- From: Sasha Firsov <suns@firsov.net>
- Date: Fri, 23 Dec 2022 11:37:02 -0800
- To: Dimitre Novatchev <dnovatchev@gmail.com>
- Cc: Michael Kay <mike@saxonica.com>, "public-xslt-40@w3.org" <public-xslt-40@w3.org>
- Message-ID: <CAL8k5D_1R18RCxBFbRxkcyA6R8OphXtBiueBxqL3wJFWceCwow@mail.gmail.com>
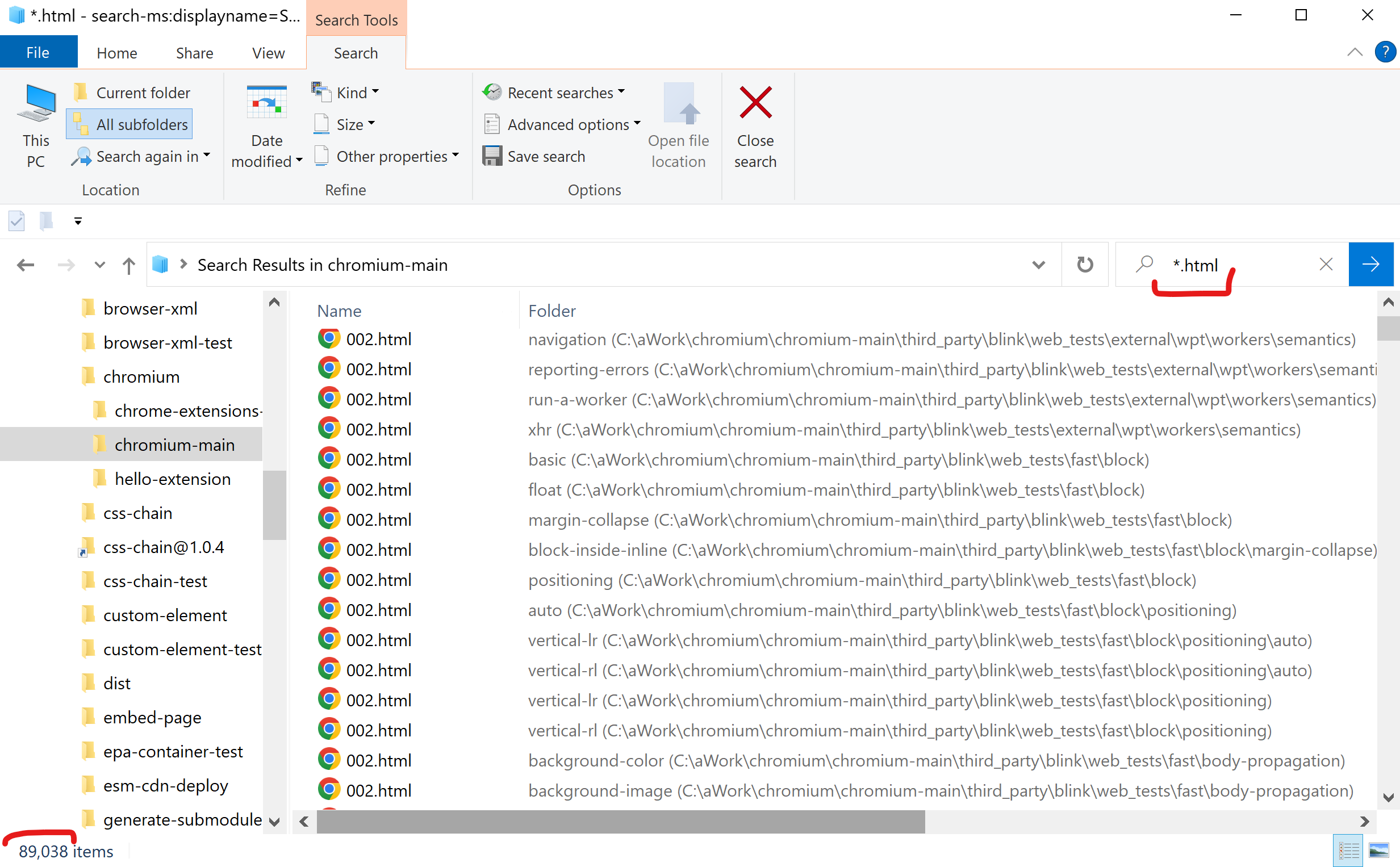
> avoid edge cases which are negligible in occurrence. Unfortunately HTML is about edge cases in comparison to XML. The most of content on the web comes from CMS where HTML is automatically guarded and validated before publishing. *But can the rare edge cases be ignored?* Most of such would come up on web developer environment who by definition are bigger influencers on the tech stack. If the lib would make this crowd unhappy, it would be doomed. IMO it is critical to support edge cases in same fashion as browsers do. Only after such comparison you can be assured of user acceptance. On Fri, Dec 23, 2022 at 10:44 AM Dimitre Novatchev <dnovatchev@gmail.com> wrote: > What about using a web-crawler and saving html documents that have a > diversity of characteristics that compliment each other, and united as a > whole may be regarded as a reasonably complete representation of the > **real** Html Universe? > > Also, giving the different Html documents a "frequency weight" that would > be bigger for documents that are being requested more frequently in a given > period of time. Thus, it may be wise not to spend any effort on a document > that is being requested in one-millionth of one percent of all the time, > regardless what "precious" insights this document could give us. To put it > simpler: avoid edge cases which are negligible in occurrence. > > BTW, ignoring javascript leads to being incognizant of a significant > portion of Html in the browsers -- the Html that is generated dynamically > by the javascript of the initially-loaded pages. This demonstrates a > significant risk of not representing in the test-data a considerable > portion of the Html documents that the web-browsers already have to deal > with on a daily basis at present. > > Thanks, > Dimitre > > On Fri, Dec 23, 2022 at 9:58 AM Sasha Firsov <suns@firsov.net> wrote: > >> > (a) Find a useful set of HTML files (around 1000, ideally) >> There is a "brutal force" approach. If you can not get the set sufficient >> for the goal, take the superset which is guaranteed to cover all. >> Chromium sources have ~90K html files, most reside in test folders. I >> guess Firefox would have about the same. The old W3C set is still valid but >> not current. >> The union of all 3 would give you the assurance of integrity. Of >> course it is time consuming, but since the final result is needed only >> during release, perhaps justified. >> -s >> [image: image.png] >> >> On Thu, Dec 22, 2022 at 3:24 PM Michael Kay <mike@saxonica.com> wrote: >> >>> I guess one approach might be: >>> >>> (a) Find a useful set of HTML files (around 1000, ideally) that exhibit >>> the right range of markup characteristics - remembering that we're not >>> interested in script variations or CSS variations or interactive behavoiur, >>> only in markup >>> >>> (b) Put