- From: Pat Hayes <phayes@ihmc.us>
- Date: Sat, 15 Jun 2013 10:43:21 -0500
- To: Antoine Zimmermann <antoine.zimmermann@emse.fr>
- Cc: "Peter F. Patel-Schneider" <pfpschneider@gmail.com>, RDF WG <public-rdf-wg@w3.org>
- Message-Id: <F61FB885-71B6-4D9F-990F-7FC3B2B29646@ihmc.us>
On Jun 14, 2013, at 11:26 AM, Antoine Zimmermann wrote:
> Pat,
>
>
> Please, before answering comments one by one while reading, please read on. I myself was guilty to answer your comments before reading all through, and I think I would have answered differently otherwise.
Yes, OK. So rather than give line-by-line responses, I will try to cut to the main point in each of the two big issues. Most of your smaller edits are just going in without debate.
> I mean: I do not change my mind, but some of the arguments I give later can reinforce the arguments I give sooner.
> I would also appreciate Peter to read and ponder my comments too, and perhaps give an opinion.
I believe he is intending to do that, of course.
> What is at stake here is the possibility of a formal objection.
Sounds like we might have one of these whichever way we go :-)
> AZ.
>
> Le 14/06/2013 08:32, Pat Hayes a écrit :
>>
>> On Jun 12, 2013, at 5:53 AM, Antoine Zimmermann wrote:
>>
>>> Pat, Peter,
>>>
>>>
>>> This is my review of RDF 1.1 Semantics. Sorry for sending this so
>>> late. On the plus side, I'd say that overall, the presentation have
>>> been much improved, interpretations being independent from a
>>> vocabulary is a big bonus, making D-interpretations independent
>>> from the RDF vocabulary is also much better. Putting the rules in
>>> context with the corresponding entailment regime is also good.
>>>
>>> Now, for the main criticism, I have two outstanding problems with
>>> the current version: 1. D-entailment using a set rather than a
>>> mapping; 2. Define entailment of a set as entailment of the union.
>>>
>>>
>>> 1. D-entailment ===============
>>>
Rather than respond point-by-point, check out the changes I have made to sections 8 and 9 to see if they cover your concerns. I know you want to revert to the previous definitions, but I do not, so ask yourself if these changes address the technical objections. I belive they do.
Section 8 first para now reads:
Datatypes are identified by IRIs. Interpretations will vary according to which IRIs they recognize as denoting datatypes. We describe this using a parameter D on interpretations. where D is the set of recognized datatype IRIs. We assume that recognized IRIs identify a unique datatype wherever they occur, and the semantics requires that they refer to this identified datatype. The exact mechanism by which an IRI identifies a datatype IRI is considered to be external to the semantics. RDF processors which are not able to determine which datatype is identifier by an IRI cannot recognize that IRI, and should treat any literals type with that IRI as unknown names.
and the second semantic condition on datatyped literals reads:
For every other IRI aaa in D, I(aaa) is the datatype identified by aaa, and for every literal "sss"^^aaa, IL("sss"^^aaa) = L2V(I(aaa))(sss)
and the change note reads:
In the 2004 RDF 1.0 specification, the semantics of datatypes referred to datatype maps. The current treatment subsumes datatype maps into the interpretation mapping on recognized IRIs.
Note, the term "identifies" is defined earlier to mean any external assignment of a meaning to an IRI.
>>> ....
>>> Finally, the reasons why this change has been made are unclear.
>>
>> It was an editorial decision, to make the exposition simpler and
>> easier to understand. (I would add that putting datatype maps into
>> the semantics in the first place was also an editorial decision.) It
>> does not materially change the semantics and does not affect any
>> entailments.
>
> It's not editorial, it changes what can be concluded from being a D-entailment. Basically, it cancels the conclusions that you could do when knowing the map D. Now you have to know D as well as some external things that are not indicated in the formal definitions.
It does not change any entailments. Just as before, you need to know what datatypes your datatype IRIs map to. You had to know that in 2004, and you still have to know it. The WAYS that you know it were mysterious in 2004, and they are slightly less mysterious now, but at least now they speak only of what the IRI refers to, instead of invoking some mysterious relationship only known to datatyping but not defined in any datatype specification anywhere. And the actual statement of the semantic conditions is now simpler and more intuitive than it was.
....
