- From: Thad Guidry <thadguidry@gmail.com>
- Date: Sat, 20 Jul 2019 14:31:35 -0500
- To: Antonin Delpeuch <antonin@delpeuch.eu>
- Cc: public-reconciliation@w3.org
- Message-ID: <CAChbWaOkL3YR9AKF2S0LJz9=P2qLtkpRSX3KgksNLT6J3wYLOw@mail.gmail.com>
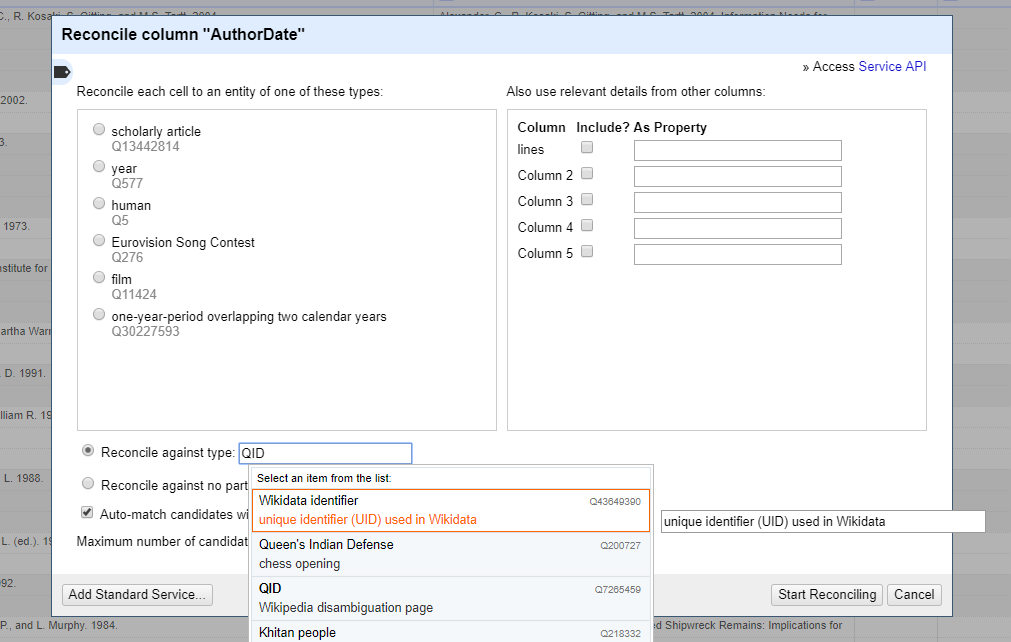
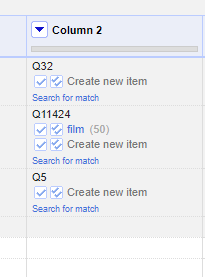
*On OpenRefine platform:* I do think that getting free text feedback is a good idea. The most effective feedback we have ever had was always through one-on-one interactions with users themselves and listening through the datasets they bring or interested in. So putting OpenRefine in the hands of others and recording their habits is quite useful. I have found that bringing a unique perspective is sometimes surfaced by giving users unusual datasets to try to reconcile, instead of just allowing them to reconcile their own datasets. Hosting a Reconciliation Day is a good option to gather feedback and record it. Perhaps getting someone to sponsor it with Beer and Pizza will open more mouths to speak as well :-) *Regarding matching by External identifiers:* OpenRefine's earlier version with Freebase Recon had the option to match solely against MQL ID's. OpenRefine lost this ability in newer versions. The current version of OpenRefine (screenshots) has the ability technically, but it is not so evident to inexperienced users and also does not give effective results currently. This could be an improvement on both sides, where the UI exposes an option to "Reconcile against a Recon Entity ID" and the Recon Service performs lookups exclusively against Entity ID's in its service offering. If Multiple types of Entity ID's are exposed by a Recon service offering, then those should be exposed in the UI to the user, perhaps in a similar dropdown box that is enumerated only with Identifier Types. In the case of Wikidata, I think there are 5 Entity Identifier Types now, maybe more with Lexemes (L), Forms (F) and Senses (S)? [image: Annotation 2019-07-20 141855.png] [image: Annotation 2019-07-20 141915.png] Thad https://www.linkedin.com/in/thadguidry/
Attachments
- image/png attachment: Annotation_2019-07-20_141855.png
- image/png attachment: Annotation_2019-07-20_141915.png
Received on Saturday, 20 July 2019 19:32:12 UTC