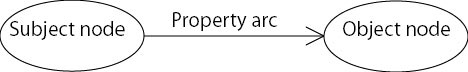![]()
Copyright ©2002 W3C® (MIT, INRIA, Keio), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply.
The Resource Description Framework (RDF) is a data format for representing metadata about Web resources, and other information. This document defines the abstract graph syntax on which RDF is based, and which serves to link its XML serialization to its formal semantics. It also describes some other technical aspects of RDF that do not fall under the topics of formal semantics, XML serialization syntax or RDF schema and vocabulary definitions (which are each covered by a separate document in this series). These include: discussion of design goals, meaning of RDF documents, key concepts, character normalization and handling of URI references.
This is a W3C RDF Core Working Group Working Draft produced as part of the W3C Semantic Web Activity (Activity Statement).
This document is being released for review by W3C Members and other interested parties to encourage feedback and comments, especially with regard to how the changes affect existing implementations and content.
This is a public W3C Working Draft and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use W3C Working Drafts as reference material or to cite as other than "work in progress". A list of current W3C Recommendations and other technical documents can be found at http://www.w3.org/TR/.
There are no known patent or IPR constraints associated with this Working Draft. The RDF Core Working Group Patent Disclosure page contains details, in conformance with W3C policy requirements.
Comments on this document are invited and should be sent to the public mailing list www-rdf-comments@w3.org. An archive of comments is available at http://lists.w3.org/Archives/Public/www-rdf-comments/.
The Resource Description Framework (RDF) is a data format for representing metadata about Web resources, and other information. This document defines the abstract graph syntax on which RDF is based, and which serves to link its XML serialization to its formal semantics. It also describes some other technical aspects of RDF that are not covered by separate normative documents in this series.
The normative documentation of RDF falls broadly into the following areas:
[[[NOTE: it is anticipated that some of the material in this document may be moved to other documents as part of the document review process.]]]
In section 2, some background to the design goals and rationale of RDF is presented. There is also some discussion of the intended implications of publishing an RDF document (section 2.3).
RDF is based on a graph syntax, which is typically serialized using XML (but which is quite distinct from XML's tree-based infoset [XML-INFOSET]). This graph syntax captures the fundamental structure of RDF, independently of any serialization syntax that may be used. The formal semantics of RDF are defined in terms of the graph syntax. The graph syntax is defined in section 3 of this document.
Section 4 presents some other technical issues that don't clearly fall into any of the more explicit areas noted above.
RDF uses well established ideas from various data and knowledge representation communities, with recognizable relationships to Conceptual Graphs, logic-based knowedge representation, frames, and relational databases [Sowa] [CG] [KIF] [Hayes] [Luger] [Gray].
RDF is a member of the family of languages that use XML, which in turn provides a syntactic framework for representing documents and other information. It has a simple graph-based data model and formal semantics with a rigorously defined notion of entailment, which in turn provides a basis for well founded deductions in RDF data.
The real value of RDF comes not so much from any single application, but from the possibilities for sharing data between applications. The value of information thus increases as it becomes accessible to more and more applications across the entire Internet.
The development of RDF has been motivated by the following uses, among others:
The design of RDF is intended to meet the following goals:
RDF has a simple data model that is easy for applications to process and manipulate. The data model is independent of any specific serialization syntax.
NOTE: the term "model" used here in "data model" has a completely different sense to its use in the term "model theory". See the RDF model theory specification [RDF-SEMANTICS] or a textbook on logical semantics (e.g., [HUNTER] [DAVIS]) for more information about what logicians call "model theory".
RDF has a formal semantics which provides a sound basis for reasoning about the meaning of an RDF expression. In particular, it supports rigorously defined notions of entailment which provide a basis for defining reliable rules of inference in RDF data.
The vocabulary is fully extensible, being based on URIs with optional fragment identifiers (URI references, or URIrefs). URIrefs are used for naming all kinds of things in RDF data. The only other kind of label that appears in RDF data is a literal string.
[[[Review this on resolution of datatypes issues]]]
RDF has a recommended XML serialization form [RDF-SYNTAX], which can be used to encode the data model for exchange of information between applications.
RDF can be used with XML schema datatypes [XML-SCHEMA2], thus assisting the exchange of information between RDF and other XML applications.
