- From: <hans.teijgeler@quicknet.nl>
- Date: Tue, 15 Feb 2022 21:00:30 +0100
- To: "'Hugh Glaser'" <hugh@glasers.org>, "'Frederik Byl'" <frederik.byl@gmail.com>
- Cc: "'Semantic Web'" <semantic-web@w3.org>
- Message-ID: <052a01d822a6$af6d96e0$0e48c4a0$@quicknet.nl>
Hi Hugh and Frederik,
I will try hard to give a useful answer, but keep in mind that I am an
engineer who, by the whims of fate, entered the IT world, then the data
modeling world, and finally in the RDF world.
That took three decades. And still I learn, so don't expect a scholarly
perfect RDF story. RDF and SPARQL are to me useful means to an end, not a
religion.
My story is about data in the process industries (oil & gas, chemicals,
food).
I have discovered that when you use a proper upper ontology on top of RDF
much of the intricacies of RDF aren't relevant anymore.
As I wrote to Melvin, RDF almost invites sloppiness in data modeling. That,
imho, also is true for his JSON creed. As long as the syntax is OK any
validator will accept your code.
Having said that, my tutor in data modeling, Matthew West, used to say "You
can't prevent people to do stupid things". That holds for most, if not all,
systems. But at least you can assist the modeler in preventing them.
With a team from various companies in the process industries we have worked
for ten years on a generic upper ontology, published as ISO 15926-2
<https://15926.org/topics/data-model/index.htm> . It has 200+ entity types.
Each piece of information in the ISO 15926 world is a descendant of that
upper ontology (must sound horrible to most geeks).
Below I show some quotes from ISO 15926-2 that may help in positioning the
standard:
QUOTE
ISO 15926 is an International Standard for the representation of process
plant life-cycle information. This representation is specified by a
generic, conceptual data model that is suitable as the basis for
implementation in a shared database or data warehouse.
The data model is designed to be used in conjunction with reference data:
standard instances that represent information common to a number of users,
process plants, or both. The support for a specific life-cycle activity
depends on the use of appropriate reference data in conjunction with the
data model. [HT] For the process industries that is ISO 15926-4 - Reference
Data Library <http://data.15926.org/rdl/> (try entering PUMP); use, for
example, SNOMED for health registration purposes
To enable integration of life-cycle process plant information the model
excludes all information constraints that are appropriate only to
particular applications within the scope.
Data integration means combining information derived from several
independent sources into one coherent set of data that represents what is
known. Because the independent sources often have overlapping scopes,
combining their data requires the common things to be recognized, duplicate
information to be removed, and new information represented. To succeed in
the role of integration, the data model must have a context that can
include all the possible data that might be wanted or required.
Relationships and activities are represented by entity data types.
UNQUOTE
ONTOLOGIES
In ISO 15926-7 the concept of Templates is defined and in ISO 15926-8
implemented in RDF and OWL. Templates are defined in Template
Specifications that can be found here
<https://15926.org/home/15926_template_specs.php> .
Each such specification shows:
* a graph, based on entity types from the ISO 15926-2 upper ontology
* a definition of that graph in First Order Logic
* a signatue, with a generic code and an example instantiation.
Each template type is in fact an elementary ontology, just like Melvin
showed his
<script type="application/ld+json">
{
"@id": "http://dbpedia.org/resource/John_Lennon",
"name": "John Lennon",
"born": "1940-10-09",
"spouse": "http://dbpedia.org/resource/Cynthia_Lennon"
}
</script>
but ours is firmly anchored in the upper ontology.
An example:
GENERIC
:UUID_IN-PTYST-100
rdf:type tpl:IndividualHasPropertyWithValue
<https://15926.org/home/templatespecs/IN-PTYST-100.xml> ;
rdfs:label "[EssentialType] individual [hasPossessor] has a
[hasPropertyType] of [valPropertyValue] [hasScale]"@en ;
tpl:hasPropertyPossessor "ID"^^dm:PossibleIndividual ;
tpl:hasPropertyType "ID"^^dm:ClassOfProperty ;
tpl:valPropertyValue ""^^xsd:decimal ;
tpl:hasScale "ID"^^dm:Scale ;
meta:valEffectiveDate "yyyy-mm-ddThh:mm:ss.sZ"^^xsd:dateTime .
EXAMPLE - Vessel V-101 has a mass of 30.57 Metric Ton
ex:fcbfda39-4d1a-4047-b4ca-45ab8d44fca4
rdf:type tpl:IndividualHasPropertyWithValue ;
rdfs:label "[VESSEL] individual [V-101] has a [MASS] of [30.35]
[METRIC TON]"@en ;
tpl:hasPropertyPossessor ex:847931fd-eade-4beb-b07d-a9e889611c19 ; #
V-101
tpl:hasPropertyType rdl:RDS353339 ; # MASS
tpl:valPropertyValue "30.35"^^xsd:decimal ;
tpl:hasScale rdl:RDS2229868 ; # METRIC TON
meta:valEffectiveDate "2021-07-27T10:19:00Z"^^xsd:dateTime .
