- From: Yang Squared <yang.square@gmail.com>
- Date: Fri, 17 Feb 2012 19:26:25 +0000
- To: Leo Sauermann <leo.sauermann@gnowsis.com>
- Cc: "Andrea Splendiani (RRes-Roth)" <andrea.splendiani@rothamsted.ac.uk>, "<sergio.fernandez@fundacionctic.org>" <sergio.fernandez@fundacionctic.org>, "<david@dbooth.org>" <david@dbooth.org>, "<semantic-web@w3.org>" <semantic-web@w3.org>
- Message-ID: <CABi4B8D6YkBuR+Z_BAvQ4EXOr-f0iLiisk3fF1OT+orABnS=_w@mail.gmail.com>
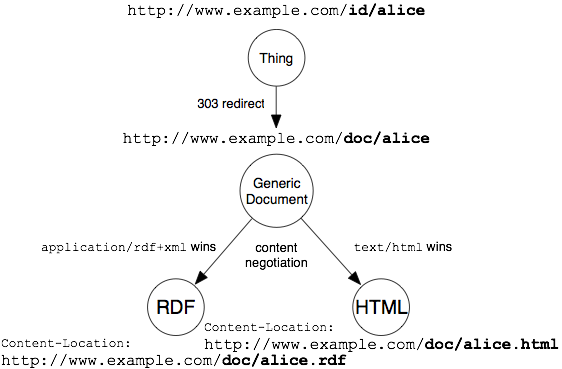
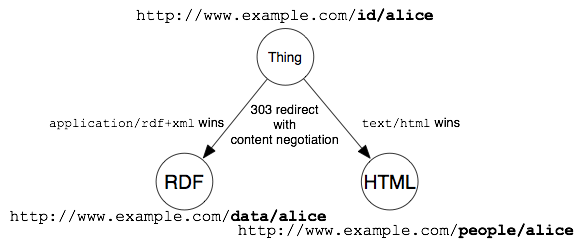
Hi Leo, Thanks for the link. I think this document mainly focus on discussing the how to publish URI for non-information resources. URI idnetifies the thing, real world object. My question was about how to publish RDF describes the Information resources, like a webpage. Thanks, Yang On Fri, Feb 17, 2012 at 6:37 PM, Leo Sauermann <leo.sauermann@gnowsis.com>wrote: > Hey fellas, > > Did you check out the W3C interest group note we wrote on how to make > these uris and how to do the 303 or #-uris? > > http://www.w3.org/TR/cooluris/ > > this was the original question: > > "when I dereferencing the original http://example.com/homepage.html it > did not result as a homepage.html itself and got a RDF. So there is a > paradox here." > > This question has been answered in cooluris in length. > (the document explains what timbl and the TAG meant with http-range14 and > extends it with best-practices found) > > also check out: > http://linkeddatabook.com/editions/1.0/ > > (p.s.: this http-range-14 (or "uricrisis") question pops up every week > here since 2001, and usually people do not point the asking person to the > W3C note nor Bizer's excellent guides that exist since ~2007. it took us > months to write the guides. I wonder why they are not so popular. > Really - why? :-) > > The discussion of scenario 1 and 2 have been broadly addressed in "cool > uris", I copy the important bits for your reference: > > ... > ... > > The second solution is to use a special HTTP status code, 303 See Other, > to give an indication that the requested resource is not a regular Web > document. Web architecture tells you that for a thing resource (URI) it is > inappropriate to return a 200 because there is, in fact, no suitable > representation for those resources. However, it is useful to provide > information about those resources. The W3C's Technical Architecture Group > proposes in its httpRange-14 resolution<http://lists.w3.org/Archives/Public/www-tag/2005Jun/0039.html> > [httpRange <http://www.w3.org/TR/cooluris/#ref-httpRange>] document a > solution that is to direct you to a document which has information *about* > the thing you asked about. By doing this we avoid ambiguity between the > original, real-world object and the resource that represents it. > > Since 303 is a redirect status code, the server can give the location of a > document that represents the resource. If, on the other hand, a request is > answered with one of the usual status codes in the 2XX range, like 200 OK, > then the client knows that the URI identifies a Web document. > > If Example Inc. adopts this solution, they could use these URIs to > represent the company, Alice and Bob: > http://www.example.com/id/exampleinc Example Inc., the company > http://www.example.com/id/bob Bob, the person > http://www.example.com/id/alice Alice, the person > > The Web server would be configured to answer requests to all these URIs > with a 303 status code and a Location HTTP header that provides the URL > of a document that represents the resource.