- From: <jrmt@almas.co.jp>
- Date: Sat, 1 Aug 2015 23:10:44 +0900
- To: "'Greg Eck'" <greck@postone.net>
- Cc: <public-i18n-mongolian@w3.org>
- Message-ID: <007d01d0cc63$dbb1de00$93159a00$@almas.co.jp>
Hi Greg,
>This is what I have so far …
>{ALetter | Numeric} x [Extend] x NNBSP x ALetter
> {} denotes one mandatory item
> [] denote an optional item
> I am not sure that we need to break out a new class such as MLetter ??
> I am puzzling over the 5th bullet item. I don’t see where we would need be concerned with breaking after punctuation.
> Could you provide some examples that we need to be concerned with?
When we specifically point out one book, thing or person (just like “the” in English), we use 《》, (), <>, [] etc.
For Example: 《ᠬᠠᠭᠤᠴᠢᠨ ᠬᠦᠦ》 ᠶᠢᠨ ᠵᠣᠬᠢᠶᠠᠯᠴᠢ. But I think we can work around this only if the MSuffix is correctly formatted.
But according to Siqin’s Example,
<ᠬᠤᠪᠢᠰᠭᠠᠯ> ᠤᠨ
The MSuffix incorrectly formatted in some of the browser and tools he listed in his mail before.
> On the 6th bullet item, I prefer the solution to be to use the ZWJ/ZWNJ to display a given isolate (suffix or otherwise).
> Can you give an example of where the ZWJ/ZWNJ would not give the same result as the 6th bullet item result?
In some case we will list the NNBSP x MSuffix in the start of a line, for example we are explaining the suffix usage in the text.
The "ZWJ MSuffix" will not be able to cover "NNBSP MSuffix", because NNBSP have another suffix formatting facility in Mongolian Usage.
It will become "ZWJ NNBSP MSuffix", if we need to use ZWJ to prevent the NNBSP come to start of a line.
But we prefer "NNBSP MSuffix" because when user copy one Suffix to another line to explain the MSuffix, they will not aware to have to input one ZWJ before NNBSP.
For Example:
NNBSP + (U1836+U1822+U1828) ᠶᠢᠨ
But if we use ZWJ + (U1836+U1822+U1828) , It will become ᠊ᠶ᠋ᠢᠨ (It is ᠊ᠶᠢᠨ now with Mongolian Baiti now. We have strong different opinion on this, we can discuss this later.)
But if we use ZWNJ + (U1836+U1822+U1828) , It will become ᠶᠢᠨ
NNBSP + (U1824+ U1828) ᠤᠨ
But if we use ZWJ + (U1824+ U1828) , It will become ᠊ᠤᠨ
But if we use ZWNJ + (U1836+U1822+U1828) , It will become ᠤᠨ
The ZWJ/ZWNJ could not match the requirements, only ZWJ/ZWNJ + NNBSP + MSuffix can match the requirements.
But why we have to use one more character to match the requirements, when the NNBSP+MSuffix can match the requirements.
This is our team’s consideration.
When we use ZWJ/ZWNJ in Mongolian, the main purpose is to format the following character.
But if there is one NNBSP between ZWJ/ZWNJ and Mongolian character, it will lost their format control to the Mongolian character after NNBSP actually.
Thanks and Best Regards,
Jirimutu
==========================================================
Almas Inc.
101-0021 601 Nitto-Bldg, 6-15-11, Soto-Kanda, Chiyoda-ku, Tokyo
E-Mail: <mailto:jrmt@almas.co.jp> jrmt@almas.co.jp Mobile : 090-6174-6115
Phone : 03-5688-2081, Fax : 03-5688-2082
<http://www.almas.co.jp/> http://www.almas.co.jp/ <http://www.compiere-japan.com/> http://www.compiere-japan.com/
==========================================================
From: Greg Eck [mailto:greck@postone.net]
Sent: Saturday, August 1, 2015 6:34 PM
To: jrmt@almas.co.jp
Cc: public-i18n-mongolian@w3.org
Subject: RE: Mongolian NNBSP [I18N-ACTION-458]
Jirimutu,
Good to have your input. Some of my thoughts are similar to those of Richard Wordingham.
This is what I have so far …
{ALetter | Numeric} x [Extend] x NNBSP x ALetter
{} denotes one mandatory item
[] denote an optional item
I am not sure that we need to break out a new class such as MLetter ??
I am puzzling over the 5th bullet item. I don’t see where we would need be concerned with breaking after punctuation. Could you provide some examples that we need to be concerned with?
