- From: Bernard Aboba <Bernard.Aboba@microsoft.com>
- Date: Tue, 3 Jul 2018 18:19:17 +0000
- To: "public-webrtc@w3.org" <public-webrtc@w3.org>
- Message-ID: <MW2PR00MB0329536E051F7BC65564DE85EC420@MW2PR00MB0329.namprd00.prod.outlook.com>
During the F2F, we talked about separating out simulcast support into an extension document and potentially adding support for scalable video coding (SVC) to it (with a focus on temporal scalability).
Here are a few thoughts on how we might approach that.
Assumptions
1. No need for negotiation. If an RTCRtpReceiver can always decode any legal SVC bitstream sent to it without pre-configuration, then there is no need for negotiation to enable sending and receiving of an SVC bitstream. This assumption, if valid, enables addition of SVC support by addition of attributes to encoding parameters.
2. Codec support. Today several browsers have implemented VP8 (temporal) and VP9 (temporal, with spatial as experimental) codecs with SVC support. It is also expected that support for AV1 (temporal and spatial) will be added by multiple browsers in future. AFAIK, each of these codecs fits within the no-negotiation model (e.g. in AV1, support for SVC tools are required at all profile levels). As a side note, I believe that H.264/SVC could also be made to fit within the no-negotiation model if some additional restrictions are imposed upon implementations (such as requiring support for UC mode 1, described here: http://www.mef.net/resources/technical-specifications/download?id=106&fileid=file1 ). So the no-negotiation model seems like it would allow support for current and potential future SVC-capable codecs.
Unified’Communication H.264/MPEG%4 Part%10!! AVC$and$SVC ...<http://www.mef.net/resources/technical-specifications/download?id=106&fileid=file1>
www.mef.net
H.264/MPEG-4 Part 10 AVC and SVC Modes Specification ver. 1.0b! UCIF! ! ! 5! SSPS! ! ! Subset!SequenceParameter!Set! SVC*! ! ! ScalableVideo!Coding!
General approach
Today, the encoding and decoding parameters appear as follows:
dictionary RTCRtpCodingParameters<https://w3c.github.io/webrtc-pc/#dom-rtcrtpcodingparameters> {
DOMString<https://heycam.github.io/webidl/#idl-DOMString> rid<https://w3c.github.io/webrtc-pc/#dom-rtcrtpcodingparameters-rid>;
};
dictionary RTCRtpDecodingParameters<https://w3c.github.io/webrtc-pc/#dom-rtcrtpdecodingparameters> : RTCRtpCodingParameters<https://w3c.github.io/webrtc-pc/#dom-rtcrtpcodingparameters> {
};
dictionary RTCRtpEncodingParameters<https://w3c.github.io/webrtc-pc/#dom-rtcrtpencodingparameters> : RTCRtpCodingParameters<https://w3c.github.io/webrtc-pc/#dom-rtcrtpcodingparameters> {
octet<https://heycam.github.io/webidl/#idl-octet> codecPayloadType<https://w3c.github.io/webrtc-pc/#dom-rtcrtpencodingparameters-codecpayloadtype>;
RTCDtxStatus<https://w3c.github.io/webrtc-pc/#dom-rtcdtxstatus> dtx<https://w3c.github.io/webrtc-pc/#dom-rtcrtpencodingparameters-dtx>;
boolean<https://heycam.github.io/webidl/#idl-boolean> active<https://w3c.github.io/webrtc-pc/#dom-rtcrtpencodingparameters-active> = true;
RTCPriorityType<https://w3c.github.io/webrtc-pc/#dom-rtcprioritytype> priority<https://w3c.github.io/webrtc-pc/#dom-rtcrtpencodingparameters-priority> = "low";
unsigned long<https://heycam.github.io/webidl/#idl-unsigned-long> ptime<https://w3c.github.io/webrtc-pc/#dom-rtcrtpencodingparameters-ptime>;
unsigned long<https://heycam.github.io/webidl/#idl-unsigned-long> maxBitrate<https://w3c.github.io/webrtc-pc/#dom-rtcrtpencodingparameters-maxbitrate>;
double<https://heycam.github.io/webidl/#idl-double> maxFramerate<https://w3c.github.io/webrtc-pc/#dom-rtcrtpencodingparameters-maxframerate>;
double<https://heycam.github.io/webidl/#idl-double> scaleResolutionDownBy<https://w3c.github.io/webrtc-pc/#dom-rtcrtpencodingparameters-scaleresolutiondownby>;
};
A first step toward SVC support would be to add additional encoding parameters:
partial dictionary RTCRtpEncodingParameters<http://draft.ortc.org/#dom-rtcrtpcodingparameters> {
d<https://heycam.github.io/webidl/#idl-DOMString>ouble scaleFramerateDownBy;
sequence<https://heycam.github.io/webidl/#idl-sequence><DOMString<https://heycam.github.io/webidl/#idl-DOMString>> dependencyEncodingIds<http://draft.ortc.org/#dom-rtcrtpcodingparameters-dependencyencodingids>;
};
scaleFramerateDownBy of type double
Inverse of the input framerate fraction to be encoded. Example: 1.0 = full framerate, 2.0 = one half of the full framerate. For scalable video coding, scaleFramerateDownBy refers to the inverse of the aggregate fraction of input framerate achieved by this layer when combined with all dependent layers.
dependencyEncodingIds of type sequence<DOMString>
The rid<http://draft.ortc.org/#dom-rtcrtpcodingparameters-encodingid>s on which this layer depends. In order to enable encoding of scalable video coding (SVC<http://draft.ortc.org/#dfn-svc>) bitstreams, both the rid and dependencyEncodingIds are required.