>
> It does not simplify. It obscures it by having the required mapping being evoked outside the formal definitions. The mapping is still required but the requirement is hidden. It is not even clear whether the requirement, indicated in prose somewhere, actually holds in the definition of D-entailment.
I disagree.
>> As
>> it has been repeatedly asserted that understanding the arcane
>> specification documents is the greatest barrier to RDF deployment,
>> this is not a trival motivation.
>
> It is not arcane, it is a *mapping*, a simple math structure that everybody meets at school.
What is unclear is that this datatype mapping is simply a restriction of the interpretation mapping, not a separate piece of mathematical machinery. So giving it another name is confusing, and not necessary. We can use the interpretation mapping itself to do the same work.
...
> I repeat: there is zero motivation to make such a change.
I repeat: I disagree. And it is not a change to any entailments or even to the actual semantics, except in how it is expressed.
> If you are not convinced after all that, we'll have to decide with a vote. If the vote is on your side, we'll proceed to Last Call and future phases with a formal objection from my side.
Frankly, I think it would be petty to lodge a formal objection over this particular issue. But that is just my opinion.
----------------
Now, the next one is more important.
Reading all through this entire correspondence, it is clear that we have fundamentally different notions of what RDF blank nodes mean. I think I now understand yours, and that you may understand mine, though I am less sure of that.
So, let me try to explain about blank nodes. In a nutshell, blank nodes are not like existential variables. They are like *tokens* of existential variables. The difference is key. A blank node cannot occur in two places, because there is only one of it.
> Compare FOL formulas: given the variable x, taken from te infinite set of variables, consider the formulas:
>
> ∃x P(x)
> ∃x Q(x)
>
> These formulas share a variable.
Not in this same sense of "share". They both use the same variable *name* in different local scopes. But in FOL, just like most languages, there is a type/token distinction: one name, four tokens, two in each scope. Each token has to be considered in its own scope. But blank nodes don't have any type/token distinction like this: they are single, unique entities. A single bnode cannot occur in two places, once in one scope and in the other place in a different scope. It is basically a place in a graph, and a place can't be in two places.
I might add, this is not an accident. We *designed* RDF to be like this in 2002, and it was a deliberate design decision to try to keep the graph operations simple. We did not want to burden the semantic web world with having to keep track of free versus bound variabels and quantifer scopes.
> From these two formulas, I conclude:
>
> ∃x∃y P(x),Q(y)
>
> I have to separate apart the existentials to make it into a single formula.
Yes, exactly, those are the local-scope rules in action. But bnodes are simply defined as elements of a set. So none of this analogy with a conventional surface syntax is really relevant to blank nodes in the RDF graph syntax. (It is, of course, relevant to how to handle blank node IDs, which are exactly similar to these bound x's and y's in a Fregean notation.)
> If, by chance, you have extra knowledge that the x having property P is precisely the x that has property Q, you could simplify this into:
>
> ∃x P(x),Q(x)
>
> But it is saying more than the initial formulas. Bnodes are existentials
They are like *tokens* of existentials, and so their meaning is not dependent upon the graph they occur in. Consider
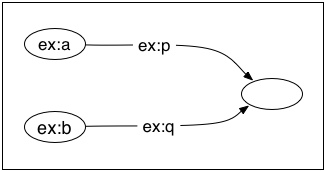
ex:a ex:p _:x .
ex:b ex:q _:x .
This graph has three nodes in it. It looks like this:
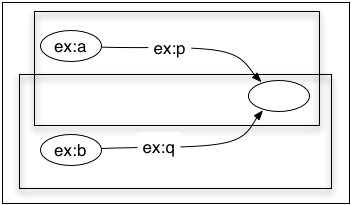
If we consider this as a combination of two subgraphs sharing a blank node, then the blank node is not written twice, once in each subgraph. It - the exact same bnode - occurs in both graphs. So, taken together, the two graphs (sharing that blank node) still have only three nodes, and still assert that there is a single thing that both graphs are true of, just as the combined graph does. That is what "sharing a blank node" means. It looks like this:
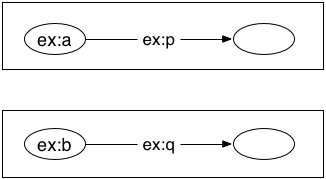
*not* like this, which has a different meaning:
You are right to point out that with our current truth conditions for bnodes and graphs, the truth of the two separate single-triple subgraphs is not enough to guarantee the truth of this graph. IMO, that is a problem with the truth conditions for blank nodes, because the two subgraphs of the graph - of any graph, in fact - clearly *should* entail their union. It does not make sense to say that if we simply take those two subgraphs and then recombine them, that a three-node graph would be transformed into a four-node graph.
