- From: Story Henry <henry.story@bblfish.net>
- Date: Fri, 5 Mar 2010 18:55:05 +0100
- To: Jeremy Carroll <jeremy@topquadrant.com>
- Cc: Pat Hayes <phayes@ihmc.us>, Dan Connolly <connolly@w3.org>, Semantic Web <semantic-web@w3.org>, foaf-protocols@lists.foaf-project.org
- Message-Id: <CA57C826-452A-492B-9963-EDAACD4F10CB@bblfish.net>
I have read most of the "RDF semantics" document carefully now, and I think I have enough detailed understanding to try to recapitulate the discussion, and explain in detail my reasons.
STARTING WITH AN EXAMPLE: cert:hex
===================================
1. proposed definition of cert:hex
----------------------------------
I can defined cert:hex as follows (though the detailed wording could be improved)
@prefix : <http://www.w3.org/ns/auth/cert#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix vs: <http://www.w3.org/2003/06/sw-vocab-status/ns#> .
:hex a owl:DatatypeProperty, rdfs:Datatype,
owl:InverseFunctionalProperty;
rdfs:label "hexadecimal"@en;
rdfs:comment """
An encoding of a positive integer (from 0 to infinity) as a hexadecimal string that makes it easy to read and/or fun to present on the web.
The purpose of this way of representing hexadecimals is to enable users to copy and paste hexadecimal notations as shown by most browsers, keychains or tools such as opensso, into their rdf representation of choice. There are a wide variety of ways in which such strings can be presented. One finds the following
e1 dc d5 e1 00 8f 21 5e d5 cc 7c 7e c4 9c ad 86
64 aa dc 29 f2 8d d9 56 7f 31 b6 bd 1b fd b8 ee
51 0d 3c 84 59 a2 45 d2 13 59 2a 14 82 1a 0f 6e
d3 d1 4a 2d a9 4c 7e db 90 07 fc f1 8d a3 8e 38
25 21 0a 32 c1 95 31 3c ba 56 cc 17 45 87 e1 eb
fd 9f 0f 82 16 67 9f 67 fa 91 e4 0d 55 4e 52 c0
66 64 2f fe 98 8f ae f8 96 21 5e ea 38 9e 5c 4f
27 e2 48 ca ca f2 90 23 ad 99 4b cc 38 32 6d bf
Or the same as the above, with ':' instead of spaces. We can't guarantee that these are the only ways such tools will present hexadecimals, so we are very lax.
The letters can be uppercase or lowercase, or mixed. Some strings may start with initial 00's, and can be stripped in this notation as they often are. Doing this could in complement of 2 notation could turn a positive number into a negative one, if the first character after applying the transformation described below, then happens to be one of the set {'8', '9', 'a', 'A', 'b', 'B', 'c', 'C', 'd', 'D', 'e', 'E', 'f', 'F'} . But as we interpret this string as a hexadecimal number leading 00s are not important (Complement of 2 notation and hexadecimal overlap for positive numbers)
In order to make this fun, we allow any unicode characters in the string.
A parser should
1. remove all non hexadecimal characters
2. treat the resulting as a hexadecimal representation of a number
This will allow people to make an ascii - better yet a UTF-8 - picture of their
public key when publishing it on the web.
"""@en;
rdfs:seeAlso <http://en.wikipedia.org/wiki/Hexadecimal>;
rdfs:domain xsd:nonNegativeInteger;
rdfs:range xsd:string;
vs:term_status "unstable" .
2. Example interpretation
-------------------------
So if I take the triple
ex:o ex:dollarValue _:v .
_:v cert:hex "BA:BA" .
which can be written as
ex:o ex:dollarValue "BA:BA"^cert:hex .
This is equivalent to the relation to the literal
ex:o ex:dollarValue "BA:BA"^^cert:hex .
so here in addition to the RDF, RDFS and OWL vocabularies we have
V = { "http://www.w3.org/ns/auth/cert#hex", "ex:o", "0", ...,"AB:AB",
"BA:BA"^^cert:hex, ex:dollarValue, "_:v" }
and an Interpretation I
IR = { cert:hex, ex:o } U xsd:nonNegativeIntegers U IR(rdf) U IR(rdfs) U IR(owl)
IP = { cert:hex, ex:dollarValue } U IP(rdf) U IP(rdfs) U IP(owl)
IEXT : { cert:hex => { <0 "0" > <1 "1"> ....