these through a test generator based on Henri Sivonen's HTML5 >>> parser, to generate (for each one) an XML document that has the same XDM >>> representation as the HTML. >>> >>> (c) Have the test driver compare the XDM produced by parse-html() on the >>> original document with the XDM produced by parse-xml() on the equivalent >>> XML. >>> >>> I'm still not sure how best to achieve (a). >>> >>> This isn't ideal, because we're testing against a trusted implementation >>> rather than against the specification. And it gets circular if the actual >>> product-under-test is using the same HTML5 parser that was used to >>> construct the tests. But it's a potential way forward. >>> >>> Michael Kay >>> Saxonica >>> >>> On 22 Dec 2022, at 22:23, Sasha Firsov <suns@firsov.net> wrote: >>> >>> Michael, >>> Not a real answer but could cover half of the needs. >>> >>> The test suite has a set of test samples and results to compare against. >>> The second can be achieved by feeding the input string to actual DOM engine >>> (Chromium/Blink) and comparing your own parser results with the actual >>> browser DOM. Going further, by utilizing *cross-browser testing* capabilities like >>> from @web/test-runner-playwright, you would have a *parser browser >>> compatibility matrix*. >>> >>> While the approach is not a test against "ideal" standards, it is more >>> valuable in the web development world as shows the cross-browser support, a >>> criteria to accept any JS library. The browsers themselves are not >>> following W3C test suites anymore: >>> > Blink does not currently (4/2013) regularly import and run the W3C's >>> tests >>> <https://www.chromium.org/blink/blink-testing-and-the-w3c/#ideal-state> >>> >>> As for the 1st half of the question on the parser test set, the >>> Chromium(Blink) or FF sources have the parser tests in the sources. >>> Extraction of those is a bit of a challenge though. >>> Blink sources are in chromium repo >>> <https://github.com/chromium/chromium/blob/main/third_party/blink/renderer/core/html/parser>. >>> Do not use `git clone` as it is 30+Gb, get the latest instead: >>> >>> https://github.com/chromium/chromium/archive/refs/heads/main.zip >>> >>> -s >>> >>> PS I have used such approach for testing of TEMPLATE >>> <https://github.com/chromium/chromium/blob/main/third_party/blink/web_tests/external/wpt/shadow-dom/slots.html#L8> >>> tag shadowDOM simulation in css-chain >>> <https://github.com/sashafirsov/css-chain-test/blob/main/src/slots-light-vs-shadow.html> >>> and light-dom-element tests. >>> >>> On Wed, Dec 21, 2022 at 4:06 PM Michael Kay <mike@saxonica.com> wrote: >>> >>>> I've just been running a few new tests on our existing parse-html() >>>> function on SaxonJ (built on TagSoup) and SaxonCS (built on >>>> HtmlAgilityPack) and reallising how different they are. I suspect that >>>> getting a good level of interoperability (and tests to prove it) for >>>> fn:parse-html is going to be challenging! >>>> >>>> Is there an HTML5 test suite we can build on? >>>> >>>> Michael Kay >>>> Saxonica >>>> >>> >>> >
Attachments
- image/png attachment: image.png
Received on Friday, 23 December 2022 19:37:27 UTC