- From: Michael Herman (Parallelspace) <mwherman@parallelspace.net>
- Date: Wed, 2 Jan 2019 00:12:11 +0000
- To: "daniel.hardman@evernym.com" <daniel.hardman@evernym.com>, "W3C Credentials CG (Public List)" <public-credentials@w3.org>
- Message-ID: <MWHPR13MB127770E65C3A8D31D450F5A4C38C0@MWHPR13MB1277.namprd13.prod.outlook.com>
Daniel, from our 1:1 as well as group discussions (e.g. the ad-hoc Friday workshop), I believe there are 2 kinds of entities at play here:
* Actors, and
* Things.
Actors are People and Organizations …maybe a few other entities.
Things are Pets, Cars, Houses, Business Documents, Products, Assemblies, Parts, etc.
I believe these are terms that be easily projected into your discussion below.
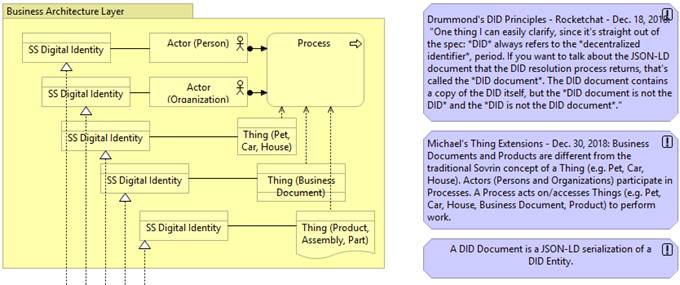
Here’s a diagram plus a few principles about how Actors and Things interact.
[cid:image001.jpg@01D4A1F5.1F62DFE0]
Business Architecture Principles
1. An Actor is either a Person or an Organization.
2. Each Person or Organization has one or more SS Digital Identities associated with it.
3. Actors (Persons and Organizations) participate in Processes.
4. A Process acts on/accesses Things (e.g. Pet, Car, House, Business Document, Product, Assembly, Part) to perform work.
5. Business Documents, Products, Assemblies and Parts are different from the traditional or generic Sovrin concept of a Thing (e.g. Pet, Car, House).
6. Each Thing has one or more SS Digital Identities associated with it.
The complete diagram (a proposed DID architecture reference model) can be found here: https://hyperonomy.com/2018/12/21/decentralized-identifiers-dids-architecture-reference-model-arm/
Does some or all of this match/fit into/simplify what you’re referring to in your email below?
Best regards,
Michael Herman (Toronto/Calgary/Seattle)
From: Daniel Hardman <daniel.hardman@evernym.com>
Sent: January 1, 2019 4:39 PM
To: W3C Credentials CG (Public List) <public-credentials@w3.org>
Subject: what do DIDs identify?
At the recent Hyperledger Global Forum in Switzerland, I had some discussions about the semantics of DIDs, and I feel like I observed a deep divide in community understanding about their intent. This causes periodic surprises and frustrations, including some that came up on the recent thread with subject "Ideas about DID explanation."
I'm going to try to contrast two divergent mental models. In reality they may not be so far apart. But I think until we see their divergence clearly, we may continue to experience mental friction when we least expect it.
1. DIDs are inherently about SSI
An inconsistently articulated but very strong assumption in this worldview is that a DID is an identifier controlled for the purpose of interaction. People, organizations, and IoT things can be behind the identifier because they are the sorts of entities for which interaction is imaginable-- but notice the "IoT" qualifier on "things": inert things cannot be DID referents. This worldview is nicely articulated by various statements in the the DID Primer and the DID Spec, such as this one: "The purpose of the DID document is to describe the public keys, authentication protocols, and service endpoints necessary to bootstrap cryptographically-verifiable interactions with the identified entity."
2. DIDs are inherently about decentralization, and SSI is just one use case
Proponents of this worldview might point to the name ("DID" = "Decentralized Identifier", not "SSI Identfier" or "Controlled Identifier") and say, "Of course we need decentralization for SSI. But we need it for other reasons, too. We should be using DIDs for lots of other stuff."
What other stuff? Well, the use cases I heard in Switzerland are pretty similar to the ones I would give for uuids: "I want a DID for every asteroid NASA discovers" or "I want a DID for {Mount Everest | each species that biologists add to the Linnaean taxonomy | each database record | flows in my ERP system | etc}". What makes these different from the classic DID use cases is that the identified item is not imagined to interact in the ways that we expect as we usually describe DID Docs. You don't set up a cryptographically secure channel over which you interact with an asteroid.
In conversations where this alternate viewpoint surfaces, I commonly hear two reactions:
Reaction A: That's not a DID use case. Use UUIDs.
Reaction B: That's a perfect DID use case. An asteroid can have an agent to facilitate digital interactions, can't it? And won't you need to talk to it (e.g., to ask its current position or to request permission to land)?
I believe neither of these reactions stands up under careful analysis, and that's why I think the topic I'm raising here is worthy of such a long email.
Here's what I think Reaction A misses: Although UUIDs are createable by anyone without central coordination, they are not resolvable. One of the wonderful properties of DIDs is that they have a defined resolution mechanism that is more decentralized than DNS, *without* requiring invisible and untrackable contextual assumptions. UUIDs lack this; you have to know to go look them up in a particular database. When people say they want a DID for asteroids, they don't just want UUID uniqueness and lack of centralized registration; they *also* want DID's resolution properties. But what they want to resolve isn't information about control, it's information about the inert object in question -- when it was first discovered, where someone can find out more, how it can be looked up on wikipedia, or dozens of other properties. (Aside: some may want another DID property as well, which is cryptographically enforced global uniqueness. UUIDs lack this property for sure. Some DID methods may lack it as well, which has been a subject of frustration on earlier threads in this group...)
This brings us to Reaction B. Proponents of this reaction would say, "You should just talk to the agent for the asteroid. No new mental model needed." But let me ask you how you think China would like it if Tibet or India registered an agent for Mount Everest. And what gives NASA or the European Space Agency the right to register (control) a DID for an asteroid that an astronomer in South Africa first observed? In other words, I think Reaction B's fatal flaw is that it thinks control is an appropriate mental model for all objects. It's not. Nobody controls a new species of mushroom that gets discovered. And nobody interacts with its agent, either. The common characteristic of asteroids, Mount Everest, biological species in a taxonomy, and other objects of this type is that they are shared concepts controlled by nobody. There must be one identifier for them, known to all--and that identifier should have no controller. Modeling them with a controller is fundamentally incorrect.
This makes me wonder if we need to be able to talk about an identifier that has the decentralized and resolvable properties of DIDs, and the pluggable methods--but that doesn't make the strong assumption that behind every DID is a control- and interaction-oriented DID Doc. Instead, it might make a lighter assumption that the DID Doc lets you discover how to learn more about an inert object.
Such an identifier could be called an "uncontrolled DID", for example. And DIDs that make the strong assumption about control could be called "DIDs" for short, or "controlled DIDs" when clarity is needed. Or we could pick other adjective pairs.
Or we could say that "DID" should only be used for the form of identifier that has strong control semantics, and that whatever the other thing is, it shouldn't be a "DID". But if we do this, we need to somehow leverage all the work we've done on DID methods and specs and documentation and implementation, without reinventing the wheel.
How would you resolve this dissonance?
Attachments
- image/jpeg attachment: image001.jpg
Received on Wednesday, 2 January 2019 00:12:39 UTC