<47802 "AB:AB"> <47802 "AB AB"> <47802 "AB|AB">
...}
ex:dollarValue => { <ex:o 47802> }
U IEXT(rdf) U IEXT(rdfs) U IEXT(owl)
IS : { "ex:o" => <ex:o>
"http://www.w3.org/ns/auth/cert#hex" => cert:hex
} U IS(rdf) U IS(rdfs) U IS(owl)
IL : { "0"^^xsd:hex => 0
"1"^^xsd:hex => 1
"2"^^xsd:hex => 2
...
"AB:AB"^^cert:hex => 47802
"AB AB"^^cert:hex => 47802
... } U IL(rdf) U IL(rdfs) U IL(owl)
LV = LV(rdf)
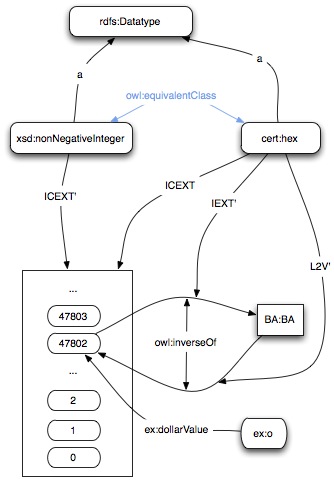
Using this interpretation, which is very general, we can see that the following graph makes both of them true
[ Here IEXT' is the relation from an object directly to an instance relation,
which is easier to draw, than drawing the line to the set of ordered pairs
The same with L2V' . ]
3. Proving Satisfaction
------------------------
Take the graph G composed of the triple
ex:o ex:dollarValue "BA:BA"^^cert:hex .
That is a ground triple, so it is true if as specified in section 1.4
http://www.w3.org/TR/rdf-mt/#gddenot
+ "ex:o", "ex:dollarValue", "BA:BA"^^cert:hex are in V
+ I(ex:dollarValue) is in IP
+ <I("ex:o") I("BA:BA"^^cert:hex)>
= < ex:o, IL("BA:BA"^^cert:hex)>
= < ex:o, 47802 >
which is indeed (amazing!) in IEXT(I("ex:dollarValue"))
Similarly if we now take the graph G2 composed of the two triples
G2 = {
t1 = { ex:o ex:dollarValue _:v .}
t2 = { _:v cert:hex "BA:BA" . }
}
I(G2) = true if [I+A](G2) for some mapping from blank(G2) to IR.
So we will cleverly select a mapping A such that
A("_:v") = 47802
And now the above graph is true if there is no triple T in G2 such that I(T) = false .
Luckily for the readers of this there are only two triples, so we proceed one by one
t1= { ex:o ex:dollarValue _:v .}
+ "ex:o" "ex:dollarValue" "_:v" are in V
+ I(ex:dollarValue) is in IP -- as above
+ <I+A("ex:o") I+A("_:v")>
= <ex:o A("_:v")>
= <ex:o 47802>
which is indeed (amazing!) in IEXT(I+A("ex:dollarValue")) = IEXT(I("ex:dollarValue"))
t2 = { _:v cert:hex "BA:BA" . }
+ "_:v" "http://www.w3.org/ns/auth/cert#hex" "BA:BA" are in V
+ I(cert:hex) is in IP
+ <I+A("_:v") I+A("BA:BA")>
= <A("_:v") I("BA:BA")>
= <47802 "BA:BA">
which is in IEXT(I+A("cert:hex"))
So both not of those are false so the graph G2 is true.
cert:hex Datatype GENERALISATION
================================
Let's look at the cert:hex datatype in more detail following section 5
http://www.w3.org/TR/rdf-mt/#dtype_interp
[[
Formally, a datatype d is defined by three items:
1. a non-empty set of character strings called the lexical space of d;
2. a non-empty set called the value space of d;
3. a mapping from the lexical space of d to the value space of d, called the lexical-to-value mapping of d.
The lexical-to-value mapping of a datatype d is written as L2V(d).
]]
Take the conditions one by one.