On the 6th bullet item, I prefer the solution to be to use the ZWJ/ZWNJ to display a given isolate (suffix or otherwise). Can you give an example of where the ZWJ/ZWNJ would not give the same result as the 6th bullet item result?
Greg
From: jrmt@almas.co.jp [mailto:jrmt@almas.co.jp]
Sent: Saturday, August 1, 2015 1:45 PM
To: Greg Eck <greck@postone.net>; 'Andrew West' <andrewcwest@gmail.com>; 'Badral S.' <badral@bolorsoft.com>
Cc: public-i18n-mongolian@w3.org
Subject: RE: Mongolian NNBSP [I18N-ACTION-458]
Hi All
I am coming back to Office now and I can spend more time to read the discussion mail as well as study the Unicode Property Definition rule.
It is fine to us, if we can ask to change NNBSP word break property to fit the Mongolian Suffix requirements.
According to my understanding,
1. The NNBSP word break property should be changed to MidLetter to fit Mongolian Suffix usage.
l MLetter x NNBSP x MSuffix : MLetter -> Mongolian Letter, MSuffix -> Mongolian Suffix
l ALetter x NNBSP x MSuffix : ALetter -> Alphabet Letter
l Numeric x NNBSP x MSuffix : Numeric (digit and Mongolian digit)
l MLetter(Extend|Format) x NNBSP x MSuffix : Extend | Format -> FVS1-3, ZWNJ, ZWJ etc)
l Some_Punctation x NNBSP x MSuffix : Some_Punctation like )>]” ‘ etc. (If this is not possible to define separately, we can replace it with following isolate Mongolian Suffix)
l NNBSP x MSuffix : We need to support the isolate Mongolian Suffix exist
2. The NNBSP line break property should be remained as GL() , not BA (= "break after").
GL *
Non-breaking (“Glue”)
NBSP, ZWNBSP, WJ,CGJ
prohibit line breaks before or after.
Thanks and Best Regards,
Jirimutu
==========================================================
Almas Inc.
101-0021 601 Nitto-Bldg, 6-15-11, Soto-Kanda, Chiyoda-ku, Tokyo
E-Mail: <mailto:jrmt@almas.co.jp> jrmt@almas.co.jp Mobile : 090-6174-6115
Phone : 03-5688-2081, Fax : 03-5688-2082
<http://www.almas.co.jp/> http://www.almas.co.jp/ <http://www.compiere-japan.com/> http://www.compiere-japan.com/
==========================================================
From: Greg Eck [mailto:greck@postone.net]
Sent: Saturday, August 1, 2015 10:08 AM
To: Andrew West; Badral S.
Cc: public-i18n-mongolian@w3.org
Subject: RE: Mongolian NNBSP [I18N-ACTION-458]
Hi Andrew,
The case that Badral is referring to is a numeric digit followed by the ordinal suffixes DUGAR/DUEGER and DAQI/DEQI.
Specifically – a Latin digit OR a Mongolian digit followed by NNBSP followed by one of the four ordinal suffix forms DUGAR/DUEGER/DAQI/DEQI would be considered normal and the sequence should not be broken.
Here are two examples ...
<U+0031><U+202F><U+1833><U+1826><U+182D><U+1821><U+1837 >
<U+0032><U+202F><U+1833><U+1824><U+182D><U+1820><U+1837 >
cid:image001.jpg@01D0CC71.54B2A930
Badral, please confirm.
Greg
PS I am attaching a DS05 dealing with all known usages of the NNBSP in Mongolian. The file includes both text strings as well as images. The ordinal section is on page 4.
-----Original Message-----
From: Andrew West [ <mailto:andrewcwest@gmail.com> mailto:andrewcwest@gmail.com]
Sent: Saturday, August 1, 2015 4:12 AM
To: Badral S. < <mailto:badral@bolorsoft.com> badral@bolorsoft.com>
Cc: <mailto:public-i18n-mongolian@w3.org> public-i18n-mongolian@w3.org
Subject: Re: Mongolian NNBSP [I18N-ACTION-458]
On 31 July 2015 at 19:50, Badral S. < <mailto:badral@bolorsoft.com> badral@bolorsoft.com> wrote:
>
>>> What is the context for "Numeric NNBSP Aletter" ? ExtendNumLet would
>>> inhibit a word break after a numeric, but I think that MidLetter
>>> would not.
>
> Then MidLetter is correct. A word break after a numeric is incorrect.
I still do not know what the context for this use case is. Is it normal to have "Numeric NNBSP ALetter"? Can you provide an example?
Andrew
Attachments
- image/jpeg attachment: image001.jpg
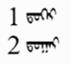
Received on Saturday, 1 August 2015 14:11:10 UTC