- From: Leonard Rosenthol <lrosenth@adobe.com>
- Date: Tue, 19 Mar 2024 13:35:21 +0000
- To: Sarven Capadisli <info@csarven.ca>, "public-solid@w3.org" <public-solid@w3.org>
- Message-ID: <BL3PR02MB8186DA6AB43F8C4E97A7CD31CD2C2@BL3PR02MB8186.namprd02.prod.outlook.com>
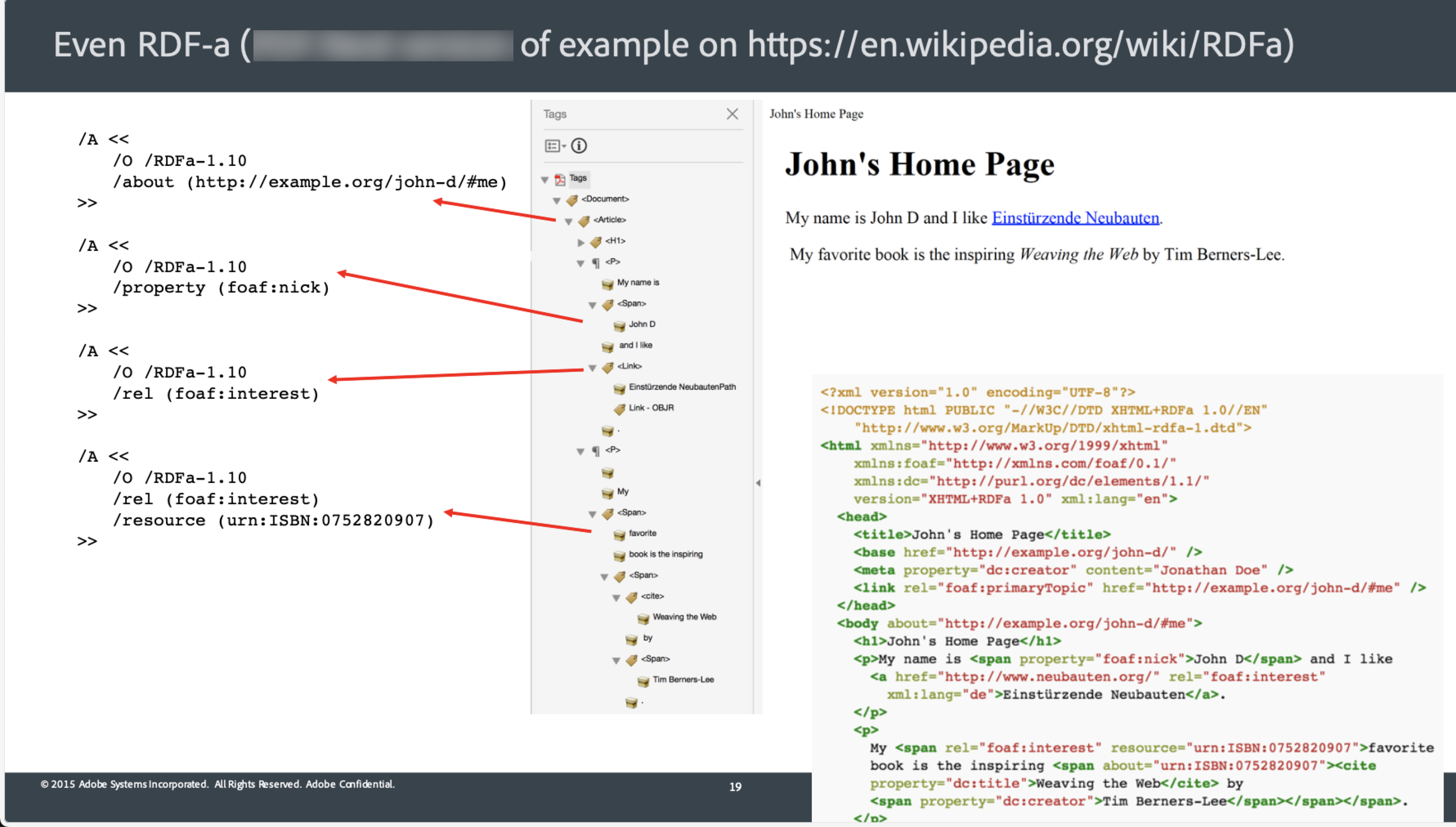
I wasn’t trying to say that PDF is better than your format – I was simply trying to make sure that no misinformation was spread. Nothing more. > I presume you're referring to extracting / mapping XMP > No, that is not what I am referring to at all. I am referring the feature of PDF called “Tagged PDF”, which has been part of the standard for 25 years. And don’t forget that PDF has been an ISO standard (ISO 32000) since 2008 and is a normative reference in the HTML5 specification (which is the basis for the “open web”). In PDF 2.0 (ISO 32000-2), we added support for RDFa as part of that. Here is a picture from a presentation that I give on the topic showing the tagging with RDFa semantics and the associated derived HTML. [A screenshot of a computer Description automatically generated] There are numerous open source tools & libraries that give you access to this information when present in a PDF, as well as tools for creating it in the first place. Even common publishing solutions such as Open/LibreOffice, various (La)TeX implementations and even commercial solutions also support creation of Tagged PDFs. Personally, I don’t think there is a “best solution for all cases of information sharing”. It is entirely dependent on whether the goal is to share information with humans, with machines or with both. It is also important to consider additional requirements such as longevity/stability of the information. And so folks should always choose what works best for them and their use cases. (and with that said, I think the Solid platform and its technologies bring some excellent pieces to the world – which is why I am here in this group!) Leonard From: Sarven Capadisli <info@csarven.ca> Date: Tuesday, March 19, 2024 at 9:08 AM To: public-solid@w3.org <public-solid@w3.org> Subject: My format can beat up your format (Was: Re: DeSeRe’24 Workshop on Decentralised search and Recommendations) EXTERNAL: Use caution when clicking on links or opening attachments. On 2024-03-19 12:36, Leonard Rosenthol wrote: > Sarven – I have no connection to this conference, but the general answer > to the question is that PDF is a semantically rich format which includes > full support for structural semantics, content semantics as well as RDFa > compatible “markup”. So given a properly constructed PDF, retrieval of > such information is well defined. In fact, there is an industry > standard for deterministically deriving equivalent HTML(+RDF, if > present) - https://nam04.safelinks.protection.outlook.com/?url=https%3A%2F%2Fpdfa.org%2Fresource%2Fderiving-html-from-pdf%2F&data=05%7C02%7Clrosenth%40adobe.com%7C15a7ee7196a4406aae3408dc4814a844%7Cfa7b1b5a7b34438794aed2c178decee1%7C0%7C0%7C638464505035449385%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C0%7C%7C%7C&sdata=cIjSJyFjUB42Zo98r1uZp7c3S0uXA92%2F42AOcaKdCYg%3D&reserved=0<https://pdfa.org/resource/deriving-html-from-pdf/> > <https://nam04.safelinks.protection.outlook.com/?url=https%3A%2F%2Fpdfa.org%2Fresource%2Fderiving-html-from-pdf%2F&data=05%7C02%7Clrosenth%40adobe.com%7C15a7ee7196a4406aae3408dc4814a844%7Cfa7b1b5a7b34438794aed2c178decee1%7C0%7C0%7C638464505035458452%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C0%7C%7C%7C&sdata=%2FvW9wyO4cmCx7YYKsz4GXCHTE32JjYFfwTJGO2zyDHk%3D&reserved=0<https://pdfa.org/resource/deriving-html-from-pdf/>>. Is the suggestion that when senders or receivers are equipped with the processing algorithm, they can extract the structured data - using the term liberally - inside the PDF? I presume you're referring to extracting / mapping XMP (specifically RDF/XML) in PDF to HTML(+RDF) as per https://nam04.safelinks.protection.outlook.com/?url=https%3A%2F%2Fpdfa.org%2Fresource%2Fiso-16684-xmp%2F&data=05%7C02%7Clrosenth%40adobe.com%7C15a7ee7196a4406aae3408dc4814a844%7Cfa7b1b5a7b34438794aed2c178decee1%7C0%7C0%7C638464505035464990%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C0%7C%7C%7C&sdata=z%2BiFRumHcO0bJlzIlwPPiVShZKTh3ujyB9Kquk%2B%2BMm8%3D&reserved=0<https://pdfa.org/resource/iso-16684-xmp/> , which is paywalled. Fortunately when I last researched this topic ( https://nam04.safelinks.protection.outlook.com/?url=https%3A%2F%2Fcsarven.ca%2Flinked-research-decentralised-web&data=05%7C02%7Clrosenth%40adobe.com%7C15a7ee7196a4406aae3408dc4814a844%7Cfa7b1b5a7b34438794aed2c178decee1%7C0%7C0%7C638464505035470120%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C0%7C%7C%7C&sdata=NvD1lYDpqWtNJZkgVLIuK4ZBW9uAEc5Uw7ZPV0iT0NM%3D&reserved=0<https://csarven.ca/linked-research-decentralised-web> ), I archived the then publicly available XMP specification: https://nam04.safelinks.protection.outlook.com/?url=https%3A%2F%2Fweb.archive.org%2Fweb%2F20190710075340%2Fhttps%3A%2F%2Fwwwimages2.adobe.com%2Fcontent%2Fdam%2Facom%2Fen%2Fdevnet%2Fxmp%2Fpdfs%2FXMP%2520SDK%2520Release%2520cc-2016-08%2FXMPSpecificationPart1.pdf&data=05%7C02%7Clrosenth%40adobe.com%7C15a7ee7196a4406aae3408dc4814a844%7Cfa7b1b5a7b34438794aed2c178decee1%7C0%7C0%7C638464505035474805%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C0%7C%7C%7C&sdata=5RpeUSo1zo0xs1GwR%2BouIpvbluArsaWxvO8Jv%2FsFdvA%3D&reserved=0<https://web.archive.org/web/20190710075340/https://wwwimages2.adobe.com/content/dam/acom/en/devnet/xmp/pdfs/XMP%20SDK%20Release%20cc-2016-08/XMPSpecificationPart1.pdf> IIRC, PDF/XMP required propriety tools to create and consume that are underdeveloped/undertooled. It is