I changed the notion of entailment by a set to correct this problem, as it seemed to be the simplest way to do it. But changing the bnode truth conditions might be a better way to do it.
...
> , so if you have two graphs that share the bnode b:
>
> {(b,<p>,<o>)} and {(b,<q>,<u>)}
>
> then you can define their meaning as:
>
> ∃x Triple(x,<p>,<o>)
> ∃x Triple(x,<q>,<u>)
No. If they really do share the bnode, then their meaning is
exists x (Triple(x, <p>,<o>) & Triple(x, <q>,<u>) )
The difference between (exists.. ( ..&...) ) and (exists ... (...) & exists ...(...) ) is exactly what we mean by "sharing" a bnode.
> Trivially, the conjunction of those graphs ought to be:
>
> ∃x∃y Triple(x,<p>,<o>),Triple(y,<q>,<u>)
>
> If it's not, then there is something really broken in RDF Semantics.
What we have to say is that combining two graphs is not always a simple as taking the conjunction of their logical translations. You cannot fully mirror RDF graph syntax operations by translating it into FOL. (Which is why I deeply regret ever suggesting the analogy in the 2004 document.) There is no pair of two FOL expressions which corresponds exactly to two RDF graphs sharing a blank node, because FOL variable scopes cannot extend across expressions. Combiining two expressions which share a common part is not like conjoining two expressions which both contain tokens of the same variable. It is an operation which takes
(exists x)(P x)
and
(exists x)(Q x)
and creates
(exists x)(Px & Qx)
knowing that the two x's bound by the two quantifiers are the same x, which is not something that can be indicated in a conventional FOL linear syntax. So it is a valid operation, even though that inference in FOL would not be valid.
There is no such combinator in FOL syntax. (There is, however, is a number of other logical syntaxes, in particular Peirce's existential graphs, which is probably the first modern logical syntax.) Graphically it is simply laying one graph over the other so that their nodes line up. In the set-based graph model it is taking the union of two sets of triples which share a bnode.
--------------
>> ...BnodeIDs are part of a surface syntax and obey the scoping
>> rules of that surface syntax. Those rules determine when two bnodeIDs
>> identify the same bnode, and (implicitly) when they don't. Once that
>> is all worked out, then we define operations on the graphs (not on
>> the surface documents), and it is these operations on the graphs that
>> we are describing here. In 2004, you could do all this surface
>> bnodeID standardizing apart, and you could STILL be left with a
>> situation where the actual blank nodes needed to be "standardized
>> apart" even after all the bnodeIDs had been dealt with.
>
> What? I don't understand what you are saying
I was rather afraid that you did not.
Look, there is a problem in the 2004 specs. Maybe you never realized that this problem is there, and if so, you would not be alone in this. I will have to give some history, so bear with me.
in about 2002 we had to come up with a formal semantics for this loosely-defined graph syntax that the first RDF group had invented. A major problem was that we didnt really have any kind of formal grammar for RDF, only a strong intuition that graphs (rather than RDF/XML, the only other alternative at the time) were the best place to attach the semantics to. So, we had to formalize the idea of an RDF graph well enough to attach a semantics to it, and the set-of-triples account is the result. We didn't have to define a graph as a set of triples, and in fact we spent some time looking at graph theory to find a ready-made formalization, but they were all way too complicated, so we made up our own. But anyway, we have this idea of RDF syntax as being graphs defined as sets of triples.
We have these nodes in a graph that have no text on them. It seems pretty clear what they mean: they assert that something exists. Just like a node in a Peircian existential graph, in fact. And so we bulit up from there. This seemed to me to be a really helpful simplification, because it did away with the complications of local bound variables, the ideas of variable binders and scoping and so on, which are notoriously hard to get exactly right in logical notations (I like to tell students that the definition of substitution of an expression for a variable is the only definition that Alonzo Church ever got wrong in print.) And all was going OK, until I realized that because we had simply defined bnodes to be elements of a set, there was nothing whatever preventing the same bnode to just happen to occur in two unrelated graphs, without anyone planning that or even knowing about it. What if a graph described by an RDF document in Australia in 2010 happened, by chance, to use the same bnode as a graph described by a document written in Zanzibar in 2013? The situation would be like taking two graphs like in the third illustration above, and *discovering* that, although nobody knew or had planned this, they were in fact joined at one blank node, like in the second illustration. Of course this is nonsense, but out formal definitions couldn't rule it out, so we had to deal with the possibility.
