- From: Al Gilman <asgilman@iamdigex.net>
- Date: Sun, 18 Nov 2001 11:27:07 -0500
- To: uri@w3.org
- Message-Id: <200111181621.LAA2532858@smtp1.mail.iamworld.net>
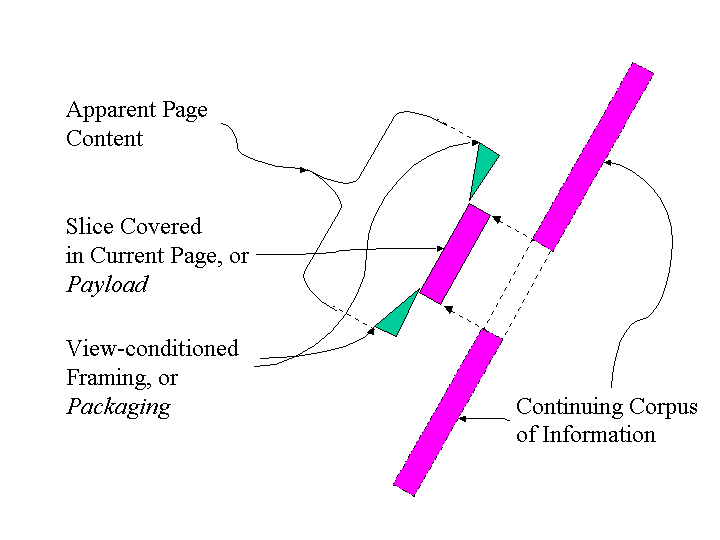
** well said. What David Durand said. The scheme name that dominates current Web traffic does cue proper methods for recovery, and the value added that users extract from the web depends on this rather heavily. ** of course, even the 'identifier' notion is unreliable in fact. It is not true that all URIs are identifiers in any useful semantic sense. Anything that has identity may be indicated by a URI, but that is not necessary. It is also possible by URI to indicate some stuff with articulable properties [not including among them its identity]. Search URLs are much better explained as clauses restricting a kind of stuff sought, rather than articulating a reference to a thing with identity. ** semantics: URIs guide the actualization of potential utility possessed by resources. A resource is something of potential utility. In that phrase, 'thing' in 'something' has to be construed broadly. Actually, a resource is sometimes a thing, like the OED, but equally sometimes it is a stuff, like groundwater in a watershed. What characterizes the 'resourcefulness' of the groundwater is not its identity but its quantity and purity properties. Likewise for information resources. Anything which will likely increase your return rate on a direct-mail solicitation is a valuable information resource. And there are ways to refer to such a resource which are the more effective for not identifying the data that is eventually bound to the transaction. URIs are indications (utterances encoded in data) which add value through incremental specificity (information) which keys or focuses the application of a method for actualizing that utility by exploiting the resource. None of this is specific to 'things' of definite identity. It works equally well for 'stuffs' where the indication corresponds to a relatively localized distribution on the domain of "all manner of stuff." But not necessarily compact in the sense of having a definite boundary. A probability density function with a small standard deviation is equally as good a semantic definition of a resource bound to a URI as is an identified thing. And the "kind of stuff" variant is in heavy use on the web today, and enjoys a non-trivial market share of the value added by Web traffic [hits, transactions] as we speak. Search URLs are useful in that they restrict the manner of stuff sought by a [network remote] agent, while leaving the identity of what the search agent references in its response up to the search service. They describe the kind of stuff that the customer would find useful. The server fills in the identity of things matching the stuff specification as a function of the service-providing transaction. Semantically, it is closer to universal truth to describe URIs as a Unified-syntax Resource Indication than Uniform Resource Identifier because the rules of identification for resources or of binding URIs to resources are neither one uniform in any way across all of the in-use and highly useful uses to which URIs are being put at this time. In personal fitness, there is the cliche "use it or lose it" of muscular strength or tone. In the ecology of language, the same holds for distinctions or constraints. The restriction of URI-referends to things with identity does not add value, has not been used, and historically could be viewed as 'lost.' In terms of the linguistic ecology of URIs, the constraints that are enforced add all the value that is needed [for the whole class] and it is unsafe to think that there is any more narrowness to the class than what there is in the best commercial practice, that is to say across the breadth of practice which is consistently adding value for end-users. For all URIs: they don't collide on string comparison; in addition they all have a scheme property. Commonly this scheme property cues some proper methods (for how to exploit the resource). Also commonly, they are themselves resources used in constructing references. That is to say, they create a data encoding usable within a dataset to connect the dataset with something not contained within the dataset. This may be more data, an active service, or a climate of knowledge which is valuable in interpreting the data. Else, anything goes. It is long past time that we should have lost the idea that URIs only indicate resources of definite identity, only things and not stuffs, from our baseline of working hypotheses about this most excellent invention. It is counter-productive and unnecessary. There is, in many circumstances, value to be added by crystallizing knowledge into definite entities. But not across all valuable-to-reference-by-URI stuff. So just don't go there. ** to return to namespaces There is an example of this in the problem that originated this thread. Let me try to restore the topic. There is no consensus on how the knowlege bundle proper to a namespace is to be bounded. The position closest to achieving consensus is the position that namespaces are to support parsing, and that distinguishing XML element and attribute categories is their whole job. When this was the subject of a large flamewar earlier (see xml-uri archive) I concluded that it was best to put a reference to a richer trove of knowledge, whose application to the processing of the data at hand is optional, in a distinguished citation-role so that the JustDoIt processors could do