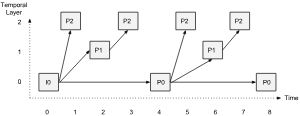
Here is an example of how this would work (copied from ORTC<http://draft.ortc.org/#rtcrtpencodingtemporal-example*>):
// Example of 3-layer temporal scalability encoding
var encodings = [{
// Base framerate is one quarter of the input framerate
rid: "layer0",
scaleFramerateDownBy: 4.0}, {
// Temporal enhancement (half the input framerate when combined with the base layer)
rid: "layer1",
dependencyEncodingIds: ["layer0"],
scaleFramerateDownBy: 2.0}, {
// Another temporal enhancement layer (full input framerate when all layers combined)
rid: "layer2",
dependencyEncodingIds: ["layer0", "layer1"],
scaleFramerateDownBy: 1.0}];
The bitstream dependencies look like this:
[cid:9f681c97-de63-489a-ad97-fb4624ac6141]
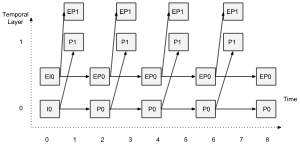
Combining spatial simulcast and temporal scalability would look like this:
// Example of 2-layer spatial simulcast combined with 2-layer temporal scalability
var encodings = [{
// Low resolution base layer (half the input framerate, half the input resolution)
rid: "L0",
scaleResolutionDownBy: 2.0,
scaleFramerateDownBy: 2.0
}, {
// High resolution Base layer (half the input framerate, full input resolution)
rid: "E0",
scaleResolutionDownBy: 1.0,
scaleFramerateDownBy: 2.0
}, {
// Temporal enhancement to the low resolution base layer (full input framerate, half resolution)
rid: "L1",
dependencyEncodingIds: ["L0"],
scaleResolutionDownBy: 2.0,
scaleFramerateDownBy: 1.0
}, {
// Temporal enhancement to the high resolution base layer (full input framerate and resolution)
rid: "E1",
dependencyEncodingIds: ["E0"],
scaleResolutionDownBy: 1.0,
scaleFramerateDownBy: 1.0
}];
The layer diagram corresponding to this example is here:
[cid:18dc1f3e-98b4-4c83-a5c6-ddb9b0c37134]
At the F2F, we also talked about allowing developers uninterested in the details to easily generate appropriate configurations.
This could be done via helper functions, such as generateEncodings():
// function generateEncodings (spatialSimulcastLayers, temporalLayers)
var encodings = generateEncodings(1, 3); // generates the encoding shown in the first example
var encodings = generateEncodings(2, 2); // generates the encoding shown in the second example
var encodings = generateEncodings(); // generates a default encoding such as 3 spatial simulcast, 3 temporal layers
Limitations
What does this proposal *not* enable? RTCRtpFecParameters and RTCRtpRtxParameters were removed from WebRTC 1.0 a while ago, so this proposal does not enable support for differential protection (e.g. retransmission or forward error correction only for the base layer).
However, the proposal can support for spatial scalability, if there is interest in enabling this at some point. This can be accomplished by using dependencyEncodingIds along with scaleResolutionDownBy, such as in the following examples:
// Example of 3-layer spatial scalability encoding
var encodings = [{
// Base layer with one quarter input resolution
rid: "base",
scaleResolutionDownBy: 4.0
}, {
// Spatial enhancement layer yielding half resolution when combined with the base layer
rid: "Layer1",
dependencyEncodingIds: ["base"],
scaleResolutionDownBy: 2.0
}, {
// Additional spatial enhancement layer yielding full resolution when combined with all layers
rid: "layer2",
dependencyEncodingIds: ["base", "layer1"],
scaleResolutionDownBy: 1.0
}]
// Example of 2-layer spatial scalability combined with 2-layer temporal scalability
var encodings = [{
// Base layer (half input framerate, half resolution)
rid: "layer0",
scaleResolutionDownBy: 2.0,
scaleFramerateDownBy: 2.0
}, {
// Temporal enhancement to the base layer (full input framerate, half resolution)
rid: "layer1",
dependencyEncodingIds: ["layer0"],
scaleResolutionDownBy: 2.0,
scaleFramerateDownBy: 1.0
}, {
// Spatial enhancement to the base layer (half input framerate, full resolution)
rid: "E0",
dependencyEncodingIds: ["layer0"],
scaleResolutionDownBy: 1.0,
scaleFramerateDownBy: 2.0
}, {
// Temporal enhancement to the spatial enhancement layer (full input framerate, full resolution)
rid: "E1",
dependencyEncodingIds: ["E0", "layer1"],
scaleResolutionDownBy: 1.0,
scaleFramerateDownBy: 1.0
}];
Attachments
- image/png attachment: pastedImage.png
- image/png attachment: 02-pastedImage.png
Received on Tuesday, 3 July 2018 18:19:52 UTC