- From: Dimitre Novatchev <dnovatchev@gmail.com>
- Date: Thu, 14 Mar 2024 17:01:40 -0700
- To: Christian Grün <cg@basex.org>
- Cc: Norm Tovey-Walsh <norm@saxonica.com>, "public-xslt-40@w3.org" <public-xslt-40@w3.org>
- Message-ID: <CAK4KnZeHV5FQc2UnXq_wuyQ4a0QZ5ZwfzXW-2eYJJQafV4nPmw@mail.gmail.com>
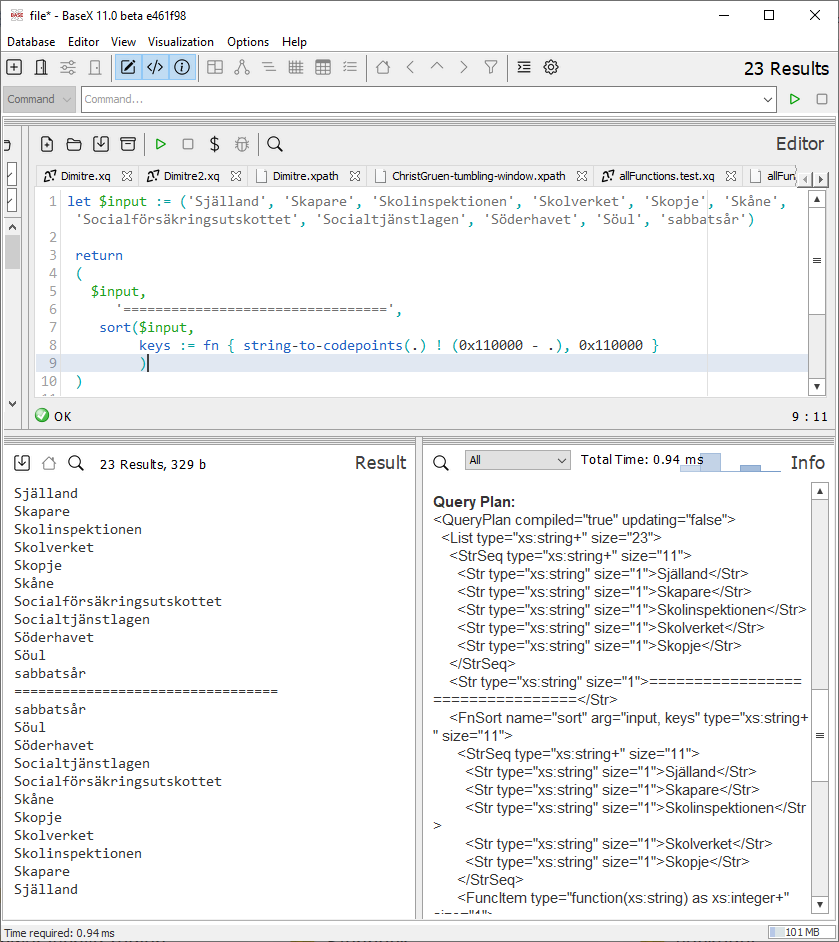
Seems to work like a charm 😀
I took 11 Swedish words in their sorted order from an online Swedish
dictionary (https://en.bab.la/dictionary/swedish-english/s/1) and applied
the sorting expression.
The result is: all the words in the opposite order -- really sweet.
[image: image.png]
Thanks,
Dimitre
On Thu, Mar 14, 2024 at 11:50 AM Dimitre Novatchev <dnovatchev@gmail.com>
wrote:
> > I see; so in a nutshell it’s this?
> >
> > sort(
> > $input,
> > keys := fn { string-to-codepoints(.) ! (0x110000 - .), 0x110000 }
> > )
>
> Essentially yes. This would work for a binary collation that for each
> contained codepoint cp, also contains the codepoint 0x110000 - cp.
>
> The way to make this work with any collation is not to do the subtraction,
> but to swap every pair of codepoints that are equally away from the median
> of the collation. Thus, take step1 below with this note in mind.
>
> 0x10FFFF is the biggest code for a Unicode 6. 0 character (
> https://unicodebook.readthedocs.io/unicode_encodings.html#utf-8)
>
> Add to it one, and we get the value of 0x110000.
>
> 1. Subtract each character in the string from this value and get a new
> string.
>
> 2. Append this same value at the end of the so produced string.
>
> One could ask "Why should we add a new symbol? (code-point) ?"
