- From: Michael Miller <mmiller@teranode.com>
- Date: Tue, 5 Jan 2010 18:53:10 -0500
- To: "Jim McCusker" <james.mccusker@yale.edu>, "mdmiller" <mdmiller53@comcast.net>, "w3c semweb HCLS" <public-semweb-lifesci@w3.org>
- Message-ID: <6401DB16544A5B4AA279B921F43547EC066FC59E@MI8NYCMAIL16.Mi8.com>
hi jim,
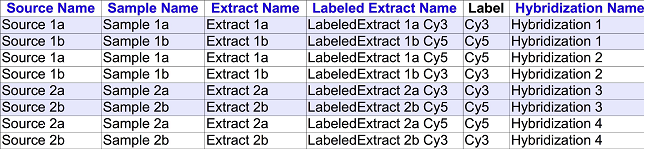
from section 2.2.3, figure 6 (i hope the figure comes out, otherwise
reference the MAGE-TAB specification [1] directly):
2.2.3 Example: Iterated Design dual channel
This is shown in Figure 6.
(a) Investigation design graph
(b) SDRF representation
Figure 6: Iterated design, dual channel. LabeledExtract-Dye associations
can be added as a separate "Label"
Note that each source is repeated twice on a separate line so there is
no ambiguity as to the different processing. i highly recommend reading
the spec, tim rayner did a great job of describing how different DAGs
are represented by a spreadsheet. also, you'll need to take into
account that there can be multiple Protocol REF columns between each set
of Name nodes.
cheers,
michael
[1] http://www.mged.org/mage-tab/MAGE-TABv1.0.pdf
From: public-semweb-lifesci-request@w3.org
[mailto:public-semweb-lifesci-request@w3.org] On Behalf Of Jim McCusker
Sent: Tuesday, January 05, 2010 3:10 PM
To: mdmiller; w3c semweb HCLS
Subject: Re: magetab2magerdf
For what it's worth, I'm generating a DAG using ProtocolApplications as
edges.
Related to that, I have a limpopo question:
In a case where there are 2 channel microarrays, different protocols are
used to create labeled extracts. If there is a technical dye swap
replicate (where the same extract is split and labeled differently), how
does the list of ProtocolNodes (where one is a Cy5 labeling and the
other is a Cy3 labeling) relate each LabeledExtract to the source
Extract? From what I can tell, this information is currently lost, as
the Extract (say ext1) would have 2 protocol nodes (Cy5 and Cy3), and
then two child nodes (labext1 and labext2). I need to be able to relate
which is which.
Thanks,
Jim
On Sat, Jan 2, 2010 at 10:50 PM, Kei Cheung <kei.cheung@yale.edu> wrote:
Hi Michael et al,
The question is what is the appropriate structure of the DAG for
answering the semantic queries for our microarray use case.
mdmiller wrote:
hi kei,
mage-tab and its extension isa-tab is designed from the principal of a
DAG, in essence it is a flattening of the dag into a spreadsheet which
is describe in the MAGE-TAB 1.0 spec [1] in great detail. i believe the
MAGE-TAB parser stores the nodes as a DAG [2]. EBI has also developed a
suite of tools around the MAGE standard [3] including a DAG
visualization. ArrayExpress for each experiment also has a visualized
view of the experiment as a DAG that can be downloaded. in MAGE-ML the
'_ref' elements are used to describe the DAG in a MAGE document.
is the one mentioned below editable? that's the one thing about the EBI
visualization, it is not editable.
I don't think the one mentioned in the paper below is editable.
Cheers,
-Kei
by the by, MAGE-TAB is also being used to report next-gen
sequencing experiments in ArrayExpress.
cheers,
michael
[1] www.mged.org
[2] https://sourceforge.net/projects/limpopo/
[3]
http://bioinformatics.oxfordjournals.org/cgi/content/full/25/2/279
----- Original Message ----- From: "Kei Cheung" <
kei.cheung@yale.edu>
To: "mdmiller" <mdmiller53@comcast.net>
Cc: "Jim McCusker" <james.mccusker@yale.edu>; "w3c semweb HCLS"
<public-semweb-lifesci@w3.org>
Sent: Sunday, December 13, 2009 6:34 PM
Subject: Re: magetab2magerdf
Hi Jim, Michael,
The following paper describes how to convert mage-tab and
isa-tab (how does this differ from mage-tab?) into DAG for visualization
purposes.
http://www.biomedcentral.com/1471-2105/10/133
Why not DAG for machine readability as well?