[[[Review this on resolution of datatypes issues]]]
[[[Datatypes document 1.2 desiderata -> concepts 2.2]]]
To facilitate operation at Internet scale, RDF is an open-world framework that allows anyone to make simple assertions about anything. In general, it is not assumed that all information about any topic is available. A consequence of this is that RDF cannot prevent anyone from making assertions that are nonsensical or inconsistent with the world as people see it, and applications that build upon RDF must find ways to deal with incomplete and conflicting sources of information. (This is where RDF departs from the XML approach to data representation, which is generally quite prescriptive and aims to present an application with information that is well-formed and complete for the application's needs.)
But what consitutes a "simple fact"? Roughly, the kind of information that can be stored in a relational database, possibly about any nameable thing or concept.
The basic building block of RDF is a statement, which is a binary relational assertion. For example, the expression "floats(oil,water)" is a binary relational assertion expressing that oil floats on water. The term "floats" names a relationship that holds between "oil" and "water". An RDF statement can also contain a variable; e.g., as in "floats(?x,water)" expressing that there is something that floats on water, where "?x" stands for the something, without saying what it is.
Conjunction (logical-AND) of statements can be used to express more complex facts, such as "floats(oil,water) AND burns(oil,air)". Using the same variable in several different statements of a conjunction can say more than one might immediately expect, e.g. "type(?x,fluid) AND floats(?x,water)" says there is a fluid that floats on water.
Relationships involving more than two things can be expressed as a conjunction of binary relations, so "boilsAt(water,100C,1atm)" could be expressed as the existence of a boiling event, say "?b", such that "boils(?b,water) AND temp(?b,100C) AND press(?b,1atm)".
The expressive power of RDF corresponds to the existential-conjunctive (EC) subset of first order logic [Sowa]. It does not provide means to express negation (NOT) or disjunction (OR). RDF is unusual, for a first order logic subset, in that it allows statements to be made about the relation terms themselves, e.g. "type(floats,physical-relationship) and floats(oil,water)". This kind of expression is more commonly associated with higher order logics, but the use allowed by RDF has first-order semantics.
Through its use of extensible URI-based vocabularies, RDF aims to provide for universal expression of facts about arbitrary subjects; i.e. assertions of named properties about specific named things. A URI can be constructed for any thing that can be named, so RDF facts can be about any such things. And, as noted above, RDF also provides for expression of assertions about unnamed things, which may be fully identifiable in terms of such assertions [TAP-RBD].
RDF itself does not provide the machinery of inference, but provides the raw data upon which such machinery can operate. The Web Ontology Language [OWL] allows more expressive expressions to be built on the basic capabilities of the RDF core language.
RDF is intended to convey assertions that are meaningful to the extent that they may, in appropriate contexts, be used to express the terms of binding agreements.
This goal is explored further in section 2.3 below.
The RDF specification emphasizes the formal structure and meaning of RDF. But there is also a social dimension that is easily overlooked when dealing with such formal aspects.
RDF is a language designed to support the Semantic Web, in much the same way that HTML is the language that supports the original Web. The Semantic Web aims for data to be shared and processed by automated tools as well as by people. To serve this purpose, formal meanings of RDF statements must be defined in a precise manner; this is provided by the RDF Model Theory [RDF-SEMANTICS].
Model-theoretic semantics assumes that the expressions of a language refer to a world but may not describe it completely. Asserting a sentence in a language, on this view, imposes a constraint on the possible ways the world can be: it has at least to make the sentence true. As more knowledge is added - more assertions are made - the collection of possible worlds is reduced. The basic relationship between language and reality is that the more sentences are asserted, the more tightly reality is circumscribed, if none of those assertions are to come out false. The main purpose of the semantics is to make this intuition precise by giving a simple mathematical description of what counts as a 'possible way the world can be' - often simply called a 'possible world' - and of how such a possible world determines the truth-values of sentences. This combination of a world and a mapping between the language and the world is called an interpretation, so model theory might be better called 'interpretation theory'.
The chief utility of such a semantic theory is not to suggest any particular processing model, or to provide any deep analysis of the nature of the things being described by the language (in our case, the nature of resources), but rather to provide a technical tool to analyze the semantic properties of proposed operations on the language; in particular, to provide a way to determine when they preserve meaning.
The RDF model theory treats RDF as a simple assertional language, in which each triple makes a distinct assertion, and the meaning of any triple is not changed by adding other triples. Based on the semantics defined in the model theory, it is simple to translate an RDF graph into a logical expression with essentially the same meaning.
The RDF model theory is couched in the language of set theory simply because that is the normal language of mathematics - for example, the model theory assumes that names denote things in a set IR called the 'universe' - but the use of set- theoretic language is not supposed to imply that the things in the universe are set-theoretic in nature.
RDF/XML documents, i.e. encodings of RDF graphs, can be used to make representations of claims or assertions about the 'real' world.