>
> Probably for the same reason as to why we are using the empty string ""
> which contains absolutely no codepoints in it... (0 codepoints) That is -
> for convenience and completeness.
>
> Thanks,
> Dimitre
>
> On Thu, Mar 14, 2024 at 10:29 AM Christian Grün <cg@basex.org> wrote:
>
>> I see; so in a nutshell it’s this?
>>
>> sort(
>> $input,
>> keys := fn { string-to-codepoints(.) ! (0x110000 - .), 0x110000 }
>> )
>> _________________________________
>>
>> Excellent question.
>>
>> And yes, I gave an improper mapping, the correct one is:
>>
>>
>>
>> "" : '$' ,
>> S1 : Sn ,
>> S2 : Sn-1 ,
>> . . . . . . .
>> Sk : Sn-k+1 ',
>> . . . . . . .
>>
>> Sn : S1
>>
>> and very importantly, Every mapped string must be appended by the '$'
>> character. Just one ending '$' character.
>>
>> In this way we will have:
>>
>> Z => "A"||"$",
>> ZZ => "AA"||"$"
>>
>> "A$" > "AA$" because $ is the biggest symbol and is > "A"
>>
>> Thus "AA$" (the value of the inversion of "ZZ") must be returned before
>> "A$" (the value of the inversion of "Z")
>>
>>
>> Thanks,
>> Dimitre
>>
>>
>>
>> Am 14.03.2024 17:06 schrieb Dimitre Novatchev <dnovatchev@gmail.com
>> <mailto:dnovatchev@gmail.com>>:
>> > > For a simplified example, revert("abc") would produce "zyx" .
>> This is doable and really valuable.
>> >
>> > In what sense is “zyx” the complement of “abc”? Over what set of
>> codepoints and in what collation?
>> >
>> > I am very skeptical that such a function is well defined across
>> all collations and will always produce a single, correct result in all
>> cases.
>> >
>> > Can you provide a detailed description of how this would work?
>>
>> Yes, as Michael Kay already explained, this is doable if either: the
>> "biggest" symbol in the collation is not used (which btw happens in some
>> collations, for example the biggest symbol in the English(American)
>> collation is 0xFE) - or add an additional symbol that is "bigger" than any
>> other symbol in the collation.
>>
>> Let us, just for convenience, refer to this special symbol as '$' (this
>> is just a convention on how to refer to this special symbol, not the actual
>> dollar character).
>>
>> Then, if S1, S2, ..., Sn are all n symbols in the collation ordered by
>> their value in the collation, perform this mapping:
>>
>> "" : '$' ,
>> S1 : Sn || '$' ,
>> S2 : Sn-1 || '$' ,
>> . . . . . . .
>> Sk : Sn-k+1 || '$',
>> . . . . . . .
>>
>> Sn : S1 || '$'
>>
>> And certainly, adding a new symbol to a collation is actually creating a
>> new collation, and this would maybe be the most straight-forward way of
>> inverting strings.
>>
>> We may not even create any new collation, we could just have a convention
>> that a collation named "Inverted" || {Real-Collation-Name} produces the
>> negated comparison results of the ones produced by the
>> {Real-Collation-Name} collation. Or, as I mentioned before, this is the
>> same as "decorating a collation".
>>
>> This is one more way to get rid of the $orders parameter in our current
>> functions.
>>
>> Thanks,
>> Dimitre
>>
>> On Thu, Mar 14, 2024 at 3:24 AM Norm Tovey-Walsh <norm@saxonica.com
>> <mailto:norm@saxonica.com>> wrote:
>> Dimitre Novatchev <dnovatchev@gmail.com<mailto:dnovatchev@gmail.com>>
>> writes:
>> > This function can easily handle strings - produce a "string
>> complement" in the value space for a particular collation.
>> >
>> > For a simplified example, revert("abc") would produce "zyx" . This
>> is doable and really valuable.
>>
>> In what sense is “zyx” the complement of “abc”? Over what set of
>> codepoints and in what collation?
>>
>> I am very skeptical that such a function is well defined across all
>> collations and will always produce a single, correct result in all cases.
>>
>> Can you provide a detailed description of how this would work?
>>
>> Be seeing you,
>> norm
>>
>> --
>> Norm Tovey-Walsh
>> Saxonica
>>
>>
>>
>>
>>
>>
>
>
Attachments
- image/png attachment: image.png
Received on Friday, 15 March 2024 00:01:57 UTC