you to fetch things from that particular DID
Registry using content-based addressing.
The general matching pattern for the syntaxes are:
For the "Portable URL" use case:
did:<did-method>:<method-specific-id>:path:<service-id>:<service-path>
and for the "DID with Content-addressing" use case:
did:<did-method>:<method-specific-id>:<hashlink>
Note how the use cases are handled with things that you put *at the end*
of the DID URI syntax? This is on purpose for two reasons:
1. It ensures that DID Method authors have very broad control over what
happens in <method-specific-id>, and
2. It enables decentralized innovation to occur while providing a clear
adoption path into the core DID spec. (I think this is a nuance that
many people might not get right now, but that's ok).
Here are two potential resolution algorithms for both use cases:
For the "Portable URL" use case:
1. Search for ":path:" from the end of the DID URL.
2. Split on the first two colons, you should have a 3-tuple:
("path", service-id, service-path).
3. Search the DID Document "service" property for a service
with an "id" ending in "#<service-id" and save this value
as "service-prefix".
4. Concatenate "service-prefix" with "service-path" and return
this value.
For the "DID with Content-addressing" use case:
1. Search for ":hl:" from the end of the DID URL.
2. Split on the first colon, you should have a 2-tuple:
("hl", hashlink-value).
3. Dereference the DID URL and cryptographically hash
the content.
4. Compare the hash of the content against the value
of the hashlink. If the hashes match, the content is
secure.
I believe the proposal above addresses all of the use cases raised by
Evernym and Sovrin. I also think it's compatible with Veres One and
IPFS-based DID Methods. The benefits of this approach are:
1. It ensures that DID Method authors have very broad control over what
happens in their <method-specific-id>, and
2. It enables decentralized innovation to occur for these sorts of
DID URI syntax extensions while providing a clear adoption path into
the core DID spec, and
3. It doesn't require microsyntaxes more than what we have in the
specification right now, and
4. The grammar parsing rules are extremely simple, and
5. It only requires one type of separator character for the DID URI
syntax, the ":" character.
What did I miss? Why doesn't this work? I checked this against all the
current use cases (but did not elaborate on every one as this email is
long enough as it is). Would this work for your use case?
-- manu
[1]https://raw.githubusercontent.com/w3c-ccg/meetings/gh-pages/2019-03-28-did-spec/2019-03-28-irc.log
[2]https://github.com/WebOfTrustInfo/rwot8-barcelona/blob/master/draft-documents/did-spec-refinement.md#feature-refinement
--
Manu Sporny (skype: msporny, twitter: manusporny)
Founder/CEO - Digital Bazaar, Inc.
blog: Veres One Decentralized Identifier Blockchain Launches
https://tinyurl.com/veres-one-launches
<manu-page-47.png><did-uri-spec-simple-2019-04-03.abnf.png>
Attachments
- image/jpeg attachment: image001.jpg
Received on Wednesday, 3 April 2019 14:26:17 UTC