- From: Greg Eck <greck@postone.net>
- Date: Mon, 7 Sep 2015 13:55:10 +0000
- To: "jrmt@almas.co.jp" <jrmt@almas.co.jp>, 'Richard Wordingham' <richard.wordingham@ntlworld.com>, "public-i18n-mongolian@w3.org" <public-i18n-mongolian@w3.org>
- Message-ID: <SN1PR10MB0943ED3F9C559D1A6DA3FF43AF540@SN1PR10MB0943.namprd10.prod.outlook.com>
Hi Jirimutu,
Let me respond in place below
>>>>>
But we are handling the compound names as below now.
Because as we know all of the override case is the un-dotted medial NA follows the vowel, but the vowel will be written as the abnormal forms with one tooth.
.....
U+1828 N ←First Medial Form (un-dotted medial NA)
If (Initial_Vowel+N+Mongolian_Vowel+ is not FVS1-3) OR (Medial_Vowel+N+Mongolian_Vowel+ is not FVS1-3)
then N ← Second Medial Form (dotted medial NA)
.....
It is means that we saw the <medial Vowel, FVS1-3> as the abnormal vowel, the medial NA will remain the un-dotted form.
>>>>>
Greg's Response: Given the case of [cid:image001.jpg@01D0E9B0.7720D260] how do we instruct a user to type this word?
>>>>>
As my point of view, it is ok to prepare this <NA, FVS2> override mapping rule for medial NA.
But we consider all of these kind of characters which have contextual toggles.
Maybe you say it is only the medial (I, NA, GA), final GA exist this problem.
I can raise medial (OE, UE, QA, DA, YA, WA, ) additionally, even if there are no proper word example, maybe we need to write one mistaken word to show the mistake.
>>>>>
Greg's Response:
The over-ride as I am defining it is characterized by a default glyph which needs to be distinguished from another glyph’s common context by the use of an FVS. As I look through the list, I only see 4. There will be another over-ride that I have not mentioned at U+1836. If there are over-rides needed at OE, UE, QA, DA, WA, please bring them forward.
>>>>>
Do we need to prepare this kind of extra mapping encoding ?
Our solution is that we do not need this kind of extra encoding rule for these requirement.
We only use NIRUGU or ZWJ to clear the contextual rules and show the default form.
....NIRUGU + NA + NIRUGU ...... or .....ZWJ + NA + ZWJ will always be the un-dotted form.
....NIRUGU + GA + NIRUGU ...... or .....ZWJ + GA + ZWJ will always be the un-dotted form.
>>>>>
Greg's Response:
If we do not assign the four over-rides under discussion now (U+1822Medial+FVS2, U+1828Medial+FVS2, U+182DMedial+FVS2, U+182DFinal+FVS1), then how will newly-starting font designers know that current font designers are implementing these assignments? We need to come to agreement on where the assignment occurs and put the assignment on paper so that future works will be compatible with past font design. I do not see this as an extra encoding rule.
Attachments
- image/jpeg attachment: image001.jpg
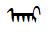
Received on Monday, 7 September 2015 13:56:33 UTC