In our case
1. is the set of all unicode strings
2. the value space are all the positive integers including 0
3. and the lexical to value maping is explained in the definition of cert:hex
L2V(cert:hex)("AB AB") = 47802
L2V(cert:hex)("AB:AB") = 47802
L2V(cert:hex)(" 0") = 0
L2V(cert:hex)("♡AB♥AB♡") = 47802
now L2V is functional relation. So it has an inverse relation, that will be inverse functional. That is what IEXT(cert:hex) is. So let us define the INV function that maps a set of ordered pairs to its inverse, namely for every ordered pair <xxx yyy> in the origin set there will correspond one to one an ordered pair <yyy xxx> in the resulting set.
It is clear that the relation
INV(L2V(cert:hex)) = IEXT(cert:hex)
and vice versa.
As this can be generalised to all datatypes, I suggest that in the next revision of the RDF Semantics this is added.
PRAGMATIC REASONS FOR DOING SO
==============================
Now what is the value of doing so?
In a previous mail to this thread Pat Hayes argued very convincingly that the reason one URI refers in different ways to different things, is to reduce the need to create many URIs for each different thing.
http://lists.w3.org/Archives/Public/semantic-web/2010Feb/0193.html
So this is exactly the same reason why datatypes should be associated not just as they are now
- with the set of objects when used in object position
- with the L2V function when in the position of a datatype
But also
- with the INV(L2V(ddd)) when in a predicate position
Helping show how predicates and datatypes are related makes it much easier in my opinion to understand datatypes. There is nothing that magical about them.
It is very useful to have both pragmatically. So for example if as we have now we only had relations then we would have to write
<html xmlns="http://www.w3.org/1999/xhtml" lang="en" xml:lang="en">
<body>
<ul xmlns:cert="http://www.w3.org/ns/auth/cert#"
xmlns:rsa="http://www.w3.org/ns/auth/rsa#" >
<li rel="rsa:modulus">
<pre property="cert:hex">
9dcfd6a5394da9312c703e02a25dc3508262d9310be76d43ddf75d3025a9
739b989b2e50f2a80961fe41e6fb26fb7ceedae0fe0e0c7c1921f20a3a63
45fe74e9</pre>
</li>
<li rel="cert:identity" href="#me">My certificate</li>
</ul>
</body>
</html>
but because we have datatypes we can also write much more succintly
<html xmlns="http://www.w3.org/1999/xhtml" lang="en" xml:lang="en">
<body>
<ul xmlns:cert="http://www.w3.org/ns/auth/cert#"
xmlns:rsa="http://www.w3.org/ns/auth/rsa#"
typeof="rsa:RSAPublicKey" >
<li property="rsa:modulus" datatype="cert:hex">
9dcfd6a5394da9312c703e02a25dc3508262d9310be76d43ddf75d3025a9
739b989b2e50f2a80961fe41e6fb26fb7ceedae0fe0e0c7c1921f20a3a63
45fe74e9</li>
<li rel="cert:identity" href="#me">My certificate</li>
</ul>
</body>
</html>
The second way of writing furthermore helps remove the danger of the literal
getting a language tag inherited from further up.
FURTHER THOUGHT
===============
One could associate every language tag, with a URL, and following the same procedure show
how a language tag is a relation, as well as whatever it is right now.
Sorry to go into such detail.
The RDF Semantics paper is really extreemly intersting merge of logic and graph theory.
Henry
On 22 Feb 2010, at 22:42, Jeremy Carroll wrote:
> Pat Hayes wrote:
>> Dan is absolutely correct. See below.
>>
>>>
>>> I don't think so. I'm pretty sure the 2004 specs are silent on the
>>> use of datatypes as properties. Both directions are consistent
>>> semantic extensions.
>>
>> Yes, you are right. So this semantic extension is perfectly legal, contrary to what I was claiming. <Sound of crows being eaten />
>>
>> Sigh. However, it seems utterly crazy to me to use the same URI to denote both a mapping (inside a typed literal) and its inverse mapping (as a property). If I had even thought that anyone would want do that, I would have urged that we made it illegal back when we were writing the specs. The only possible reason for it that I can see would be to set out to make things deliberately confusing.
>
> I find Henry's examples fairly compelling, and wouldn't want them to be illegal. Not something I would do myself, but certainly plausible.
>
> Jeremy
>
>
Attachments
- image/jpg attachment: cert_hex.jpg
Received on Friday, 5 March 2010 17:55:50 UTC