- From: Michael Herman (Trusted Digital Web) <mwherman@parallelspace.net>
- Date: Tue, 21 Dec 2021 13:06:56 +0000
- To: Melvin Carvalho <melvincarvalho@gmail.com>, Ted Thibodeau Jr <tthibodeau@openlinksw.com>
- CC: W3C Credentials CG <public-credentials@w3.org>
- Message-ID: <MWHPR1301MB2094E914755F0255EA5436F0C37C9@MWHPR1301MB2094.namprd13.prod.outlook.>
At the risk of being repetitious, we need to be following the #OpenToInnovation principle: https://hyperonomy.com/2019/03/12/internet-protocols-and-standards-not-only-need-to-be-open-but-more-importantly-open-to-innovation/
Also, from a systems architecture perspective, we need to have:
i) A DID Identifier/Method specification that is separate from…
ii) a DID Protocol specification (e.g. something like “DID Trusted Transport Protocol” aka “didttp”). …that is, something analogous to HTTP that natively understands/supports DID Identifiers/Methods
…the same way DNS and HTTP are separated and have separate naming and protocol specifications, respectively.
The current DID-CORE specification tries to conflate the 2 and I believe that’s a root cause of the current situation we find ourselves in.
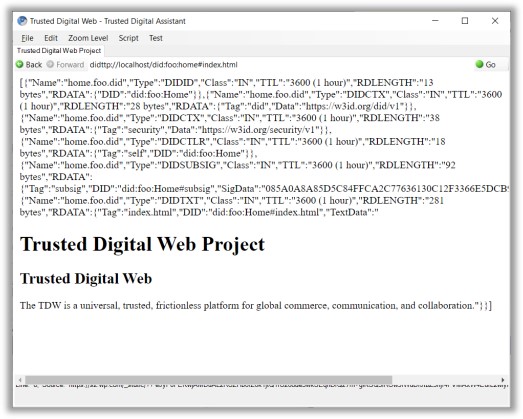
Here’s an practical working illustration of what I’m proposing (source: https://hyperonomy.com/2019/12/03/trusted-digital-web-first-trusted-web-page-delivered-today-dec-3-2019/) …
[TDW3b]
From: Melvin Carvalho <melvincarvalho@gmail.com>
Sent: Tuesday, December 21, 2021 1:46 AM
To: Ted Thibodeau Jr <tthibodeau@openlinksw.com>
Cc: W3C Credentials CG <public-credentials@w3.org>
Subject: Re: DID Formal Objection Status Update (Dec 2021)
On Tue, 21 Dec 2021 at 04:46, Ted Thibodeau Jr <tthibodeau@openlinksw.com<mailto:tthibodeau@openlinksw.com>> wrote:
Hmmmmm
On Dec 20, 2021, at 04:25 PM, Melvin Carvalho <melvincarvalho@gmail.com<mailto:melvincarvalho@gmail.com>> wrote:
So my thought process was as follows:
1. did:method: ## this is a sub protocol
2. did:method:name ## this is a name space within the sub protocol
Let's compare with:
1. http: ## this is a protocol
2. http://mycorporation<http://mycorporation/> ## this is a name space with in the protocol
I would say, rather, starting with the well-known --
1. http: ## this is a URI scheme, which often but does not always
## map to a protocol, and which one's browser and/or OS
## usually maps to a handler/helper app (sometimes with
## help from the user)
2. http://example.com ## this is a namespace within the scheme
3. http://example.com/index.html ## this is the stuff within the
## namespace within the scheme
Yes, http: maps rather to the HTTP protocol, but they are not the
same, and blurring such lines is how we get into very deep holes
as standard development proceeds.
Then, *after* covering the long-used if not as well-understood as
we might wish, I would suggest moving to the new thing we're working
to explain and understand as we go ... which I'm not going to try to
explain at this hour in my time zone.
So the idea is that (1) something that is a protocol or sub protocol, in my mind should be a technical spec, non-proprietary, open
And that (2) could be also proprietary, a per company things, for profit etc.
As we see with http and the web, that's how it works, http is neutral and any company can have a web site. It's a system that works well
The URI format is open, being RFC-specified. URI schemes and
formats are not necessarily open -- and there's no requirement
that they be so! -- nor that the scheme even be registered --
though not registering a corporate-confidential scheme and format
*might* lead to collisions on the open web, so long as there's
some cleverness by that tech team, little meaningful information
should be leaked by such...
The DID scheme, and the basic DID URI format, are open, being W3C-REC
specified. DID methods, and the format beyond the first colon, may be
mostly if not entirely proprietary.
With DID's it seems that things are more mixed. Some of the sub protocols or methods in the registry are proprietary security tokens with the aim of monetizing the protocol
It would be good to clarify the extent to which did methods can be neutral decentralized protocols, vs centralized, proprietary and monetizable
DID methods *may* be virtually if not entirely proprietary and
monetizeable -- but this will have some effect on how they get
evaluated through the rubric, which may lead to low (or high,
who can predict these things?) uptake in the general marketplace.
Decentralized IDentifiers would seem to me more valuable if they
were less proprietary and more open, in all the ways those words
might be understood -- but I cannot make this judgement for all
in the world, especially as there may be other valuable factors
which some proprietary specifier and/or implementer delivers to
their users, which those users prize more highly.
Couple of issues with this
1. W3C is supposed to be vendor neutral, any endorsement (ie w3c stamp or branding) of proprietary protocols would represent a change, and perhaps require careful optics
2. Proprietary, for profit, protocols by their very nature are so, by being centralized, even when they have distributed databases. That's will lead to misleading claims
On top of that, there's massive regulatory overhang
That's the open market for you!
Be seeing you,
Ted
--
A: Yes. http://www.idallen.com/topposting.html
| Q: Are you sure?
| | A: Because it reverses the logical flow of conversation.
| | | Q: Why is top posting frowned upon?
Ted Thibodeau, Jr. // voice +1-781-273-0900 x32
Senior Support & Evangelism // mailto:tthibodeau@openlinksw.com
// http://twitter.com/TallTed
OpenLink Software, Inc. // http://www.openlinksw.com/
20 Burlington Mall Road, Suite 322, Burlington MA 01803
Weblog -- http://www.openlinksw.com/blogs/
Community -- https://community.openlinksw.com/
LinkedIn -- http://www.linkedin.com/company/openlink-software/
Twitter -- http://twitter.com/OpenLink
Facebook -- http://www.facebook.com/OpenLinkSoftware
Universal Data Access, Integration, and Management Technology Providers
Attachments
- image/jpeg attachment: image002.jpg
Received on Tuesday, 21 December 2021 13:07:14 UTC