- From: David Booth <david@dbooth.org>
- Date: Fri, 07 Mar 2014 15:00:13 -0500
- To: Alan Ruttenberg <alanruttenberg@gmail.com>
- CC: semantic-web <semantic-web@w3.org>
- Message-ID: <531A254D.1010903@dbooth.org>
Hi Alan,
On 03/07/2014 12:44 PM, Alan Ruttenberg wrote:
> Can you explain what you mean by "RDF's ability to allow multiple data
> models to peacefully coexist, interconnected, in the same data" ?
Yes. Here is an imprecise illustration, on slides 10-17:
http://dbooth.org/2013/semtech/slides/03-DavidBooth-rdf-as-universal.pdf
(I took some artistic liberties blurring class/instance distinctions in
that diagram.)
And here is a more precise example that cleanly distinguishes classes
from instances:
http://tinyurl.com/pzsgf7f
(I've also attached the same illustration, for offline readers.)
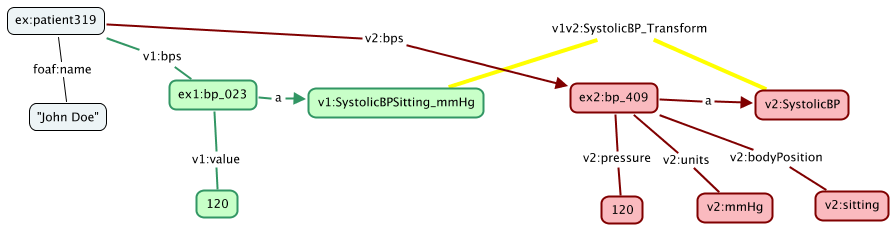
In this latter example (of a hypothetical systolic blood pressure
measurement), the same information is represented according to two
different models/schemas/vocabularies/ontologies, v1 (green) and v2
(red). (I am using the terms model, schema, vocabulary and ontology
loosely and somewhat interchangeably here.)
In the v1 model, the systolic blood pressure is indicated in RDF like this:
ex:patient319 foaf:name "John Doe" ;
v1:bps ex1:bp_023 .
ex1:bp_023 a v1:SystolicBPSitting_mmHg ;
v1:value 120 .
Whereas in the v2 model, the same information is represented
differently, in RDF like this:
ex:patient319 foaf:name "John Doe" ;
v2:bps ex2:bp_409 .
ex2:bp_409 a v2:SystolicBP ;
v2:pressure 120 ;
v2:units v2:mmHg ;
v2:bodyPosition v2:sitting .
Thus, although ex1:bp_023 and ex2:bp409 capture the same blood pressure
information, they represent that information differently. Nonetheless,
both representations can peacefully coexist in the same merged RDF data
without conflict, which might happen, for example, if one is derived
from the other through inference.
Furthermore, the relationship between these classes,
v1:SystolicBPSitting_mmHg and v2:SystolicBP, and hence the relationship
between the corresponding v1 and v2 instance data, can also be
explicitly captured in RDF, as the v1v2:SystolicBP_Transform (yellow)
relationship:
v1:SystolicBPSitting_mmHg v1v2:SystolicBP_Transform v2:SystolicBP .
Inference rules for v1v2:SystolicBP_Transform could therefore convert a
v1:SystolicBPSitting_mmHg measurement to a v2:SystolicBP measurement or
vice versa.
This example only illustrated the case where the transformation from one
model to the other is lossless and thus reversible. Usually that isn't
the case. Relating models and transforming between them is *not* easy,
but at least RDF makes it possible to explicitly indicate these
relationships.
Obviously some intelligence must be exercised to avoid, for example,
accidentally thinking that ex:bp_023 and ex2:bp_409 represent two
distinct blood pressure measurements, and thereby double counting them,
but that's easy enough to do.
Also, there isn't always a desire to relate or transform between models.
Sometimes some data is related and other data is not, and it is all
still merged into the same RDF graph. In fact, the point may be to
connect that part of the data that *is* related and let the rest coexist
without being connected (or at least not *directly* connected).
The point is that these data models can peacefully coexist in RDF data
without conflict: applications using the v1 model against the merged
data might only see v1 instance data, whereas applications using the v2
model might only see the v2 data. That's qualitatively different than
in the world of XML, for example, where one schema generally wants to be
"on top", and when you merge XML of different schemas, you need to
create a new "top" schema. That is the difference that I have so often
tried to explain to people outside the RDF community, and what I am
trying to capture succinctly in a term or phrase. It isn't an easy
idea to convey to those who are accustomed to a schema-centric approach.
I think a catchy but descriptive term or phrase could help.
Thanks,
David
>
> -Alan
>
>
> On Fri, Mar 7, 2014 at 11:20 AM, David Booth <david@dbooth.org
> <mailto:david@dbooth.org>> wrote:
>
> I -- and I'm sure many others -- have struggled for years trying to
> succinctly describe RDF's ability to allow multiple data models to
> peacefully coexist, interconnected, in the same data. For data
> integration, this is a key strength of RDF that distinguishes it
> from other information representation languages such as XML. I
> have tried various terms over the years -- most recently "schema
> promiscuous" -- but have not yet found one that I think really nails
> it, so I would love to get other people's thoughts.
>
> This google doc lists several candidate terms, some pros and cons,
> and allows you to indicate which ones you like best:
> http://goo.gl/zrXQgj
>
> Please have a look and indicate your favorite(s). You may also add
> more ideas and comments to it. The document can be edited by anyone
> with the URL.
>
> Thanks!
> David Booth
>
>
Attachments
- image/png attachment: Screenshot_from_2014-03-07_14:20:06.png
Received on Friday, 7 March 2014 20:00:41 UTC