- From: Garret Rieger <grieger@google.com>
- Date: Thu, 8 Jun 2023 15:06:43 -0600
- To: Skef Iterum <siterum@adobe.com>
- Cc: "public-webfonts-wg@w3.org" <public-webfonts-wg@w3.org>
- Message-ID: <CAM=OCWbhLc1aXOcJXORakn+dHLeE5UWDNXxxf3+2LhiFipQAcA@mail.gmail.com>
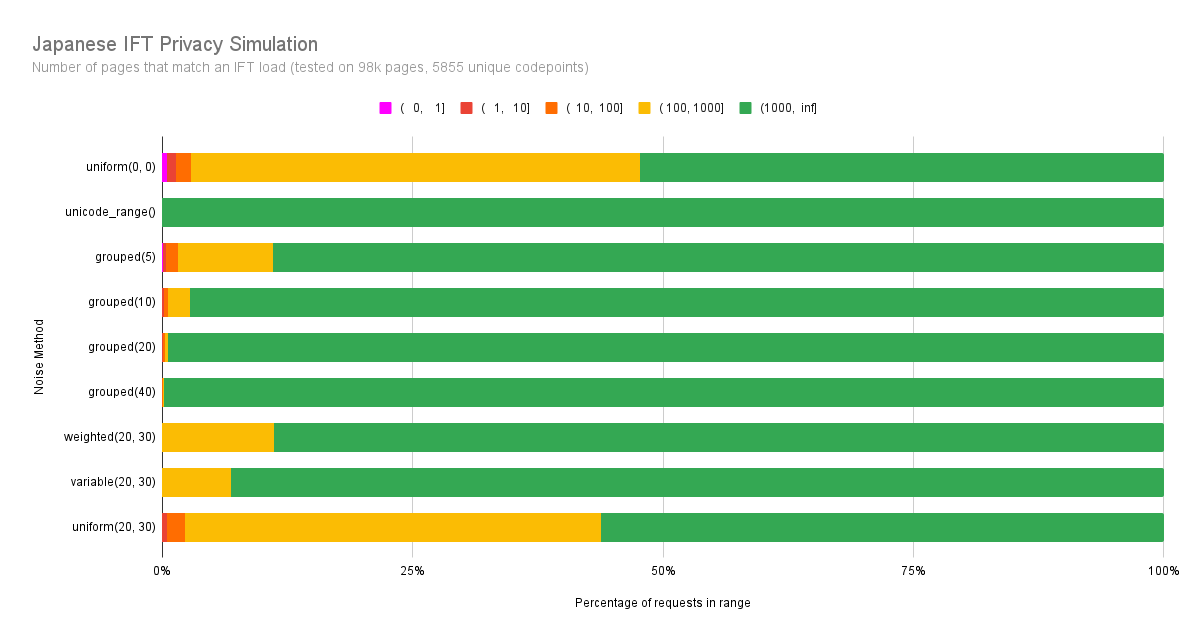
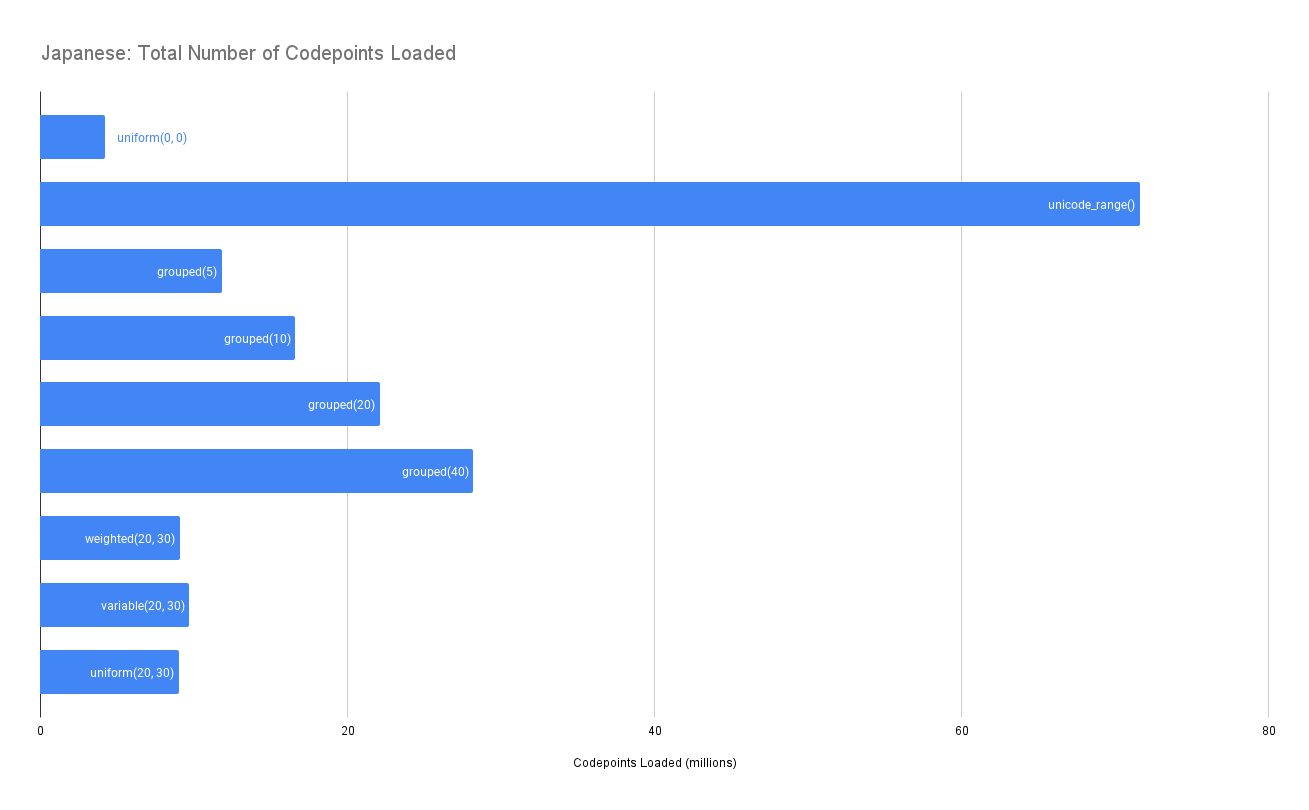
Updated the simulations with a grouping noise method. It puts all of the candidate codepoints into groups of a fixed size based on their frequency. All groups that intersect the original request are added to the request. Here's the results for Japanese: [image: Japanese IFT Privacy Simulation.png] [image: Japanese_ Total Number of Codepoints Loaded.png] This shows that using grouping we can attain similar levels of privacy as the variable frequency weighted noise with group sizes between 5-10 codepoints. This does cost a bit more extra codepoints transferred than the noise approach, but is still reasonable. I'm going to also play around with varying the group size based on the frequency of the codepoints in the group (ie. bigger groups for less frequent codepoints) and see how that affects the results. On Wed, Jun 7, 2023 at 6:44 PM Garret Rieger <grieger@google.com> wrote: > I should note that unicode range which I simulated is essentially > equivalent to this using group sizes of ~100 and that performed very well > in the simulations for number of matches. So I'm optimistic that we should > be able to find a smaller group size which performs good, while providing a > much lower overall number of codepoints transferred then the larger unicode > range groups. > > On Wed, Jun 7, 2023 at 6:41 PM Garret Rieger <grieger@google.com> wrote: > >> Agreed that using deterministic noise (seeded from the content) is not >> viable for the reasons you mentioned. >> >> I like the idea of including groups of codepoints together. The >> specification actually had a mechanism for this in the very early days, >> where the code point mapping provided a list of codepoint groups that could >> be requested. This was primarily intended as a performance optimization to >> reduce the size of the codepoint sets that needed to be transmitted in the >> request. Eventually it was dropped once other techniques gave good enough >> compression of the sets. Given that it's potentially useful from the >> privacy side of things we may want to bring it back. >> >> I'll update my noise simulations to also simulate codepoint grouping and >> see how that fairs. If it looks good then it might be a good solution to >> the privacy problem