When an RDF graph is asserted in the web, its publisher is saying something about their view of the world. Such an assertion should be understood to carry the same social import and responsibilities as an assertion in any other format. A combination of social (e.g. legal) and technical machinery (protocols, file formats, publication frameworks) provide the contexts that fix the intended meanings of the vocabulary of some piece of RDF, and which distinguish assertions from other uses (e.g. citations, denals or illustrations).
The technical machinery includes protocols for transferring information (e.g. HTTP, SMTP) and file formats for encapsulating and leballing information (e.g. MIME, XML). A media type, application/rdf+xml [RDF-MIME-TYPE] is being registered for indicating the use of RDF/XML as distinct from some other XML that happens to look like RDF. Issuing an HTTP GET request and obtaining data with a "200 OK" response code is a technical indication that the received data was published at the request URI; but data received with a "404 Not found" response cannot be considered to be similarly published information.
The social machinery includes the form of publication: publishing some unqualified statements on one's World Wide Web home page would generally be taken as an assertion of those statements. But publishing the same statements with a qualification, such as "here are some common myths", or as part of a rebuttal, would likely not be construed as an assertion of the truth of those statements. Similar considerations apply to the publication of assertions expressed in RDF.
To illustrate the importance of treating statements in their appropriate context of utterance, consider the English sentence "I don't believe that George is a clown". It contains the statement "George is a clown", which, considered in isolation, is a distinct assertion. However, considering the whole sentence, this would not be considered as asserting that George exhibits certain comic qualities.
Noting that there is no single human opinion about the truth of some statements, the graph may further contain commentary for human interpreters to indicate the realm of human interpretation that should be applied. This means a graph may contain "defining information" that is opaque to logical reasoners. This information may be used by human interpreters of RDF informaton, or programmers writing software to perform specialized forms of deduction in the Semantic Web.
When a user invokes an application that uses RDF, there is also a social and technical context of invocation that determines some set of RDF assertions that will be assumed to be true: the application itself, and any RDF files that are passed to it. Garbage-in, garbage-out applies: if the initial assumed facts are wrong or meaningless, the results will have little value. No specfic mechanisms for deciding or evaluating the validity of any such assertions are defined here.
Using RDF, 'received meaning' can be characterized as the social meaning of any logical consequences. If you publish a graph G and G logically entails G', and we interpret G' using the same social conventions that everyone agrees could be reasonably used to interpret G, then you are asserting that content of G' as well.
Human publishers of RDF content commit themselves to the mechanically-inferred social obligations. The machines doing the inferences aren't expected to know about all these social conventions and obligations.
Imagine three websites each publishing some RDF:
| (A) http://insult.com/lexicon# asserts the following, and this is all that one can find on the website about that term: |
||
| A:Clown | rdf:type | rdfs:Class . |
| A:Clown | rdfs:Comment | "A foolish person, whose pronouncements are probably ill-considered and not to be taken seriously" . |
(B) http://AngloSaxon.org/lexicon# asserts: |
||
| B:Comic | rdf:subClassOf | <http://insult.com/lexicon#Clown> . |
|
|
||
| C:JohnSmith | rdf:type | <http://AngloSaxon.org/lexicon#Comic> . |
Now, it follows by the formal RDF model theory that these three together entail:
| C:JohnSmith | rdf:type | <http://insult.com/lexicon#Clown> . |
which the person identified as C:JohnSmith might reasonably consider an insult. Why? Not because of the RDF model theory, which merely says he is in some class about which nothing can be formally inferred. However, the rdfs:comment associated with that class name by the owner of that name provides the insulting content, in the social context of web publication, even though it cannot be formally inferred via the RDF inference rules.
But who has insulted the identified person? A merely defined the term; B doesn't mention him in particular, so even A and B together do not constitute a personal insult. And C might argue that although he refers to the person, he only asserts that he is a comic, which is not in itself grounds for a libel suit. However, one could reasonably claim that C is to blame, since C uses not a generic term 'Comic', but a particular uriref which is defined by its owner (B) in a way which is clearly insulting, since B in turn explicitly refers to, and uses, the term defined by A. Thus, C's use of a B-defined term suggests a clear intent by C to convey a meaning defined by B, by virtue of a definition by A, which is insulting.