* *For example, to redirect > from http://www.example.com/id/alice to http://www.example.com/doc/alice. > > Content-negotiation is then used when retrieving a representation from the > document URI using a HTTP request. The server decides (see Section 4.7<http://www.w3.org/TR/cooluris/#implementation>) > to return either HTML or RDF (or more alternative forms) and sets the > Content-Location header to the URI where the specific representation can > be retrieved. > > This setup should be used when the RDF and HTML (and possibly more > alternative representations) convey the *same information in different > forms*. When the information in the variations differs considerably, the > 303 approach as described below <http://www.w3.org/TR/cooluris/#r303uri> should > be used. > > See the following illustration for the solution providing the generic > document URI. > > [image: solution for a generic document URI] > > In this setup, the server forwards from the identification URI to the > generic document URI. This has the advantage that clients can bookmark and > further work with the generic document. A user having a RDF-capable client > could bookmark the document, and mail it to another user (or device) which > then dereferences it and gets the HTML *or* the RDF view. Also, the > server can add representations in new languages in the future. Just because > the client started with the URI of a thing, it doesn't mean that the > document involved is not a first class document on the WWW. The background > of generic document resources is described in [GenRes<http://www.w3.org/TR/cooluris/#ref-GenRes> > ]. > 4.3. 303 URIs forwarding to Different Documents > > When the RDF and HTML representations of the resource differ > substantially, the previous setup should not be used. They are not two > versions of the same document, but different documents altogether. Again, > the Web server would be configured to answer requests with a 303 status > code and a Location HTTP header that provides the URL of a document that > represents the resource. > > The following picture shows the redirects for the 303 URI solution without > the generic document URI: > > [image: The 303 URI solution] > > The server could employ content negotiation (see Section 2.1.<http://www.w3.org/TR/cooluris/#conneg>) > to send either the URL of an HTML description or RDF. HTTP requests for > HTML content would be redirected to the HTML URLs we gave in Section 2<http://www.w3.org/TR/cooluris/#oldweb>. > Requests for RDF data would be redirected to RDF documents, such as: > http://www.example.com/data/exampleinc RDF document describing Example > Inc., the company http://www.example.com/data/bob RDF document describing > Bob, the person http://www.example.com/data/alice RDF document describing > Alice, the person > > Each of the RDF documents would contain statements about the appropriate > resource, using the original URI, e.g. http://www.example.com/id/alice, > to identify the described resource. > > > It was Andrea Splendiani (RRes-Roth) who said at the right time 17.02.2012 > 19:21 the following words: > > Hi, > > scenario (1): ok. In may also happen to have a third identifier at time, > for the resource "per se", independently of its representation. > Note that the *.rdf and *.html resources are distinct information > resources which refer to the same information content. > > scenario (2): > You have some data, and some metadata (let's say: creator of an html > page). If for some specific reason, you need metadata in rdf (and not > RDFa), then probably a link is the best solution. > But just to avoid confusion: this is not the general case. In general > nothing prevents to put you metadata in the html itself (indeed... "meta" > tags remind of some old intensions). In fact, you may often find a > copyright statement in the page which is essentially metadata. > So, if what you propose comes from the fact that you RDF is for metadata > only, I think that is one possible use of it, not the general case. > > Another thing ti note: nothing says that the document > http://example.com/data/rdf should contain statements about > http://example.com/data/rdf. It could very well contain statements about > the html: http://example.com/homepage.html . > > In conclusion: if you need this separation of metadata in RDF, I would > go for a link (or RDFa-ish). > Otherwise in general I would add metadata in both the html and the rdf > representation. If