Templates can be specialized with subclasses of the entity types in the
signature, e.g. the version for MASS:
:UUID_IN-PTYST-100_017
rdf:type tpl:IndividualHasPropertyWithValue ;
rdfs:label "[EssentialType] individual [hasPropertyPossessor] has a
[MASS] of [valPropertyValue] [hasScale]"@en ;
tpl:hasPropertyPossessor "ID"^^dm:PossibleIndividual ;
tpl:hasPropertyType rdl:RDS353339 ; # MASS
tpl:valPropertyValue ""^^xsd:decimal ;
tpl:hasScale "ID"^^dm:Scale ;
meta:valEffectiveDate "yyyy-mm-ddThh:mm:ss.sZ"^^xsd:dateTime .
So you can use this template for all individuals in the universe (provided
that you declared them) and for all 383 Properties
<http://data.15926.org/dm/Property> (‘Quantities’) we have in the RDL.
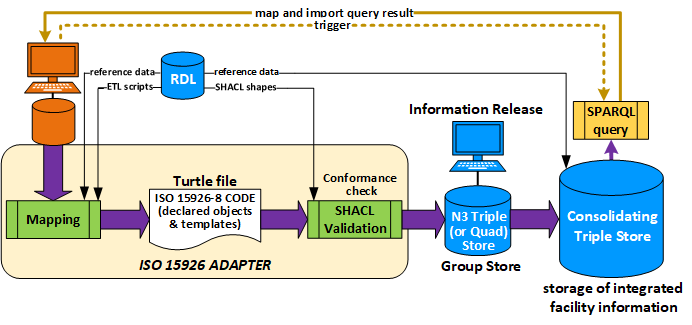
MAPPING
The concept of ISO 15926-8 is shown in following diagram:
All applications that are used during the, say, 50 years of existence of a
process plant (or other facility, like an airplane) produce data and use
data. The produced data are mapped to declarations and templates instances
and stored in a consolidating triple or quad store.
The mapping process is from an unknown proprietary data collection to
standard templates. It is here that we still need to make progress. We
think that some form of AI, ML, NLP, or whatever esoteric technology could
at least assist in matching data with templates. Help would be very welcome.
DECLARATIONS
As an example the declaration of above-mentioned vessel V-101 is given
below:
ex:847931fd-eade-4beb-b07d-a9e889611c19
rdf:type lci:InanimatePhysicalObject, dm:WholeLifeIndividual,
dm:NonActualIndiidual, rdl:RDS414674 ; # VESSEL
rdfs:label "V-101" ;
meta:valEffectiveDate "2021-04-13T15:29:00Z"^^xsd:dateTime .
EPILOG
I don’t expect that this approach will solve everybody’s problems.
Perhaps some aspects are useful.
This approach demands discipline, mainly because the integration of 50
years of information demands that. One related note: the model of ISO 15926-
2 is ‘4D’, allowing storage of old information by means of ‘temporal
parts’.
Regards, Hans
15926.org <https://15926.org/home/>
-----Original Message-----
From: Hugh Glaser <hugh@glasers.org>
Sent: dinsdag 15 februari 2022 12:52
To: hans.teijgeler@quicknet.nl
Cc: Frederik Byl <frederik.byl@gmail.com>; Semantic Web <semantic-
web@w3.org>
Subject: Re: EasierRDF
Hi Hans,
Much of what you say is true, and makes SW/LD people (like me!) very
comfortable.
But it is pretty much defending how things are.
Which (I say) is nowhere near as successful as the SW was intended or hoped
to be.
What can you offer the WebDevs, rather than you? (It is the Semantic *Web*,
after all).
In fact, what can you offer Frederick?
> On 11 Feb 2022, at 07:38, Frederik Byl < <mailto:frederik.byl@gmail.com>
frederik.byl@gmail.com> wrote:
> ...
> I'm struggling with the use, because the work that is necessary to make
systems interoperable by understanding ontologies, formatting the data,
extending ontologies, writing queries, etc, is huge!
It feels like you are just saying:- tough, he will have to live with it.
He is trying to do something hard, and so it is hard.
Is that right?
Because he seems to be saying it is easier in other technologies.
Best
Hugh
> On 15 Feb 2022, at 00:22, < <mailto:hans.teijgeler@quicknet.nl>
hans.teijgeler@quicknet.nl> < <mailto:hans.teijgeler@quicknet.nl>
hans.teijgeler@quicknet.nl> wrote:
>
> Melvin,
>
> I want to respond to your comments in two emails.