Cheers,
-Kei
mdmiller wrote:
hi jim,
looks like you're making great progress. i have a few comments
in-line below.
cheers,
michael
----- Original Message ----- From: "Jim McCusker" <
james.mccusker@yale.edu>
To: "w3c semweb HCLS" <public-semweb-lifesci@w3.org>
Sent: Tuesday, December 08, 2009 6:05 AM
Subject: magetab2magerdf
I'm distinguishing between magetab2rdf (raw conversion of
magetab into
an RDF structure) and magetab2magerdf (conversion of magetab
into an
RDF-based MAGE-OM structure) here. My purposes and goals require
a
magetab2magerdf approach, so that's what I've been working on.
I have checked in code for magetab2magerdf at the googlecode
project
http://magetab2rdf.googlecode.com. The code can be checked out
from:
http://magetab2rdf.googlecode.com/svn/trunk/magetab2magerdf/
and example RDF is in:
http://magetab2rdf.googlecode.com/svn/trunk/magetab2magerdf/examples/E-M
EXP-986/
I currently load the IDF-related entities into the RDF. I'm
beginning
work on SDRF next.
http://magetab2rdf.googlecode.com/svn/trunk/ontologies/mage-om.owl
contains the additional properties and classes needed to support
an
RDF-based MAGE-OM on top of the MGED Ontology.
A few notes on E-MEXP-986:
The URI for the MGED Ontology is
http://mged.sourceforge.net/ontologies/MGEDontology.owl, but has
been
set to http://mged.sourceforge.net/ontologies/MGEDontology.php
in the
IDF. The actual Term Source name is "The MGED Ontology".
A common practice seems to be to refer to "MGED Ontology"
without
reference to its URI.
as you probably noticed,
http://mged.sourceforge.net/ontologies/MGEDontology.php allows appending
"#{class name}" to go directly to the definition of the term, so in a
sense it is indeed a valid URI, that is a URL. it also came before the
owl format. can th epowl format be reached into over he net to extract
simply the class definition or does it need to be downloaded and
processed locally? my understanding is that a site would have to have
some sort of query, hopefully sparql, mechanism on top to enable this.
Since I have to import the MGED ontology already for it's
classes and
properties, I have already imported it under the correct URI. I
have
added a kludge where if the term source name contains the string
"MGED
Ontology", the code assumes you mean the MGED Ontology, and sets
the
URI appropriately. However, this is a one-off solution.
think of it as same as
I went back and forth about importing the Term Source
ontologies.
However, this particular experiment has used the "ArrayExpress"
term
source using the URI "http://www.ebi.ac.uk/arrayexpress/" which
doesn't correspond to an available ontology, but is technically
a term
source.
yes, and it does support a query mechinism, albeit a one off for
that site. i believe they plan on adding support for a sparql endpoint
but aren't sure if or when.
I'm considering attempting to import the ontology if it's
available
and validate if it is, but if it fails to resolve to a document
the
validation will not happen against that term source.
A note on Limpopo:
The IDF Comment didn't seem to import on this experiment. I'm
not sure
if it's a format problem or something else.
i ran into this also, the implementation assumes
"Comment[type]\ttext\ttext..." to coresspond to the format of the other
fields in the IDF. the MAGE-TAB 1.0 spec doesn't address, my assumption
was that it was simply "Comment[type]text" but that's not what the
parser expects. we'll be discussing this for the MAGE-TAB 1.1 spec to
clarify it one way or another, possibly updating the parser before that.
Thoughts and feedback are greatly appreciated.
Jim
--
Jim McCusker
Programmer Analyst
Krauthammer Lab, Pathology Informatics
Yale School of Medicine
james.mccusker@yale.edu | (203) 785-6330
http://krauthammerlab.med.yale.edu
PhD Student
Tetherless World Constellation
Rensselaer Polytechnic Institute
mccusj@cs.rpi.edu
http://tw.rpi.edu
--
Jim
--
Jim McCusker
Programmer Analyst
Krauthammer Lab, Pathology Informatics
Yale School of Medicine
james.mccusker@yale.edu | (203) 785-6330
http://krauthammerlab.med.yale.edu
PhD Student
Tetherless World Constellation
Rensselaer Polytechnic Institute
mccusj@cs.rpi.edu
http://tw.rpi.edu
Attachments
- image/png attachment: image003.png
Received on Wednesday, 6 January 2010 16:11:44 UTC