- From: Patrick Stickler <patrick.stickler@nokia.com>
- Date: Mon, 24 Jun 2002 09:45:32 +0300
- To: ext Geoff Chappell <geoff@sover.net>, RDF Interest <www-rdf-interest@w3.org>
- Message-ID: <B93C9ABF.173BC%patrick.stickler@nokia.com>
On 2002-06-23 19:05, "ext Geoff Chappell" <geoff@sover.net> wrote:
>
> I'm sure this has come up in rdf core datatype discussions but I can't find
> in the archives why it was rejected. Can someone familiar with those
> discussions clear this up for me?
>
> Why can't a datatype class be interpreted as a union of the datatype values
> and their string representations? and as a mapping from value to
> representation when used as a property? for example:
>
> abbrev_integer the datatype contains the sets {10, 3} and {"10", "3"} and
> the mapping ("10"->10, "3"->3)
> abbrev_integer the class contains the members {10, "10", 3, "3"}
> abbrev_integer the property has extension (10, "10"), (3, "3")
>
> {range age abbrev_integer}
> {age x "10"}
>
> is consistent with (and implies)
>
> {age x ?y}
> {abbrev_integer ?y "10"}
>
> and is enough to indicate that ?y=10
>
> If a datatype is understood to contain a set of values, a set of
> representations, and a mapping between the two sets, what is wrong with just
> defining that when viewed as a class, it looks like the union of the two
> sets, when viewed as a property, it looks like the mapping (i.e. different
> aspects of the datatype are seen depending upon how it is used)?
>
> It seems so simple and fully captures the common usage of specifying a value
> by either it's string representation or in a more qualified form (using the
> same property).
>
> Thanks for any responses.
>
> Geoff Chappell
Taking the class extension of a datatype to be the union of the lexical
and value spaces was discussed back in February/March. C.f.
http://lists.w3.org/Archives/Public/w3c-rdfcore-wg/2002Feb/0469.html
http://lists.w3.org/Archives/Public/w3c-rdfcore-wg/2002Mar/0124.html
Many members of the WG felt that this approach was "ugly" and
it was ultimately rejected due to problems pointed out by
Jos De Roo in
http://lists.w3.org/Archives/Public/w3c-rdfcore-wg/2002Mar/0151.html
A functionally similar approach which also uses rdfs:range for
expressing global datatyping constraints, which is one of two
final proposals presently under consideration by the WG, is to
have the literal node of the inline idiom simply denote
the datatype value, where the literal node is similar to a blank node,
but with the lexical form included as a contextually interpreted label.
Thus, given
Jenny age _:x"10" .
age rdfs:range xsd:integer .
the literal node _:x"10" would denote the value ten (10). This means
that the semantics of rdfs:range are used for RDF (data)typing, just
as for any other RDFS class.
Without the range constraint, the meaning of the literal node is
underspecified. It denotes "something" that has a lexical representation
of "10", but we don't know what. This of course means that each
occurrence of a literal string in the graph may denote a different
value, but since literals do not have globally consistent meaning,
that seems to me to be correct (if literals had globally consistent
meaning, i.e. they always denoted the same thing, then they would be
functionally equivalent to URIrefs, so why then have literals at all?).
Thus, the literal
is interpreted as a lexical form in the context of the specific
datatype, such that (datatype, lexical_form) -> value. If the
datatype context is not known, then no datatyping interpretation is
possible. i.e. (???, lexical_form) -> ???