>
> [MC] Yes, it's easier for web devs because:
>
> - it's JSON
> [HT] There is more in the world than web devs; if so required we could
> use JSON-LD, not JSON
>
> - you dont need a parser -- this is a big deal [HT] rfc4627 - par. 4.
> Parsers
> A JSON parser transforms a JSON text into another representation.
> A JSON parser MUST accept all texts that conform to the JSON grammar.
> A JSON parser MAY accept non-JSON forms or extensions.
>
> - xsd -- few developers will even know what that is [HT] Because they
> use JSON, and thus don’t know about XML Schema. How does JSON
distinguish between an arithmetic number and a ZIP code?
>
> - turtle is a new syntax for most devs, they wont know what ex: is -- in
fact, it isn’t even defined in your example
> [HT] @prefix ex: < <http://dbpedia.org/resource/>
http://dbpedia.org/resource/> . where ex: is often used in RDF or OWL
examples for the prefix denoting ‘example’
>
> - people dont know what ^^ means
> [HT] One is never too old to learn. I guess it means ‘member of’
>
> - a tiny portion of the web is turtle, a large portion is turtle,
> there's no practical way to handle that [HT] Poor RDF-devs :(( , who have
no tools at all....
>
> What I mean is that nobody (slightly tongue-in-cheek) cares about
> what's IN the ontology, descriptions, labels, OWL. People use schema.org
for the name spacing and the SEO. People care about name spacing, they
dont care about inferencing. It's hard to even find wide spread examples
of inferencing used in the wild [HT] Not in your world.
>
> Very important thing here about "ex:"
> You've actually just made this data into a silo [HT] In business data
> are in silo’s.
>
> With my example "name" in one JSON document is "name" in another JSON
> document [HT] ‘name’ is 이름 in Korean. Actually they have 7 different
> words for ‘name’. Your mindset is too local (which is OK with me,
> don’t get me wrong)
>
> That is to say, JSON sent from one machine to another remains stable
> [HT] Yeh. How many terms are standardized in JSON? In UK or US English?
>
> In your example, every different document will have a different
> namespace, depending on what 'ex:' is defined as, and whether it's
> absolute or relative. In this case I assume it's relative This actually
guarantees that the data does NOT interoperate. Whereas if we'd
standarized (or can still standardize) the semantic web on JSON with URLs
and optionally vocabs, all different aspects interoperate as and when you
need them to [HT] Do you have any idea how many sets of jargon terms there
are? Our reference data library has some 40,000. In your example you used
namespaces as well. Actually in the real world you can’t do without.
<http://dbpedia.org/resource/John_Lennon>
http://dbpedia.org/resource/John_Lennon is the ident given to John Lennon
in a declaration in dbpedia (which, btw, I don’t care about) and I assume
that he has been typed as a Person. But we have, for one medium size
process plant, well over 10,000 such declarations with a wild variety of
equipment, instruments, pipes, and streams. And no plant owner wants his
data to be in the same cloud as the data of his competitors.
> Interoperation is done by federating triple stores under selective access
rules.
>
> So, Melvin, you and your web devs aren’t the only ones using the
semantic web. I respect your requirements, please do so with our
requirements. Your stuff seems to be better for you, our stuff is better
for us.
>
> Regards, Hans
> ___________________________________________________
> From: <mailto:hans.teijgeler@quicknet.nl> hans.teijgeler@quicknet.nl <
<mailto:hans.teijgeler@quicknet.nl> hans.teijgeler@quicknet.nl>
> Sent: maandag 14 februari 2022 18:07
> To: 'Melvin Carvalho' < <mailto:melvincarvalho@gmail.com>
melvincarvalho@gmail.com>; 'Frederik Byl'
> < <mailto:frederik.byl@gmail.com> frederik.byl@gmail.com>
> Cc: 'Semantic Web' < <mailto:semantic-web@w3.org> semantic-web@w3.org>;
'David Booth'
> < <mailto:david@dbooth.org> david@dbooth.org>
> Subject: RE: EasierRDF
>
> Melvin,
>
> Is your:
>
> <script type="application/ld+json">
> {
> "@id": " <http://dbpedia.org/resource/John_Lennon>
http://dbpedia.org/resource/John_Lennon",
> "name": "John Lennon",
> "born": "1940-10-09",
> "spouse": " <http://dbpedia.org/resource/Cynthia_Lennon>
http://dbpedia.org/resource/Cynthia_Lennon"
> }
> </script>
>
> easier than:
>
> ex:John_Lennon
> ex:name "John Lennon" ;
> ex:born "1940-10-09"^^xsd:date ;
> ex:spouse ex:Cynthia_Lennon .
> ?
>
> And please speak for yourself when claiming: “..... creating and
maintaining ontologies (which let's face it, almost no one does or cares
about today)”.
