- From: Alex Milowski <alex@milowski.org>
- Date: Mon, 24 Apr 2006 14:32:03 -0700
- To: public-xml-processing-model-wg@w3.org
- Message-ID: <444D43D3.1090305@milowski.org>
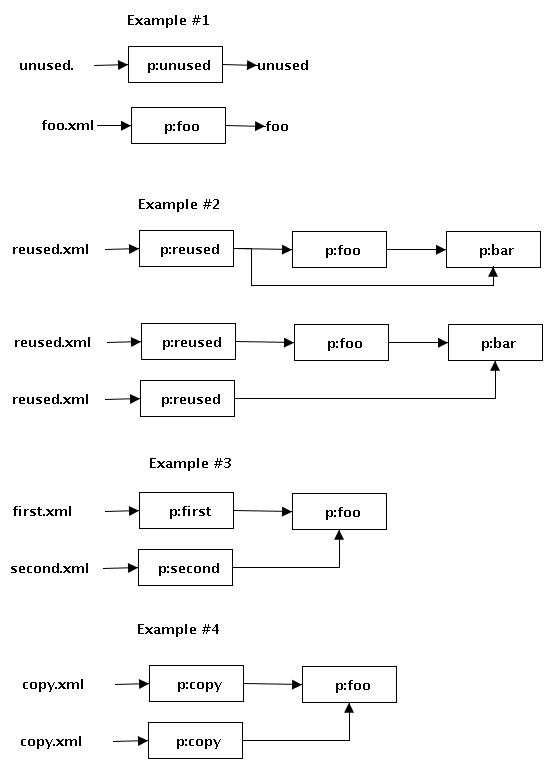
I've put the first four examples into flow graphs for discussion purposes. Jeni Tennison wrote: > > Hi, > > Trying to put my thoughts into order... Given that we annotate > components/steps to indicate what optimisations a pipeine engine can do, > what are those annotations going to be and what do they permit the > pipeline engine to do? > > To summarise: I think we need to provide annotations at both the > component level and the step level, indicating whether the > component/step has side-effects or not, and how stable it is. We also > need to be clear about what extra environment information is passed to > each component. > > First, let's consider some possible optimisations that a pipeline engine > might want to do: > > 1. Omit the step if its outputs aren't used. For example, p:unused in > this pipeline: > > <p:pipeline> > <p:output ref="foo" /> > <p:step name="p:unused"> > <p:input href="unused.xml" /> > <p:output label="unused" /> > </p:step> > <p:step name="p:foo"> > <p:input href="foo.xml" /> > <p:output label="foo" /> > </p:step> > </p:pipeline> I wouldn't call this an optimization. Maybe you are suppose to run both. Maybe I the "unused" step does something but the output isn't important. > 2. Run the step multiple times. For example, p:reused in this pipeline: > > <p:pipeline> > <p:output ref="bar" /> > <p:step name="p:reused"> > <p:input href="reused.xml" /> > <p:output label="reused" /> > </p:step> > <p:step name="p:foo"> > <p:input ref="reused" /> > <p:output label="foo" /> > </p:step> > <p:step name="p:bar"> > <p:input name="doc1" ref="reused" /> > <p:input name="doc2" ref="foo" /> > <p:output label="bar" /> > </p:step> > </p:pipeline> There are two distinct choices here in terms of the flow graph. I would expect our concrete language to make these very different flow graphs clear. > > 3. Reorder the steps in the pipeline, e.g. parallel execution. For > example, running p:second before, or at the same time as, p:first in > this pipeline: > > <p:pipeline> > <p:output ref="foo" /> > <p:step name="p:first"> > <p:input href="first.xml" /> > <p:output label="first" /> > </p:step> > <p:step name="p:second"> > <p:input href="second.xml" /> > <p:output label="second" /> > </p:step> > <p:step name="p:foo"> > <p:input name="doc1" ref="first" /> > <p:input name="doc2" ref="second" /> > <p:output label="foo" /> > </p:step> > </p:pipeline> Yes, this should be allowed. > > 4. Use cached results of the component invoked in the same way in the > same pipeline invocation. For example, using 'copy1' rather than 'copy2' > in the p:foo step in this pipeline: > > <p:pipeline> > <p:output ref="foo" /> > <p:step name="p:copy"> > <p:input href="copy.xml" /> > <p:output label="copy1" /> > </p:step> > <p:step name="p:copy"> > <p:input href="copy.xml" /> > <p:output label="copy2" /> > </p:step> > <p:step name="p:foo"> > <p:input name="doc1" ref="copy1" /> > <p:input name="doc2" ref="copy2" /> > <p:output label="foo" /> > </p:step> > </p:pipeline> I don't see how this is different than #3. The graphs are exactly the same. > > 3. Use cached results of the component invoked in the same way in a > different pipeline invocation. For example, cache the 'foo' document in > this pipeline and reuse it the next time the pipeline is invoked, > assuming that foo.xml hasn't changed in the meantime: > > <p:pipeline> > <p:output ref="foo" /> > <p:step name="p:foo"> > <p:input href="foo.xml" /> > <p:output label="foo" /> > </p:step> > </p:pipeline> I see this as environment specific. Many web-server technologies (e.g. Cocoon, struts, etc.) cache calculated results. I'm not sure we need to go there... but implementors certainly will want to do something about that. > I think there are two things that effect which of these optimisations > can be carried out: > > A. Whether the step has side effects: it does something other than > generating the outputs defined for the step. Updating a database is > an example. This might be a simple way to distinguish which version of #2 is used. <snip/> > > If a step has side-effects then it must be run exactly once. Steps > without side-effects can be omitted or run several times, though if an > unstable step is run multiple times then all but the first invocation > must be ignored, as the result might be different each time. Maybe I want a step with a side-effect to run more than once--maybe every time. We can't dictate which way is correct--just that you have control to choose. > The outputs of stable steps can be cached and reused. As long as it's > stable, the outputs of a step with side effects are still cachable: the > pipeline engine has to run the step anyway, and can't get on with other > steps until it's finished, but could possibly glean some performance > benefit from reusing outputs if it meant it didn't have to re-parse a > large XML document, for example. An example of a stable step with side > effects is one that takes an XML document, updates a database with the > data it contains, and returns the same XML document as the result. An alternative here is that if you want an output to be re-used (e.g. cached), you can create and output/input dependency. In example #2, the first flow graph I wrote down re-uses the output of the "p:reused" step. In the second flow graph, a completely different invocation of the step is used. -- --Alex Milowski
Attachments
- image/png attachment: jeni-1.png
Received on Monday, 24 April 2006 21:32:16 UTC