Note that this argument depends on another social convention of RDF, which is that URIs 'belong to' somebody who has authority and responsibility for defining their meanings. By using the specific name http://AngloSaxon.org/lexicon#Comic instead of some term defined in, say, a glossary of job descriptions, B has explicitly removed his use of the term 'Clown' from any formal connection with people who are entertainers. In order to succeed in his probable intent of making a generic slander against these people, B should have used a term that was defined by someone else, such as:
| <http://www.entertainers.com/glossary#Comic> rdfs:subClassOf <http://insult.com/lexicon#Clown> . |
and then if C had also used this first uriref, then in spite of a similar formal inference chain generating the insulting conclusion about C:JohnSmith, there would be nobody to sue, since now C would indeed have simply made a harmless observation about his occupation, and B's assertion, while indeed arguably offensive, makes no reference to him in particular.
The point of this example is to emphasize that publication of RDF, when considered as a social act, constitutes a publication of some content which is defined by whatever normal social conditions are used by the publishers of any terms in the RDF to define the meanings of those terms, even if those meanings and definitions are not accessible to the formal semantics of RDF; and, moreover, those meanings are preserved under any formally sanctioned inference processes. In a nutshell, the formal entailments of social meanings are themselves part of the social meaning.
[[[NOTE: we're not sure if this final bit is helpful. Jeremy thinks it may thwart some intended OWL inferences. Is this getting too far into murky legalistic territory?]]]
Note that we cannot use a single notion of 'meaning' to say this properly, since of course the formal entailments cannot themselves utilize the social aspects of meaning which are included in informal aspects of the publication, such as the fact that the use of 'Clown' is insulting, which is only mentioned in a comment which is opaque to any likely RDF inference engine or machine processor. Social meanings can be, as it were, transferred or carried by formal entailments, but they cannot be incorporated into the formal entailments. To emphasize this, suppose that B had failed to use rdfs:subClassOf and instead had tried to use his own term:
| B:Comic | B:oneOfThem | <http://insult.com/lexicon#Clown> . |
| B:oneOfThem | rdfs:comment | "This means the same as rdfs:subClassOf" . |
then in spite of the clear social meaning of the comment, there would be no formal inference path from this, taken with the A and C publications, to anything that could be found insulting; so even if C had intended to bad-mouth the person C:JohnSmith, B's stupidity would have thwarted him.
An RDF predicate is defined by an authoritative body implicit in its URI, and misuse by others should not be permited to undermine that authority.
Further, information about the meaning of a statement is primarily dependent on the predicate used. The subject and object contribute to the meaning through the definition of the predicate, but cannot change the fundamental meaning of the predicate. For example, suppose some authority defines the predicate "floats(x,y)" to mean that x floats on y, so that "floats(oil,water)" means that oil floats on water. It is not legitimate for some other party to assert that "floats(water,wood)" means that wood floats on water because they think the original definition doesn't make sense when wood is used as the second parameter.
The RDF core language provides a way to make simple formal assertions, with no way to formally express allowable inferences beyond those entailments that are defined by the RDF formal semantics [RDF-SEMANTICS].
Many inferences are performed by processes, embedded in software implementations, whose validity is not formally demonstrable, and must be assumed or trusted to be socially acceptable. Semantic web languages layered on RDF, such as OWL [OWL], give formal expression to allowable inferences, thus to enable provable deductions by generic software modules to replace some of the individual, ad-hoc implementations.
RDF uses the following key concepts:
The underlying structure of any RDF expression is a directed labelled graph (or multigraph), which consists of nodes and labelled directed arcs that link pairs of nodes (these notions are defined more formally in section 3). The formal semantics for RDF is defined in terms of this graph syntax. An RDF expression is sometimes called an RDF graph. The graph can conveniently be represented as a set of triples, where each triple contains two node labels and an arc label:
Each arc corresponds to a statement that asserts a relationship between the nodes that it links. All the arcs labelled with the same predicate thus form a single dyadic relationship, and the RDF graph can be informally viewed as a set of graphs, one for each relation, overlaid on top of one another with the labels showing which relation each arc has been derived from (cf. [Sowa2]). The meaning of an RDF graph is the conjunction (i.e. logical AND) of all the statements that it contains.
Nodes in an RDF graph are labelled with URIs with optional fragment identifiers (URI references, or URIrefs), literal strings, or nothing at all. Arcs are labelled with URIrefs. (See [URIS], section 4, for a description of URI reference forms, noting that relative URIs are not used in an RDF graph. See also section 3.1.)
The label on a node indicates what that node is meant to represent. The label on an arc names the relationship that is asserted to hold between the nodes connected by that arc. Some URIrefs may indicate web resources, and a node thus labelled denotes that resource. Other URIrefs may represent abstract ideas or values rather than a retreivable Web resource. RDF thus leverages the universal naming space of URIs [URIS].