that also works with caching. >> >> On Tue, Jun 6, 2023 at 10:46 PM Skef Iterum <siterum@adobe.com> wrote: >> >>> I've been thinking about this morning's privacy/caching problem a bit >>> while staring off into the middle distance. >>> >>> Ultimately, I don't think seeding the randomization with some aspect of >>> the document (perhaps a checksum of the whole document, perhaps some >>> mapping from the specific set of codepoints and features) is a productive >>> way forward. If you have a randomization that is determined by the document >>> you can construct a mapping from documents you want to "spy on" to their >>> respective noised sets and check server logs against it. >>> >>> Now, one thought this brings up is that the possibility of such a >>> mapping isn't a problem as long as there are enough documents that share >>> it. That seems right but I think it may also show that the randomization >>> itself isn't central to the design, and may actually work against it a >>> little. >>> >>> Our problem is that some of the codepoints in the document may be >>> distinctive, especially in combination with the rest, and we don't want the >>> server to know about that combination. So we throw some other codepoints >>> (some of which may be distinctive) that aren't in the document into the >>> set. Now the server can't tell which were actually in the document and >>> which are ringers, and therefore this is a wider set of documents that >>> could map to that combination. That's what the graphs in Garret's >>> presentations are constructed to show. >>> >>> Note that I didn't have to say anything about randomization to describe >>> that. Indeed, if you just put all codepoints into groups of four somewhat >>> analogous codepoints (so not random, but grouping >>> obscure-but-still-somewhat-likely-to-appear-in-the-same-document codepoints >>> together) and then always request all four when any one is needed, you'd >>> accomplish (some of) the same thing. (And you'd also make your generated >>> files a bit more cachable rather than less.) >>> >>> True random-seeded additional noise is a means to the same end, but >>> deterministic noise has too high a chance of some distinctive >>> characteristic for picking out the source document. So maybe the thing to >>> do is think about other means of getting the aliasing we want that aren't >>> noise-based. >>> >>> Skef >>> >>
Attachments
- image/png attachment: Japanese_IFT_Privacy_Simulation.png
- image/png attachment: Japanese__Total_Number_of_Codepoints_Loaded.png
Received on Thursday, 8 June 2023 21:07:07 UTC