> I do care and I know there are more who do. I do care because I am caring
for interoperability and for life-cycle information integration. That
requires precise typing and a global reference library.
> It is the modeling sloppiness that is invited and permitted by these
languages that is the problem. Imho it is not much more precise than
writing something on a piece of paper.
>
> Finally this: “....libraries are yet to be built out” -some kind of
ontologies anyway?
>
> Regards, Hans
> 15926.org
> __________________________________________
> From: Melvin Carvalho < <mailto:melvincarvalho@gmail.com>
melvincarvalho@gmail.com>
> Sent: maandag 14 februari 2022 15:49
> To: Frederik Byl < <mailto:frederik.byl@gmail.com> frederik.byl@gmail.com>
> Cc: Semantic Web < <mailto:semantic-web@w3.org> semantic-web@w3.org>;
David Booth < <mailto:david@dbooth.org> david@dbooth.org>
> Subject: Re: EasierRDF
>
>
>
> On Fri, 11 Feb 2022 at 13:24, Frederik Byl <
<mailto:frederik.byl@gmail.com> frederik.byl@gmail.com> wrote:
>> Dear community,
>>
>> I came across the project <https://github.com/w3c/EasierRDF>
https://github.com/w3c/EasierRDF. I think it is a good idea to have a look
at RDF and the challenges it has. I'm struggling with the use, because the
work that is necessary to make systems interoperable by understanding
ontologies, formatting the data, extending ontologies, writing queries,
etc, is huge! I am a big fan of graph databases and the ease of using
Neo4j, Cypher, plain json and writing converters between readable json
formats is so much faster and developer friendly. Queries in Cypher are
intuitively and can be understood on sight. I am also looking at Solid and
I find the approach of data pods extremely interesting and relevant, but
the structure is so overwhelming and overcomplicated that I start losing
faith in this. Since the project EasierRDF is started, I guess others
struggle with the same? Are there some major advantages of using RDF and
Sparql over Neo4j and Cypher? We could do linked data with Json-ld and
Neo4j?
>
> I came to realize than in 15 years of heavy RDF use, the useful 10% is
> what I use 90% of the time
>
> You might want to look at this one-pager which tries to take some of
> the useful bits of RDF (@id @type @context) and add it to JSON
>
> <https://linkedobjects.org/> https://linkedobjects.org/
>
> It is for beginners getting started, and has an upgrade path to
> JSON-LD and full RDF, for those that want it. It's also compatible
> with plain old JSON, without needing the overhead of creating and
> maintaining ontologies (which let's face it, almost no one does or
> cares about today)
>
> Use cases and libraries are yet to be built out, but hopefully some
> food for thought
>
>>
>> Thanks
>>
>> Kind regards,
>> Frederik
>>
>> ---------- Forwarded message ---------
>> Van: David Booth < <mailto:david@dbooth.org> david@dbooth.org>
>> Date: do 10 feb. 2022 om 16:56
>> Subject: Re: EasierRDF
>> To: Frederik Byl < <mailto:frederik.byl@gmail.com>
frederik.byl@gmail.com>
>>
>>
>> Hi Frederik,
>>
>> You are asking an excellent question, and I think the community as a
>> whole would benefit from discussing it on a public list, both to get
>> more viewpoints and to expose your question to other existing RDF users.
>> Would you be willing to post your question to the public
>> <mailto:semantic-web@w3.org> semantic-web@w3.org list?
>> <https://lists.w3.org/Archives/Public/semantic-web/>
https://lists.w3.org/Archives/Public/semantic-web/
>>
>> Thanks,
>> David Booth
>>
>> On 2/10/22 10:43, Frederik Byl wrote:
>> > Dear David,
>> >
>> > I am sorry to contact you in this straightforward manner. I came
>> > across your project <https://github.com/w3c/EasierRDF> https://github.
com/w3c/EasierRDF
>> > < <https://github.com/w3c/EasierRDF>
https://github.com/w3c/EasierRDF>. I think it is a good idea to
>> > have a look at RDF and the challenges it has. I'm struggling with
>> > the use and the work that is necessary to make systems
>> > interoperable by understanding ontologies, formatting the data,
>> > extending ontologies etc, is huge! I am a big fan of graph
>> > databases and the ease of using Neo4j and plain json and writing
>> > converters between readable json formats is so much faster and
>> > developer friendly. I am also looking at Solid and I find the
>> > approach of data pods extremely interesting and relevant, but the
>> > structure is so overwhelming and overcomplicated that I start
>> > losing faith in this.Since you started the project Easier RDF, I guess
you struggle with the same, or do you see some major advantages in using
RDF?
>> >
>> > Thanks
>> >
>> > Kind regards,
>> > Frederik
Attachments
- image/png attachment: image001.png
Received on Tuesday, 15 February 2022 20:00:50 UTC