[[[This section to be reviewed based on WG finalization of literal semantics.]]]
Literals are used to indicate values in an RDF graph by means of a lexical representation. They are typically used to represent things like numbers, strings and other common kinds of value. Anything that can be represented by a literal could also be represented by a URI, but it is often more convenient and/or intuitive to use literals.
Literals may appear in the object position of RDF statements, and nowhere else.
Further information about literals may be found in section 3 below on graph syntax.
Literals may be typed or untyped. A typed literal explicitly indicates the value denoted by indicating a datatype according to which the lexical form is interpreted. Datatyping is discussed further in the next section (Datatypes).
An untyped literal ....
[[[details pending WG discussion of untyped literals]]]
Datatyping in RDF is the use of a datatype to associate a lexical form with a denoted value.
For example, the datatype xsd:integer might be used to associate the numeral string "10" with the integer value 10, or the datatype xsd:date might be used to associate the string "2002-09-30" with the 30th day of September in the year 2002 according to the Gregorian calendar.
RDF does not, of itself, define any native data types. That is, the core RDF language does not define any particular correspondence between lexical forms and values; there is no built-in concept of numbers or dates or other common values. Rather, it defers to datatypes that are defined separately, and identified with URIs. In particular, the predefined XML Schema datatypes [XML-SCHEMA2] are expected to be widely used for this purpose.
A datatype mapping is a set of pairs whose first element belongs to the lexical space of the datatype, and the second element belongs to the value space of the datatype.
A datatype mapping satisfies the following properties:
For example, the datatype mapping for the XML Schema datatype xsd:boolean, where each member of the value space (represented here as 'T' and 'F') has two lexical representations, is as follows:
Value Space {T, F} Lexical Space {"0", "1", "true", "false"} Datatype Mapping {<"true", T>, <"1", T>, <"0", F>, <"false", F>}
Datatypes are used in RDF for the explicit designation of typed literals. A typed literal is a pair where the first element is a datatype URI and the second is a member of the datatype's lexical space. This serves to unambiguously identify a member of the value space of the datatype.
For example, the typed literals which can be defined for the XML Schema datatype xsd:boolean are as follows:
Typed Literal Datatype Mapping Value <xsd:boolean, "true"> <"true", T> T <xsd:boolean, "1"> <"1", T> T <xsd:boolean, "false"> <"false", F> F <xsd:boolean, "0"> <"0", F> F
As noted previously, typed literal indicates a datatype URI and lexical form, which
RDF datatyping provides only for use of externally defined datatypes, and does not of itself provide any mechanisms for defining new datatypes. The defining authority associated with a datatype URI is responsible for specifying the corresponding datatype mapping, and knowledge of this mapping is presumed to be built-in to applications that process datatypes in RDF data. RDF applications that have no such knowledge can preserve information in the RDF graph by maintaining the typed literal pairing, and treating it as an opaque value.
RDF has a specific serialization syntax based on XML [RDF-SYNTAX].
Only the XML syntax is normatively specified and recommended for use to exchange information between Internet applications: other syntaxes for RDF graphs are possible, and may be widely used (e.g. [NOTATION3]), but are not covered by this recommendation.
RDF uses URIs to label resources and properties. Certain URIs are reserved for use by RDF, and may not be used for any purpose not sanctioned the RDF specifications. Specifically, URIs with the following leading substrings are reserved for RDF core vocabulary:
Used with the RDF/XML serialization, these URI prefix strings correspond to XML namespaces [XML-NS] associated with the RDF core vocabulary terms.
NOTE: these namespace URIs are the same as those used in earlier RDF documents [RDF-MS] [RDF-SCHEMA].
[[[NOTE FOR REVIEWERS: Some terms in these namespaces have been deprecated, some have been added, and some RDF schema terms have had their meaning changed. We invite community feedback regarding the relative costs of adopting these changes under the old namespace URIs vs creating new URIs for this revision of RDF.]]]
Vocabulary terms in the rdf: namespace are listed in section 3.4 [[[check this]]] of the RDF syntax specification [RDF-SYNTAX].
Vocabulary terms defined in the rdfs: namespace are defined [[[where?]]] in the RDF schema vocabulary specification [RDF-VOCABULARY].
[[[This section, particularly how nodes and node labels are handled, is not completely in sync with the current Model Theory WD -- coordinate with MT editors, and review after next MT WD]]]
This section defines the RDF graph syntax. The RDF graph is sometimes referred to as the (data) model of RDF (see the RDF Primer [RDF-PRIMER], and RDF Model & Syntax [RDF-MS]). In brief, the RDF graph is a directed graph with labelled edges and partially labelled nodes.
