- From: Garret Wilson <garret@globalmentor.com>
- Date: Mon, 30 Jul 2007 12:05:12 -0700
- To: Bruce D'Arcus <bdarcus@gmail.com>
- CC: Danny Ayers <danny.ayers@gmail.com>, andy.seaborne@hp.com, bnowack@appmosphere.com, Harry Halpin <hhalpin@ibiblio.org>, Semantic Web <semantic-web@w3.org>
- Message-ID: <46AE3668.1090803@globalmentor.com>
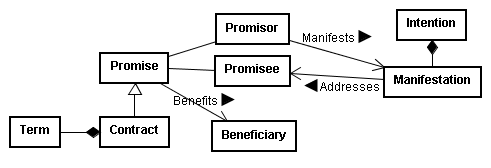
OK, this thread is freaking me out. Comments below: Bruce D'Arcus wrote: > > Just to remind people, Norm made what I consider to be the right > decision on names originally: restricting the cardinality of the name > parts to 1. That's pragmatic: simple to encode, to convert in and out > of the hCard microformat, and simple to query. It's exactly the kind > of thing that the RDF world needs to be doing more of. But think of what you're saying! You're saying that Norm restricted the cardinality of names to 1, not because that is what most closely models the semantics of a name, but because it seems nigh impossible to practically model lists of things in RDF! Does that not make you want to cry? I see people on this thread trying to query the most up-to-date recommendations for lists in RDF, and it looks like some of the code I see on http://worsethanfailure.com/ trying to add case statements for all the possible list sizes! Is that the state of RDF? Do you realize how many things in the world use sequences of things where order is important? Are you saying that, for every one of them, we must create ontologies without list-like things, just because that's "pragmatic" in RDF? JSON is a very simple programming-language-centric modeling language. It models values, including arrays and associative arrays, with no problem. It's simple to use. But we want to semantically model the world, and JSON isn't up to the task. The problem is that (based upon this thread) RDF apparently isn't up to the task either. It is too heavy to be used for simple data marshaling, and it's too anemic to be used for modeling the real world. > > As Tim said in response to Garret's suggestion that names are > brain-dead simple, they are not; they're really complicated in a lot > of cases! To believe that breaking it all apart and preserving order > is some kind of magic bullet it misguided. The point of my message was that, *relatively*, compared to the things that RDF says it wants to model in the real world, names are very, very, very simple. What's a common thing we might want to model in the real world using RDF? How about a legal contract? I've attached an image of a UML diagram I made of a contract in the USA as described by the Restatement of Contracts. This is a simplified version. What if we have multiple Promisees? What if the order in which the Promisees were made party to the contract is important? What about multiple Beneficiaries? What if some Beneficiaries only get the benefit of the contract if other Beneficiaries aren't available? What about multiple promises? Are you going to just model all these things with cardinality of 1, just because that's more "pragmatic"? In fact, the description of a contract in the Restatements are a simplified version of all the common law court cases over hundreds of years. Many legal concepts are more complicated, and many depend on defining contracts (and many contracts in turn depend on defining names). So yes, compared to contracts, names are "brain-dead simple" (although I never used that term). And contracts are "brain-dead simple" compared to many other legal concepts. > > If you have a relational database, how sensible is it really to have a > separate table for name parts, where each and every token is a > separate row? You're conflating the physical storage of a data model with its logical representation. I don't care how you store my name---maybe you put it all in one field using RDF/XML. That should not drive how I model the name in my modeling framework of choice (which is currently RDF, although it seems less useful every day). > > So I think WRT to where to go now, I really think we need to keep the > original notion that Norm had: singular namepart properties with a > cardinality of 1. > > If we need to make the painful decision to add duplicate plural name > part properties, so be it. I dislike the idea regardless of whether we > use Seq or List, but I don' think what I hope will be a short-term > limitation in SPARQL will be the final decider. Why don't we just model names in the syntax given by RFC 2426? Isn't RDF just bringing us a lot of trouble? Isn't the most pragmatic thing to do is to keep using RFC 2426? Garret
Attachments
- image/png attachment: contract_class_diagram.png
Received on Monday, 30 July 2007 19:05:24 UTC