- From: Pipian <pipian@pipian.com>
- Date: Fri, 28 Mar 2008 14:10:14 -0400
- To: Story Henry <henry.story@bblfish.net>
- Cc: foaf-dev of a Friend <foaf-dev@lists.foaf-project.org>, Semantic Web <semantic-web@w3.org>
- Message-Id: <FB582300-C6D8-4BF5-88E5-2BA10E5C51F3@pipian.com>
On Mar 27, 2008, at 8:06 AM, Story Henry wrote:
> Hi,
>
> I would like to put the following forward as a sketch of what is
> needed to allow a resource to return different representations
> depending on the identity of the requester. We are looking for some
> security experts and others to help out here.
>
> There may be other standards that can be used, but it would help to
> see how far one can get with a very clean system to start off with.
> At least this should help understand what is needed.
>
> The idea is simple. We have 4 resources here.
>
> 1. A Semantic Web client owned by Romeo ( something like Beatnik,
> Tabulator or Knowee )
> 2. Juliette's foaf file resource controlled by a slightly
> intelligent web service (one that knows to show which parts of the
> graph to show to whom)
> 3. Romeo's foaf file (perhaps also controlled by an intelligent web
> service, but there is no need for this here)
> 4. Romeo's public key. This could be part of the foaf file, but
> assuming that it does not change that often, it would be better
> placed at a separate resource in order to be more easily cacheable
>
>
> <SequenceDiagram.png>
>
>
>
> So the sequence of calls I imagine are the following:
>
> 1. Romeo wants to have information about <http://juliette.org/#juliette
> > (Juliette) so he GETs <http://juliette.org/>
> 2. the server responds with either:
> - some minimal information and a yet to be invented return code of
> 207 PARTIAL INFORMATION
> - a 403 Forbidden
> In either case a header returning some information regarding the
> type of authentication required is sent back
> 3. the client sends a GET back with some header information:
> - the URL of Romeo <http://romeo.name/#romeo>
> - an encrypted string (perhaps a string sent in the previous
> response)
> 4. The server controlling Juliette's foaf doc sends a GET request to
> the foaf file
> 5. The server controlling Romeo's foaf doc returns his foaf file, in
> any number of formats, or perhaps even a GRDDLable document the
> server can understand, containing a link to one of his public pgp
> keys
> 6. Juliet's server queries this representation transformed into
> triples with the SPARQL query
>
> PREFIX wot: <http://xmlns.com/wot/0.1/>
> SELECT ?pgp
> WHERE {
> [] wot:identity <http://romeo.name/#romeo>;
> wot:pubkeyAddress ?pgp .
> }
>
>
> 7. Juliette uses the answer in 6 to GET the PGP key.
> (what to do if someone has more that one PGP key?)
>
> 8. Romeo's server returns the PGP key
>
> 9. Juliette's server uses the public key to decrypt the string
> passed in 3. Having done this Juliette's server now knows that the
> request in 3 came
> from software owned by <http://romeo.name/#romeo>.
>
> 10. Juliette's server after consulting her policies for <http://romeo.name/#rome
> >, returns the appropriate response; a 200 perhaps with a fuller
> foaf file. Perhaps something else needs to be returned, a token to
> give access to a number of resources (expressed in POWDER perhaps).
>
> Now Romeo has more information about Juliette. Perhaps information
> about where she they can meet.
>
> This seems quite feasible.
>
> Some thoughts that just arose from going through the exercise of
> specifying each of the steps precisely:
> - what kind of response should be returned in 2? Should this
> redirect to an authentication server perhaps which would then return
> some token to give access to all the resources in a domain?
> - What about multiple pgp keys?
> - others?
>
> Does this help?
>
> Henry
>
>
> Home page: http://bblfish.net/
>
I don't want to throw in my two cents as yet, but I did want to
mention that I'm currently working on a project with DIG that
dovetails nicely with the proposal given here. I'm sorry I haven't
actually mentioned such until now, but I recently caught a nasty case
of the flu that's kept me more or less bed-ridden for the past two
days, so I haven't really had the chance to follow the discussion
closely, so you guys might need to correct some of my misconceptions.
My implementation (written for use with mod_python) is currently
simplistic, and more focused on policy-based authentication and
accountability tracking (which still requires establishment of
identity) rather than filtering RDF documents, but I believe that the
same principles can be applied, given a suitable way of expressing
such filters (which I've been putting off pending actually completing
the authentication part). Furthermore, this implementation has
focused on an OpenID implementation rather than a PGP solution, though
I can easily see the benefits of a PGP solution over an OpenID
solution, and I don't see a significant barrier to reimplement the
system on top of a PGP solution. For the time being, however, I am
trying to focus on actually implementing the system before worrying
about implementation details like this.
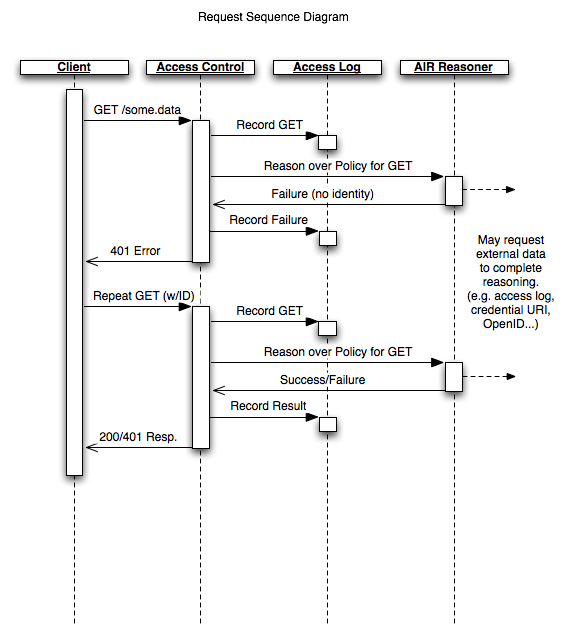
I've also attached the sequence diagram that more or less covers the
paradigm I'm implementing currently:
The project I'm working on might be a good place to actually produce a
sample implementation, but only after the primary goals are achieved
(i.e. filtering an RDF graph comes second, not first).
Ian Jacobi
Attachments
- text/html attachment: stored
- image/png attachment: TAMI_Architecture_Request_Sequence.png
Received on Friday, 28 March 2008 18:11:09 UTC