A goal of this section is the precise definition of equality between RDF graphs. This benefits interoperability (two conformant implementations are more likely to be practically interoperable if they have a precise conception of the way in which they are the same). It is required for the specification of the RDF Test Cases [RDF-TESTS], which depend on testing equality of RDF graphs for their execution. It is required by the RDF Model Theory [RDF-SEMANTICS] which assigns the same meaning to any pair of equal RDF graphs.
Note: Many RDF applications and frameworks do not need to implement RDF graph equality. They do need to respect equality when assigning meaning to RDF graphs.
The specification of the RDF graph commences with the labels used in the graph, which can be URI references, string literals, or XML literals; equality is defined for each. It then proceeds to describing arcs (triples), a complete graph and graph equality.
Within RDF, URI reference labels may contain those characters which are disallowed according to RFC 2396 [URIS] and [RFC-2732]; the disallowed characters are the control characters #x0 to #x1F and #x7F, space #x20, the delimiters '<' #x3C, '>' #x3E and '"' #x22, the unwise characters '{' #x7B, '}' #x7D, '|' #x7C, '\' #x5C, '^' #x5E and '`' #x60, as well as all characters above #x7F.
[Definition: An RDF URI reference is a string that can be converted to an absolute URI reference by escaping all disallowed characters as follows: ]
An RDF URI reference must be in Normal Form C [NFC].
Two RDF URI references are equal if and only if they compare as equal, character by character, as Unicode strings. A URI reference label is not equal to a string literal label or an XML literal label.
Note: RDF URI references are compatible with the anyURI datatype as defined by XML schema datatypes [XML-SCHEMA2], constrained to be an absolute rather than a relative URI reference, and constrained to be in Unicode Normal Form C [NFC] (for compatibility with [CHARMOD]).
Note: RDF URI references are compatible with International Resource Identifiers as defined by [XML Namespaces 1.1].
See the following test cases, per [RDF-TESTS]:
An RDF literal is one of:
Two RDF literals are equal if and only if one of the following:
A string literal label in an RDF graph is composed of a Unicode string [UNICODE] that is in Normal Form C [NFC], and a language identifier (possibly empty) as specified below.
Two string literals are equal if both components are equal. The Unicode string components are compared on a character by character basis. The language tag components are compared in a case insensitive fashion.
Allowable language identifiers are the legal values for
xml:lang as specified by section
2.12, Language
Identification, in [XML],
or the empty string "".
Equality of language identifiers (as specified in
[RFC-3066]) is defined by case
insensitive character by character comparison.
Note: This direct comparison between language identifiers is appropriate for the purpose of defining equality between RDF graphs, but is linguistically naive. [RFC-3066] suggests more advanced comparison techniques.
Note: The empty language tag is used for literals for which no language information is available.
Note: Literals beginning with a composing character (as defined by [CHARMOD]) are allowed however they may cause interoperability problems, particularly with XML version 1.1 [XML 1.1].
See the following test cases, per [RDF-TESTS]:
[[[Subject to WG disposition of test cases]]]
Within an RDF graph, an XML literal is a Unicode [UNICODE] string paired with a language identifier. The string is well-balanced, self-contained XML element content [XML].
An XML literal, with non-empty language identifier, can be used to form an XML document by concatenating the five strings:
The resulting Unicode string is then encoded in UTF-8.
When the language identifier is the empty string, the corresponding XML document is formed by enclosing the Unicode string of the XML literal with "<tag>" and "</tag>" and encoding the resulting string in UTF-8.
No escaping is applied in either process. The choice of tag is arbitrary.
This resulting XML document corresponding to the XML literal is a well-formed XML document [XML] that also conforms to XML Namespaces [XML-NS].
Note: If compatibility with XML version 1.1 is desired, then XML literals in RDF graphs must be restricted to those that are fully normalized according to [XML 1.1].
The exclusive canonicalization of an XML literal is formed by:
If two XML literals are equal then:
This specification, above, gives necessary conditions for the equality of XML literals. The RDF Test Cases [RDF-TESTS] treat these necessary conditions as also sufficient.
Implementations are free to add additional sufficient conditions for equality. If two XML literals compare equal according to an implementation then they must compare equal according to this definition, but not conversely. In particular, XML comments may be treated as significant, and namespaces that are in scope but not visibly utilized (as defined by [XC14N]) may be treated as significant.