This is not the same issue as standardizing apart blank node *identifiers*. People often read the RDF specs talking about merging and standardizing apart, and think this is all about local scoping of bnode IDs. But no, this is **in the graph syntax itself**. The problem is basically that by simply saying that blank nodes are elements of some set, we gave them an independent notion of identity which they should never have been allowed to have. A blank node is just a place in a graph. It isnt really meaningful to ask whether a node in one graph is identical to a place in another graph, but we made that question be meaningful in the RDF graph syntax definitions. There really is nothing corresponding to this in a conventional FOL syntax, but imagine if we had said that a bound variable identifies an "existential nexus" or some such thing, and then had to worry that two completely unrelated expressions might happen to identify the same nexus by accident.
We realized all this rather late in the process, probably because it was such a crazy idea that nobody thought ot it, but the fact is that once we did realize it, we had to deal with it. The only way I could think of, and I hated it at the time, was to replace the intuitively obvious process of taking the union of two graphs by this more elaborate notion of merging them, which separated out any cases where the same bnode got re-used by accident.
So, the whole idea of merging graphs was only introduced in order to handle this ridiculous case. Before then, nobody had even thought of doing anything with two graphs other than taking the union of the sets of triples: that was the whole *point* of the set-of-triples way of formalizing the graph syntax intuitions, that we could describe all the basic operations in terms of these sets. Merging was introduced only reluctantly as a kind of last-minute patch to make the semantics work properly given this glitch in the abstract syntax model; and what it did was make the RDF model almost as complicated as a conventional FOL syntax, because we had to have something like the local/global distinction even when the whole point was to get rid of it.
So, long story short, the only reason for talking about merges rather than unions was to handle this crazy possibility, which was not planned or forseen, and which is a completely artificial problem arising, basically, from a bug in our set-theoretic model of graph syntax. And now, in 2013, we have managed to deal with that silly idea by more careful wording, there is no longer any reason for having the merge notion; particularly as when graphs CAN share a bnode, it is actually subtly wrong.
> , but there are no APIs that are unable to perform a merge correctly.
I don't think any of them actually perform merges *on graphs*. How do they detect identity of blank nodes in graphs from disparate sources?
------------
> What do you mean by "the semantic rules for bnodes"? Do you mean the "Semantic conditions for blank nodes"?
Yes, that is what I meant. But I think just defining entailment by a set of graphs as entailment by their union is the simplest fix. How else would any application treat a set of sets of triples as an antecedent for reasoning, other than simply by using the triples as though they are all in one big set?
> These ones actually support my claims. You may want to modify them to support your claim.
In an earlier draft, they were.
> For instance, try:
>
> """
> If E is an RDF graph then I(E) = true if [I+A](E) = true for some mapping A from the set of all blank nodes to IR, otherwise I(E)= false.
> """
That is an elegant idea, but I don't think it achieves the necessary result. Consider an interpretation with IEXT(I(ex:ap))={<1, 1>} and IEXT(I(ex:q))={2, 2} and I(ex:a)=1 and I(ex:b)=2. Even with the universal bnode mapping, this satisfies the singleton graphs but not the union graph. The problem is not the other bnodes, but the fact that other triples containing *this* bnode are being ignored.
The only way to really fix the bnode truth conditions is to have them apply not to arbitrary graphs, but to collections of graphs linked by bnodes ("RDF molecules"), ie to sets of all the triples in a single bnode scope. Which does, you must surely admit, make sense.
Pat
------------------------------------------------------------
IHMC (850)434 8903 or (650)494 3973
40 South Alcaniz St. (850)202 4416 office
Pensacola (850)202 4440 fax
FL 32502 (850)291 0667 mobile
phayesAT-SIGNihmc.us http://www.ihmc.us/users/phayes
Attachments
- text/html attachment: stored
- image/jpg attachment: example3.jpg
- image/jpg attachment: example5.jpg
- image/jpg attachment: example6.jpg
Received on Saturday, 15 June 2013 15:43:59 UTC