- From: Ian Wilson <ian@emotionai.com>
- Date: Mon, 02 Jun 2008 07:10:57 -0500
- To: Marc Schroeder <schroed@dfki.de>
- Cc: public-xg-emotion@w3.org
- Message-Id: <27073.1212408657@orgoo.com>
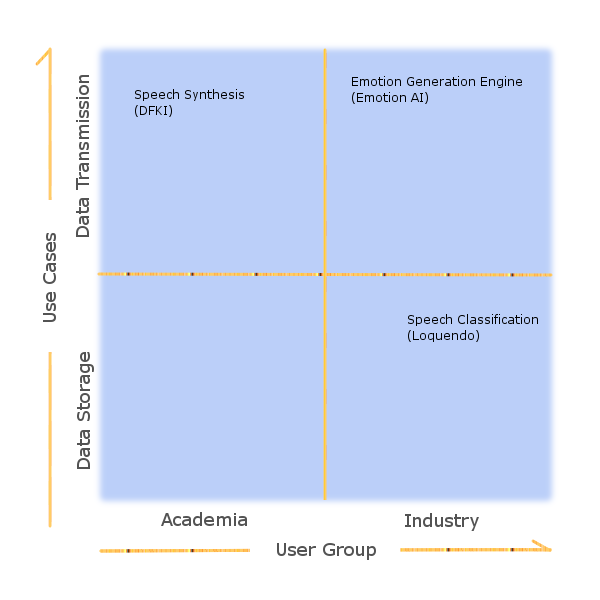
Marc, Here is my first draft for the sections on Usage Issues. I would like to make a diagram if it will fit of the use cases and have attached an example here with some of the cases I know and where they fit, however I would need help assigning all of the use cases: Target Audience The participants in our working group represent a broad cross section of users and as such are in themselves a reasonable reflection of our standards potential user base. These user groups come under two general categories, industry and academia and their potential products, services and research can broadly be defined as emotion annotation, emotion recognition and emotion generation, as we have previously defined in our representative use cases. We can further separate the use cases into two groups, data storage (annotation) and data transmission (recognition and generation). This is a wide spectrum of potential uses and it is a challenge for the group to define a standard that is flexible enough to be suitable for the requirements of each user group and functional task. While academia and industry can and should share standards, users who require a data storage standard and those who require a data transmission standard may have quite different requirements. Looking at potential uses of this standard from the perspective of our previously defined use cases we can view them within the framework of a "quadrant" diagram. (see attached image) Figure 1. Example Target Audience Quadrant (from working group use cases document) Future Proofing While working from a well defined set of use cases has allowed us to better understand the requirements of potential users and form constraints that define how far we expect the standard to stretch we also want the standard to have enough flexibility to be able to accommodate future uses that we have not currently envisioned. To this end, one of our guiding principles has been to define only a core standard but allow and encourage the core to be extended by the use of custom libraries that can be imported. Current standard work is focused on appraising the different methods to achieve this and which format (for example XML, RDF, OWL) is most appropriate, given our requirements. We aim to produce, within the core specification, a set of default data "types", which may be categories, labels, scales and dimensions appropriate to the transmission and storage of emotion data that will serve many, perhaps non specialist, users needs. These can, however, be replaced or "overloaded" by the users own defined set, for example their own labels for emotion events, actions, gestures or behaviors. This extesibility should give the standard a longer life span and avoid rapid obsolescence. Interoperability Another centrally important objective of the standard is to enable or facilitate interoperability between systems that process and/or store emotional data in the same way that HTML allows web page data to be displayed in any number of standard display systems in an interoperable manner. However, this standard is more complex that simple HTML and faces a number of challenges. Its main challenge is that within the area of emotion research there are currently no agreed and accepted standards for concepts such as categories, labels, dimensions and scales. To enable interoperability it will be necessary for us to define a mechanism that can either translate between different formats or enforce a set of core data types within the standard (for example all values are real numbers between 0 and 1) and then allow users to translate from this to their own preferred formats. In this way any transmission of data is guaranteed to be in a standard format and so the recipient need not worry or know about the senders internally used format. This may be a crucial requirement for interoperability. Best, Ian ------- Sent from Orgoo.com - Your communications cockpit!
Attachments
- image/png attachment: emoxgQuadrant.png
Received on Monday, 2 June 2008 12:11:42 UTC