[[[Is there a need for a longer non-normative appendix on implemenation issues for XML literals? This could discuss (a) minimal implementations, for which equality is not needed, and where the set of namespaces and namespace prefixes can be fixed in advance (b) the correct and incorrect use of character by character equality for XML literals. Should there be test cases for issue rdfms-xml-literal-namespaces? ]]]
See the following test cases, per [RDF-TESTS]:
[[[Subject to WG disposition of test cases]]]
Within an RDF graph, a typed literal is a triple:
Note to WG: as we decided on Sept 13 we have lexical values here. My understanding was that the WG wanted, at the abstract syntax level, *no* expectation that an RDF processor could do any datatype specific processing.
On reflection, and looking at early e-mail feedback, I thought that I could define the notion of the value of the typed literal, while highlighting that having a value is not required by the abstract syntax.
This requires that the datatype URI refers to a datatype. And I end up with the dread phrase "implementation dependent".
The tentative reference to the model theory has gone, but maybe needs to be put back.
Pat could then simply invoke this function to get to the denotation of the literal.
Such a function need not impact on equality, which is defined here purely lexically.
I understood that WG consensus would form more easily around including a language tag in the typed literals - I remain a little unhappy with this.
The datatype URI refers to a datatype.
For XML Schema
built-in
datatypes, URIs such as <http://www.w3.org/2001/XMLSchema#int>
are used. There may be other, implementation dependent, mechanisms by which URIs
refer to datatypes.
The typed value associated with the typed literal is found by applying the datatype mapping associated with the datatype URI to the lexical form. This mapping fails if the lexical form is not in the lexical space of the datatype associated with the datatype URI.
However, the abstract syntax does not presuppose such datatype specific processing.
Two typed literals are equal if and only if all of the following hold:
Note: If compatibility with XML version 1.1 is desired, then lexical forms must be restricted to those that are fully normalized according to [XML 1.1].
See the following test cases, per [RDF-TESTS]:
[[[Subject to WG disposition of test cases]]]
An RDF graph is defined using a set of nodes. Many of the nodes are blank, and some of the nodes are labelled with RDF literals or RDF URI references, i.e. there is a partial labelling function from the set of nodes to the union of the set of RDF literals and RDF URI references.
A tidy set of nodes is one in which no two nodes have equal labels. A tidy set of nodes may have any number of distinct blank nodes.
Two nodes are equal if and only if they are the same node. In particular, two different blank nodes are not equal.
An RDF triple describes an arc in an RDF graph. It contains three components:
The set containing the subject and object nodes of a triple is tidy (per definition in section Nodes).
The subject must not be labelled with an RDF literal.
Two RDF triples are equal if and only if their subjects are equal, their predicates are equal, and their objects are equal.
An RDF graph is a set of RDF triples.
The set of nodes of an RDF graph is the set of nodes that are either subject or object of some triple in the graph.
The set of nodes of an RDF graph is tidy (per definition in section Nodes).
[[[Suggestions of a standard graph theory text which treats digraphs as primary would be welcome.]]]
Note: The definition of an RDF graph diverges from the definition of a directed graph in a standard text such as [[[missing ref]]] in that: (a) all nodes must be in at least one arc; (b) all the arcs are labelled; (c) some of the nodes are labelled; (d) labels on nodes are required to be distinct; (e) some labels are shared between nodes and arcs.
Two RDF graphs are equal if and only if they are isomorphic. An RDF graph isomorphism is a directed graph isomorphism that respects the labels on both arcs and nodes.
An RDF Graph isomorphism I between two graphs G and G' is a bijection between the nodes of G and the nodes of G', such that:
for all nodes n, s, o in G and all RDF URI references p.
[[[This subsection normatively depends on CHARMOD, currently a last call working draft. If CHARMOD has not reached the appropriate recommendation status as this document progresses down the recommendation track, this section will be deleted.]]]
For the processing of character data that can be represented in different ways, RDF processors are required to conform to Early Uniform Normalization, as described by Character Model for the World Wide Web 1.0 [CHARMOD].
How should RDF treat a URI reference with a fragment identifier? Conventional web architecture has that the meaning of a fragment identifier is dependent on the MIME type of a resource that is obtained by dereferencing the URI part. URIs without fragment identifiers are generally presumed to map to some resource for which a Web representation (or several) can be retrieved. But RDF has no concept of a fragment identifier separate from a URI: RDF treats a URI reference as an opaque identifier that denotes some resource [RDF-SEMANTICS]. Further, an RDF resource identifier may denote something that is not web-retrievable; e.g. a car, or a Unicorn.