their thing expeditiously without the appearance of ignoring anything necessary to their task. Nothing since has changed that view. ** bracket your usage: A useful general idea is that every communicated dataset should be viewable as semi-autonomous, having a nature both as a particle, a complete instance of a package type, and a sample from a larger fabric. See the attached diagram for the "page as packaged slice" view of a MIME or HTTP etc. communicated data collection. To go with these two horizons of resource, there are two types or knowledge-bundles that pertain. + The JustDoIt definedType: This is what you nominally must conform to to comprehend or process the data at all right. It refers to a definite set of rules or constraints. Commonly this will be a well-known type such that there is time to learn the constraints out of band and to implement their satisfaction in hard code in processors. + The AllAboutMe StartPointer: This is a reference supporting indexed access into a world of knowlege related to the usage in the current dataset. The consumer of the data is free to browse in the knowledge space and will find starting with the cited index key facilitates the recovery of relevant stuff. The precise relationship of the knowledge to the data is to be discovered by processing both the Knowledge representation(s) and the present data together; the citation is simply an efficiency aid in locating the most relevant stuff. There is no implied finiteness to this reference, by the nature of the reference semantics. It just provides a focus, a centering. Scoping at that point is at the option of the consumer. It would be a solid step forward if everyone can agree that both of these notions are useful, and it is constructive to have distinguisned bindings for both of them in many many contexts where data [sub-] collections are shared between [autonomous -- under differing control regimes] computational processes, If that were agreed, then it is secondarily useful to agree that we will use namespaces in XML for the purpose of minimally extending the construction of the JustDoIt type, and introduce description-type-fanout and elective knowledge references via a recognizably different mode of reference designed to support the AllAboutMe function. ** Do use RDDL, but not bound to the namespace name. The namespace name is a bad place to refer to RDDL. On the other hand, the road to a WSDL resource is an excellent place to use RDDL to adjoin supplemental views. The path from an UDDI or similar service-discovery resource to a WSDL description is an excellent place to use RDDL. The idea that the characterization of a service offering should have the structural capability to use a polyglot sheaf of descriptive views of the service is something that both the service provider and consumer should be expected to view as a positive feature. The RDDL-indexed bundle of views is most useful when it is rather specific, applicable to a relatively small extension in terms of XML instances. This is strongly in tension with the desire for namespaces to be very widely used, and for processors to know what you need to know to process an XML instance successfully without a lot of ancillary-document processing. So the preponderance of the value added by RDDL is in cases where its fanout exceeds the JustDoIt type specification, and so it is wise to define both of the above modes of reference as available and distinct format features, and use RDDL in the richer chain where the extent to which the knowledge cited is applied is left open for recipient decision. A contract should be totally unambiguous as to what descriptive clauses it binds the parties to. A prospectus should not. Enjoy. Al PS: description of the attached image: In the picture, there is a "payload" or "slice covered in the current page" of information which is extracted from a larger "continuing corpus of information." This is wrapped in "packaging" which forms a "view-conditioned framing" for the payload. In many framed websites the main frame is basically payload and the rest is packaging. The framing identifies the site and provides links to site tools and other off-page resources. Some links are always there but some have to be added as the scope of the page in the payload domain is drawn smaller and smaller. The whole point here is that to accomodate different client side interface capabilities (such as large vs. small screens) and network data rates, the amount of material addressed in one nominal page must be allowed to vary, and the URIs will vary along with this. At 07:05 AM 2001-11-17 , David G. Durand wrote: >Hi Roy! > >This has my views as to why URNs were not a waste of time. I've included >stuff that you surely know better than I do, but explained more >sympathetically. I'm trying to talk to the larger group, not down to you. > >At 12:40 PM -0800 11/16/01, Roy T. Fielding wrote: >> > Are you saying that HTTP URLs are also URNs? >> >>No, URNs are only those URI that start with a "urn" scheme. What I said is >>that HTTP URLs are identifiers, and hence names, and therefore capable of >>being a symbolic replacement for any other identifier, including URNs. > >I was involved in the URN stuff for a long time, though peripherally. I >stopped eventually because the other folks were more than competent to move >things along without me, and because, like you, I got tired of the endless >discussions like this. Discussions in which I've seen almost no-one change >their minds, even about the problem's definition, because of the very wide >divergences in perspective the people bring to the problem. > >However, it's been some years, so here's my take on the issues and positions. > >The nature of the resource identified is a red herring. The question is >what method, if any, is suitable for obtaining the representation of a >resource. > >This is the place that URNs, http: URLs, and other URL formats _may_ be >seen to differ. > >> > Does that mean that >> > all of the work being done by the URN WG is for nothing? Are they >>> just wasting their time, since we already have HTTP URLs and can >>> just use those? >> >>I have been saying that for the past eight years. That doesn't mean it is >>a waste of their time, only that the solution to persistent naming isn't >>obtained merely by changing the scheme name. > >It is indeed possible to use any string as a name, and any anme must be >supported by a social/technical infrastructure that defines its properties >and utilities. > >The http: scheme is different from the ftp: scheme, although both can serve >as a name infrastructure (given social/technical support). The difference >between them is that each has a formal, standard definition of how to >request a digital representation (message body/file contents) for a given >resource. The protocol for FTP is very limited, supporting binary transfer >of data, and character conversion. The protocol for http: is very rich, >supporting independent data format, and character encoding conversions as >well as caching, etc. These schemes differ in their technical >infrastructure, but they both provide a mapping from identifiers to data, >based on a standard protocol. > >A user-agent is free in principle to resolve http: URLs in any convenient >way. However, if that user agent resolves a URL in a way which returns >different results than would be obtained by using HTTP, then that agent can >be plausibly said to be broken. A great deal of HTTP 1.1 is devoted to >enabling "correct" caching of data by arbitrary programs, within parameters >of correctness as set by the server and conveyed by HTTP headers. > >In other words one is free to resolve http: URLs by any means one wants to >use, but use of any other method than HTTP is not standardized, and thus is >not interoperable between applications. At some future date, there may some >"redirection registry" that will resolve old URLs in a canonical way >(perhaps by date?). > >URNs were created to satisfy a different set of needs, and, in consequence, >make a radically different tradeoff between social and technical >infrastructure. URNs are specifically intended for names that are intended >to be _persistent_ and _location independent_. > >"Persistent" means that there is no upper bound on the lifetime of a URN -- >librarians like to think in terms of decades to hundreds of years. To >guarantee that a name won't be re-used over that kind of timespan is not >basically a technical issue, but a social one, because our software seems >almost certain to undergo radical change over that timescale. > >"Location independent" means that when you assign a URN, you are naming >something, but _not_ picking a preferred protocol for fetching it. You can >commit to persistence with http:, and the w3c advocates this, but currently >this is rarely done. There are social obstacles, as well, as there's no >guarantee that you can keep a domain name forever; nor is there a standard >way to indicate to software that HTTP is _not_ a suitable protocol for >fetching the resource at the end of an http: URL. And of course, it's >possible that maintaining a web server will no longer be the preferred way >to provide a resource, because of software changes. > >Of course, resolving names is nice, and there is a network protocol (NAPTR) >that can be used to turn a URN into a URL -- using any scheme. That's >great, because it provides a technical infrastructure for making the >retrieval of URNs easy, _if the owners choose to use it_. The point of a >URN is to have a scheme that exploicitly warrants the use of arbitrary >retrieval mechanisms. > >There was another comment that I wanted to respond to: > >At 1:05 PM -0800 11/16/01, Roy T. Fielding wrote: >>The only chaos I have seen is in the writings of more recent specifications >>that ignore the research and experience of the Web developers in favor of >>their own personal view of an ideal world. When they implement something >>that works and has the same expressive power as the Web itself, then I will >>take their writings seriously. > >A lot of the issues raised in the URN debate were raised by people from a >library background, and librarians have been devising reference systems for >a long time. > >I could counter your ad-hominem argument by saying "I'll listen to the web >folks when they've created a URL that was usable after 50 years." I'm not >saying that, and the IETF groups didn't either, because it's not >productive. Both perspectives have good ideas and techniques to offer. > >URNs are just names with an agreement in advance that any resolution method >that "works" is acceptable, where "works," like the notion of "resource" is >a fuzzy one, ultimately defined by human beings. > > -- David >-- >------------------------------- >David Durand >Chief Scientist, Scholarly Technology Group >Adjunct Associate Professor, Computer Science. >Brown University >Cell: 401-935-5317 >email: David_Durand@brown.edu > >commercial .sig: >VP, Software Architecture >ingenta plc >
Attachments
- image/gif attachment: PageAsView.gif
Received on Sunday, 18 November 2001 11:21:48 UTC