you are talking specifically about an html file, I would > add metadata about it (html)in the rdf file. This may be a bit questionable > at first, but at second I think it makes sense. You don't want infinite > assertion of meta-* statements ;) > > ciao, > Andrea > > > Il giorno 17/feb/2012, alle ore 17.59, Yang Squared ha scritto: > > I see your point now. Thx, Andrea. > > I just realise that there may be two scenarios: > > 1) RDF and HTML are just the representation of the same resource > > Assume we have a weather report http://example.com/weatherreport which > has two representation in HTML (human readable representation) and RDF > (machine readable representation) > > In this case, the content of HTML and RDF should be consistent. > > We can use then using content negotiation to serve these two > representations for the same URI. > > 2) RDF describes a HTML Web Page Resource > > For example > > I have a resource about my homepage http://example.com/homepage.html > I have a metadata RDF about someone created this homepage > http://example.com/data/rdf > > In this case, these two URIs are not referring to the same thing. > > According to David Booth and Leo Sauermann, we should use <link> tag in > HTMl or not widely known HTTP link header (not accepted proposal). > > I hope these are all cases. Please correct me if I am wrong. > > Yang > > > > > > On Fri, Feb 17, 2012 at 5:18 PM, Andrea Splendiani (RRes-Roth) < > andrea.splendiani@rothamsted.ac.uk> wrote: > >> Wait... >> >> http://www.test.com/test.html <- this is a resource, and has it's own >> URI (1) >> http://www.test.com/test.rdf <- this is another resource, and has it's >> own (distinct) URI (2) >> >> Now, what I am saying is that in the RDF you can also predicate on the >> the URI (1). >> So if you ask information about (1), requiring a result in rdf, it seems >> reasonable to return (2) with predicates (eventually) on (1). >> This is not really incorrect, though it may be unpractical for some. >> >> But perhaps I don't get your distinction between page and metadata. >> >> Metadata on the page can also be in the html representation itself. >> In RDF I'm asking for a machine readable representation of the content of >> the page, rather than it's metadata only. >> >> Do you mean something else by metadata ? >> >> ciao, >> Andrea >> >> >> >> Il giorno 17/feb/2012, alle ore 17.03, Yang Squared ha scritto: >> >> Hi Andrea, >> >> I think using content negotiation is incorrect, the homepage is a >> resource need a URI, and the metadata RDF is another resource need another >> URI. Otherwise, we are saying the homepage and the metadata of the homepage >> is the same thing. >> >> The representation of the homepage is the HTML page >> the representation of the metadata of the homepage is the RDF >> >> Regards, >> Yang >> >> >> On Fri, Feb 17, 2012 at 4:24 PM, Andrea Splendiani (RRes-Roth) < >> andrea.splendiani@rothamsted.ac.uk> wrote: >> >>> Hi, >>> >>> I'm using content negotiation. >>> In most of the cases, the "information resource" is actually something >>> in a database or stored somewhere. So representing it in html or rdf via >>> content negotiation seems plausible. >>> >>> In case the information resource in html is what you want to predicate >>> (like, you have a collection of html files that you are serving) the rdf >>> returned via content negotiation could include predicates about the html >>> file uri. >>> If you are asking for the html file resource, this is always in html by >>> definition. Requesting an rdf implies anyway requesting something else. >>> >>> ciao, >>> Andrea >>> >>> >>> Il giorno 17/feb/2012, alle ore 02.21, Yang Squared ha scritto: >>> >>> Hi all, >>> >>> I have a Web architecture question here. >>> >>> Assume I have a information resource URI >>> http://example.com/homepage.html >>> >>> I would like to publish a RDF metadata ( >>> http://example.com/data/homepagerdf) about this information resource >>> (e.g. homepage isCreatedBy steve). What publishing mechanism can