These apparently conflicting interpretations can be reconciled if:
This provides a handling of URI referencess and their denotation that is consistent with the RDF model theory and usage, and also with conventional web behaviour. This approach somewhat extends the idea of a "fragment" or "view" beyond the common idea (when handling web documents) that it is a physical part of a containing document.
In view of this, it is reasonable to consider that URIs without fragment identifiers are most helpfully used for indicating web-retrievable resources (when used in RDF), and URIs with fragment identifiers are used for abstract ideas that don't have a direct web representation. This is not a hard-and-fast distinction, as the line between resources having or not having a web-retrievable representation is sometimes hard to draw precisely.
The RDF/XML syntax uses QName syntax [XML-NS], section 3, to identify various resources, notably RDF properties. But the RDF graph syntax contains only URI references, and does not recognize QName forms.
Mostly, QNames are handled by the mapping between RDF/XML documents and RDF graph syntax. But there are some occasions where an RDF writer needs to know the correspondence between QNames and URI references (e.g. when using a typed node production). The mapping is described in [RDF-SYNTAX], sections 3.1.2 or 3.1.4.
This document contains a significant contribution from Pat Hayes, Sergey Melnik and Patrick Stickler, under whose leadership was developed the framework described in the RDF family of specifications for representing datatyped values, such as integers and dates.
The editors acknowledge valuable contributions from the following:
Jeremy Carroll thanks Oreste Signore, his host at the W3C Office in Italy and Istituto di Scienza e Tecnologie dell'Informazione "Alessandro Faedo", part of the Consiglio Nazionale delle Ricerche, where Jeremy is a visiting researcher.
This document is a product of extended deliberations by the RDFcore working group, whose members have included:
This specification also draws upon an earlier RDF Model and Syntax document edited by Ora Lassilla and Ralph Swick, and RDF Schema edited by Dan Brickley and R. V. Guha. RDF and RDF Schema Working group members who contributed to this earlier work are:
[[[For reviewers' reference. This appendix will be removed on final publication.]]]
$Log: rdf-concepts.html,v $ Revision 1.12 2002/10/17 17:19:32 graham Minor editorial changes. Added link and email for GK. Revision 1.11 2002/10/17 16:22:29 graham Jeremy's changes - lock relinquished: - name to include middle initial, e-mail and links - added some of Frank's text to 2.4.1, with new ref to Sowa2 - updated 3.1 URI Ref to be very like XML Namespaces 1.1 section 7 IRI - updated 3.2 using majority text with little bits from minority text - added acknowledgement to host in Pisa - added Sowa2 ref Revision 1.10 2002/10/14 14:00:32 graham Minor updates; hand lock to Jeremy Revision 1.9 2002/10/10 14:55:15 graham Folded in co-editor review comments, added reference to OWL. Revision 1.8 2002/10/07 15:16:59 graham Add 'latest' version of RDF concepts Revision 1.7 2002/10/02 11:39:44 graham Incorporate revised wording on formal semantics into section 2.3.1 Revision 1.6 2002/09/30 17:22:17 graham Fold in some further comments from Pat Hayes Revision 1.5 2002/09/30 12:11:05 graham Remove some superfluous comments and reference Revision 1.4 2002/09/30 11:58:40 graham Update document links following move to new directory Revision 1.3 2002/09/30 11:38:20 graham Incorporated material from datatyping draft, per issue 010-DatatypingConcepts Revision 1.2 2002/09/30 10:09:07 graham Add new sections for literals and datatyping Address issue 008-InteractionUnclear Address issue 011-DatatypingAcknowledgement Address issue 012-AssertionConflictingUse Address remaining non-syntax items from issue 013-Various Regenerate table of contents Revision 1.1 2002/09/30 09:32:01 graham Update document and move to RDF-Concepts directory Revision 1.9 2002/09/28 17:30:42 graham Rework section 2.3 to take account of comments from Pat Hayes and Tim Berners-Lee, and incorporating a sanitized version of Pat's example of formal entailment of social meaning. Revision 1.8 2002/09/26 16:55:46 graham Fix up previous document link Revision 1.7 2002/09/26 16:30:14 graham Apply edits for issue 007-Meaning-machinery Revision 1.6 2002/09/26 13:32:26 graham Apply edits for issue 003-ModelTheory.html Revision 1.5 2002/09/26 13:15:15 graham Apply edits for issue 002-InconsistentAssertions Revision 1.4 2002/09/26 12:36:27 graham Apply edits for issue 001-Editorial Revision 1.3 2002/09/26 12:13:02 graham Update previous version links Revision 1.2 2002/09/26 12:01:36 graham Re-import published WD as editors' working copy ---