- From: Garret Rieger <grieger@google.com>
- Date: Fri, 14 Oct 2022 15:36:12 -0600
- To: "w3c-webfonts-wg (public-webfonts-wg@w3.org)" <public-webfonts-wg@w3.org>
- Message-ID: <CAM=OCWaeeRV4arA1pkbESY1t9S6h0RgeJqt2kO7qX3cixAW9_w@mail.gmail.com>
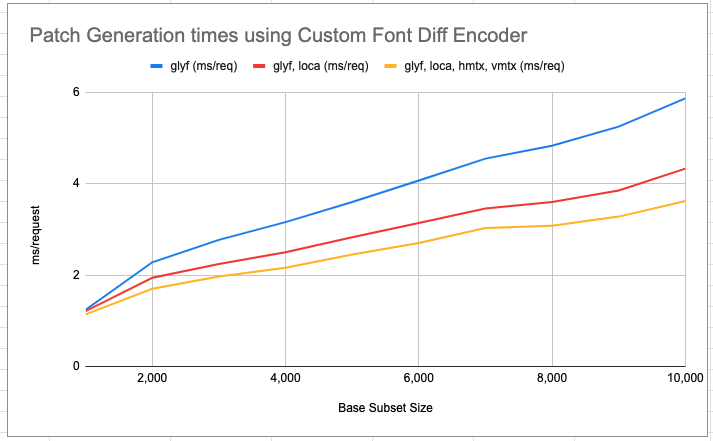
Over the past couple of weeks I've finished building out the early prototype of the custom font diff encoder into a more complete implementation: - It now supports producing custom diffs for glyf, loca, hmtx, and vmtx. For these tables unchanged ranges of data are determined by comparing the subset plans and corresponding backwards references are added to the brotli stream. - All other tables are compressed using the generic brotli encoder + a partial dictionary that includes data just from those tables from the base. As with before I've benchmarked the patch generation times acrossing a varying base size, the results are very good: [image: Screen Shot 2022-10-14 at 3.15.19 PM.png] For a patch against a 10,000 codepoint base it can generate that patch in *3.62 ms vs 132 ms* that the generic brotli encoder would take! The custom encoder produces patches that are a bit larger (1 to 13%) increase in size vs the generic encoder. The majority of the size increase appears to be due to less efficient encoding of the new portion of loca. Using the custom differ only on glyf results is only a 1% increase in patch size. The raw data from the benchmarks can be found here <https://docs.google.com/spreadsheets/d/1Xf2KY4sbR_mSXDRJdO7mKKEBPSEBPmjCYxeqhvLOe7c/edit#gid=1341899720> . Additionally I've started <https://github.com/harfbuzz/harfbuzz/pull/3842> to implement subset accelerators in harfbuzz. Accelerators are precomputed data which can be re-used to speed up future subsetting operations. The results are already very promising. I'm planning on presenting both of these results in more detail at next week's meeting.
Attachments
- image/png attachment: Screen_Shot_2022-10-14_at_3.15.19_PM.png
Received on Friday, 14 October 2022 21:36:42 UTC