I use? >>> >>> since http://example.com/homepage.html is an Information Resource, >>> when dereferencing it, we should get that homepage.html document returned. >>> How can we possible redirect to a RDF? >>> >>> Content negotiation can use to serve two different representation of >>> the resource, but both representation is for the same resource. So we >>> cannot use it. >>> >>> 303 can redirect one information resources to another information >>> resource, e.g. http://example.com/homepage.html --303--> >>> http://example.com/data/homepagerdf --200-->RDF >>> >>> but in this way, when I dereferencing the original >>> http://example.com/homepage.html it did not result as a homepage.html >>> itself and got a RDF. So there is a paradox here. >>> >>> Can anyone please suggest anything? Or the conclusion is that the RDFa >>> (or by using the link element to RDF) is the only way to publish RDF >>> metadata for information resources? >>> >>> I am writing a paper and I would like to conclude that there will be >>> no case that a hashURI publishing mechanism and 303 redirection can be used >>> for Information Resource to publish RDF metadata. Do you have any object >>> case? >>> >>> ------------------------------ >>> One may recommend me to use RDFa. However, I consider that the RDFa is >>> not ideal solution to publish Linked Data at all. >>> First of all, embedding metadata together with data prohibits the >>> independent curation of data and metadata. Secondly, following the >>> principles of the Web Architecture, any distinct resource of significance >>> should be given a distinct URI, but in this approach a single URI is used >>> to identify two information resources. In general, the RDFa embedded >>> metadata approach can be replaced by using the <link> element href in XHTML >>> to pointing to an external RDF document, where the rel=”meta” attribute >>> can be used to indicate a relationship between resources. >>> >>> Thanks a lot, >>> Yang Yang >>> >>> ----------------------------------- >>> >>> Web and Internet Science >>> >>> Room 3027 EEE Building >>> >>> Electronics and Computer Science >>> >>> University of Southampton, SO17 1BJ >>> >>> >>> Tel: +44(0)23 8059 8346 <%2B44%280%2923%208059%208346> >>> >>> twitter: @yang_squared <http://twitter.com/#%21/yang_squared> >>> >>> >>> >>> >>> -- >>> >>> ----------------------------------- >>> >>> Web and Internet Science >>> >>> Room 3027 EEE Building >>> >>> Electronics and Computer Science >>> >>> University of Southampton, SO17 1BJ >>> >>> >>> Tel: +44(0)23 8059 8346 >>> >>> twitter: @yang_squared <http://twitter.com/#%21/yang_squared> >>> >>> >>> >> >> >> -- >> >> ----------------------------------- >> >> Web and Internet Science >> >> Room 3027 EEE Building >> >> Electronics and Computer Science >> >> University of Southampton, SO17 1BJ >> >> >> Tel: +44(0)23 8059 8346 >> >> twitter: @yang_squared <http://twitter.com/#%21/yang_squared> >> >> >> > > > -- > > ----------------------------------- > > Web and Internet Science > > Room 3027 EEE Building > > Electronics and Computer Science > > University of Southampton, SO17 1BJ > > > Tel: +44(0)23 8059 8346 > > twitter: @yang_squared <http://twitter.com/#%21/yang_squared> > > > > -- > Leo Sauermann, Dr. > CEO and Founder > > mail: leo.sauermann@gnowsis.com > mobile: +43 6991 gnowsis > > Where your things come together, > Try: http://www.getrefinder.com/ > Join: http://www.getrefinder.com/about/content/newsletter > Follow: http://twitter.com/Refinder > Like: http://www.facebook.com/Refinder > Learn: http://www.getrefinder.com/about/blog > ____________________________________________________ > > -- ----------------------------------- Web and Internet Science Room 3027 EEE Building Electronics and Computer Science University of Southampton, SO17 1BJ Tel: +44(0)23 8059 8346 twitter: @yang_squared <http://twitter.com/#!/yang_squared>
Attachments
- image/png attachment: 303conneg.png
- image/png attachment: 303.png
Received on Friday, 17 February 2012 19:27:00 UTC