- From: <noah_mendelsohn@us.ibm.com>
- Date: Tue, 12 Sep 2006 18:28:43 -0400
- To: www-tag@w3.org
- Message-ID: <OF6A191E86.992E65E6-ON852571E7.007AAF70-852571E7.007B7B96@lotus.com>
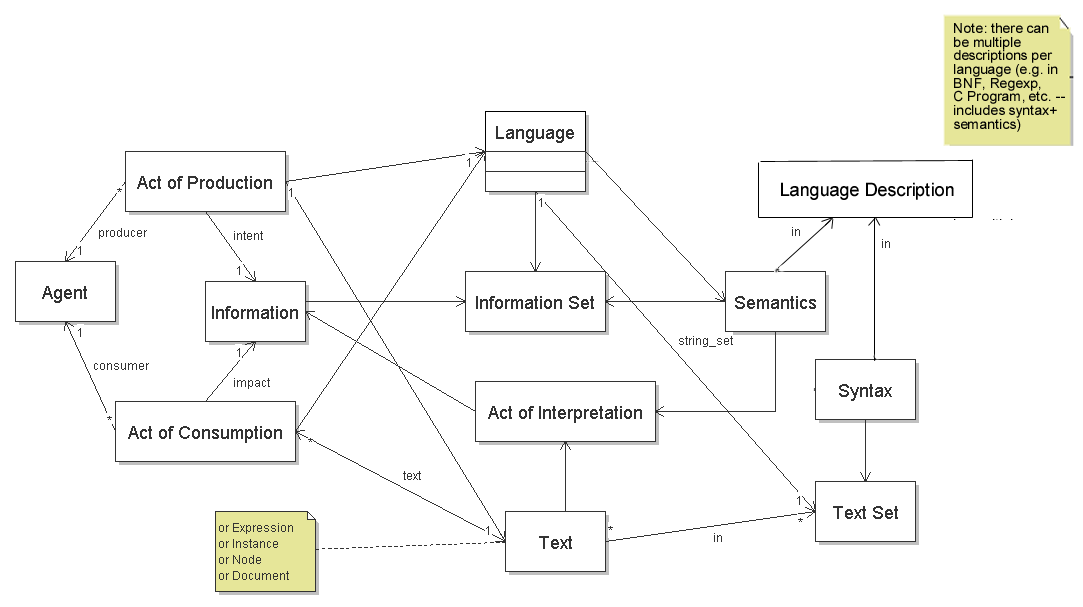
On the call last week we had some discussion of how language descriptions would best fit into the UML diagram in the versioning finding. I've hacked up an edit that's pretty close to showing what I've been thinking. Basically, it tries to show that there can be multiple, alternate (though hopefully consistent) descriptions of the same language, and that none of those descriptions are inherently "part of" the language in the way that the text sets are. Each language description is intended to include a syntax (I.e. a specification of the set of legal texts) and a semantics (which, pending agreement on the right way to say this, I'll loosely describe as determining the information that can be gleaned from each legal text). A few caveats: (1) I'm not a UML expert so there may be some misuse of UML conventions and (2) I don't have the diagram editing tool, so I had to do some really ugly stuff to import a bitmap image of the diagram into a bitmap editor, and hack it up from there. So, while it is being saved as a .png, in fact it's probably just pixels and won't scale. If it looks weird, make sure your viewing tool is zoomed to 100%. If this or something similar meets with approval, someone with the tool should redraw it properly (or point me to the tool and I'll do it, if the learning curve isn't too bad.) Thanks! Noah -------------------------------------- Noah Mendelsohn IBM Corporation One Rogers Street Cambridge, MA 02142 1-617-693-4036 --------------------------------------
Attachments
- application/octet-stream attachment: Versioning_Diagram_with_Suggested_Changes.png
{kind=link}
Received on Tuesday, 12 September 2006 22:28:51 UTC