The fact that the literal node both denotes the value and has a
lexical form as a label is simply due to the special nature of
datatypes, which differ from other RDF classes by having the
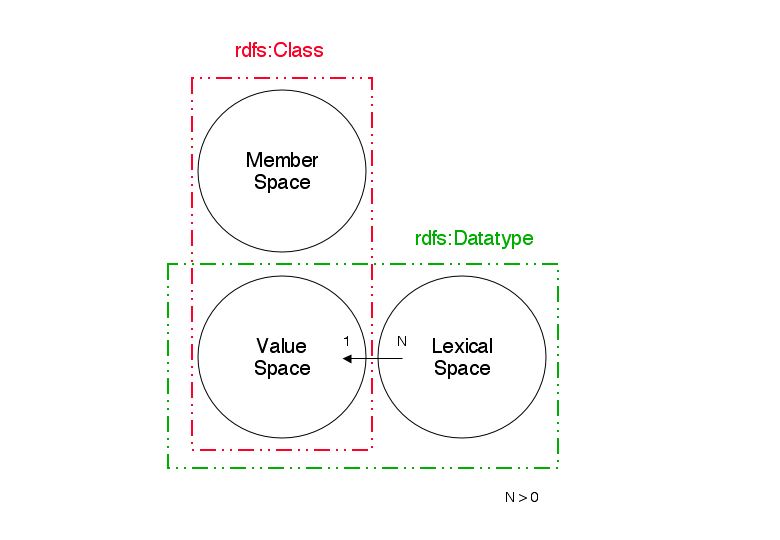
additional lexical space with its N:1 mapping into the value
space. The class extension of a datatype class is its value
space, and thus RDFS semantics work as expected, given the
above interpretation of the literal node as denoting the value.
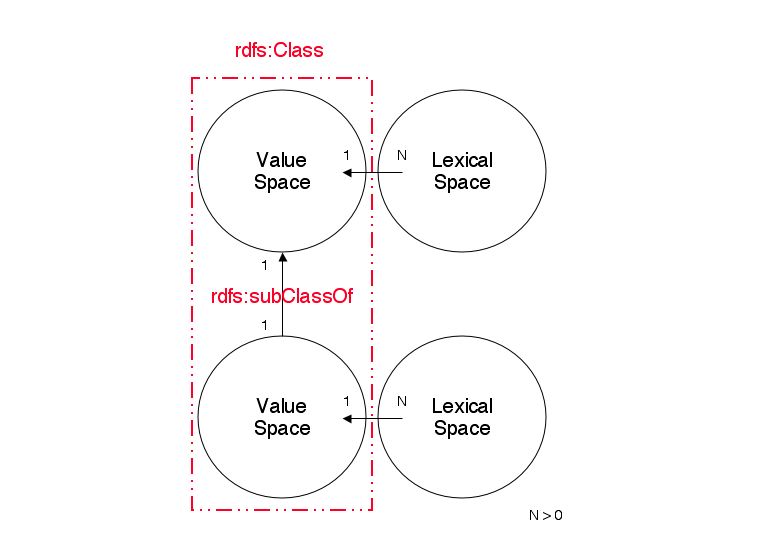
See the attached illustrations depicting the relationship
between RDF Classes and Datatype classes.
The lexical form label is available to applications
which may need to examine it to obtain a system-specific representation
of the value, and this is similar to an application inspecting a
URIref to perform some system-specific operation.
In the future (e.g. RDF 2.0), if (or when ;-) literals are allowed
to be subjects, then we'd just use rdf:type the same as for any other
resource when we need to locally (data)type a particular
occurrence of a value. E.g.
Jenny age _:x"10" .
_:x"10" rdf:type xsd:integer .
In the meantime, we would use the datatype as a property to emulate
the same meaning. Thus
Jenny age _:x .
_:x xsd:integer "10" .
where for any datatype property ?d
?d rdfs:domain ?d .
This at first glance may seem a bit strange, but it's
really quite elegant, and simply asserts that the subject
of any datatype property is a member of the datatype's
value space. This follows from the class extension of
a datatype class being its value space.
Note that this is only one proposal on the table. The ultimate
solution may not reflect such an interpretation, but may leave
the value interpretation of the inline idiom (Jenny age "10")
application specific (which would IMO be a shame) and would
preclude the use of rdfs:range with the inline idiom, but
would have to rely on additional machinery to express any
datatype specific lexical constraints (i.e. some other
datatyping-only range-like constraint property which would
be disjunct from rdfs:range).
I expect (hope) these matters will be resolved very soon
and a comprehensive working draft can be provided to the RDF
community for review.
Cheers,
Patrick
--
Patrick Stickler Phone: +358 50 483 9453
Senior Research Scientist Fax: +358 7180 35409
Nokia Research Center Email: patrick.stickler@nokia.com
Attachments
- image/jpeg attachment: Slide1.jpg
- image/jpeg attachment: Slide2.jpg
Received on Monday, 24 June 2002 02:41:11 UTC