hidden/grey metadata. The RDF within XMP can only have one unique subject (of triple) that is not even intended to identify the document itself. The RDF in XMP is essentially a (broken) subset of RDF/XML. That said, if there are alternative formats/models that deriving-html-from-pdf follows, can you please refer me to a specification? While I don't refute that some things are possible with PDF and it has done well (thinking mostly print-centric, among other things), having it actually play well with/in the open web platform requires reverse-engineering the flows/formats/data, in a nutshell. (I'd be happy to be corrected on how well PDFs work with respect to read-write HTTP operations, deep linking, and so forth.) PDF/XMP's intricate complexity doesn't align with the rule of least power design principle ( https://nam04.safelinks.protection.outlook.com/?url=https%3A%2F%2Fwww.w3.org%2FDesignIssues%2FPrinciples%23PLP&data=05%7C02%7Clrosenth%40adobe.com%7C15a7ee7196a4406aae3408dc4814a844%7Cfa7b1b5a7b34438794aed2c178decee1%7C0%7C0%7C638464505035480090%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C0%7C%7C%7C&sdata=ezROZLjFz85nlVCscQJy5KR3xKEjTdzMiAZyWV7gdiw%3D&reserved=0<https://www.w3.org/DesignIssues/Principles#PLP> , https://nam04.safelinks.protection.outlook.com/?url=https%3A%2F%2Fwww.w3.org%2F2001%2Ftag%2Fdoc%2FleastPower.html&data=05%7C02%7Clrosenth%40adobe.com%7C15a7ee7196a4406aae3408dc4814a844%7Cfa7b1b5a7b34438794aed2c178decee1%7C0%7C0%7C638464505035484429%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C0%7C%7C%7C&sdata=mLK9exjsOGOKIk8B6bMvRre6flFPh%2FFYFW6%2B1dx8cdg%3D&reserved=0<https://www.w3.org/2001/tag/doc/leastPower.html> , https://nam04.safelinks.protection.outlook.com/?url=https%3A%2F%2Fen.wikipedia.org%2Fwiki%2FRule_of_least_power&data=05%7C02%7Clrosenth%40adobe.com%7C15a7ee7196a4406aae3408dc4814a844%7Cfa7b1b5a7b34438794aed2c178decee1%7C0%7C0%7C638464505035488590%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C0%7C%7C%7C&sdata=SqA3Z3%2BuDfHtwIu8KYdov9Yd0LpKZzfPWSO06cNBOR0%3D&reserved=0<https://en.wikipedia.org/wiki/Rule_of_least_power> . FWIW. I don't see a compelling reason to package knowledge in PDF and share it on the web, especially when there are *open* *industry standards* that literally work better in about every way for knowledge sharing (and interactivity)... on the web. Others' mileage may vary. -Sarven https://nam04.safelinks.protection.outlook.com/?url=https%3A%2F%2Fcsarven.ca%2F%23i&data=05%7C02%7Clrosenth%40adobe.com%7C15a7ee7196a4406aae3408dc4814a844%7Cfa7b1b5a7b34438794aed2c178decee1%7C0%7C0%7C638464505035492693%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C0%7C%7C%7C&sdata=NjSLgQtsq4yUuYczKhJhL0FKiBmkcK44h%2FKvyUG7v%2Bs%3D&reserved=0<https://csarven.ca/#i>
Attachments
- image/png attachment: image001.png
Received on Tuesday, 19 March 2024 13:35:34 UTC