- From: Trautt, Zachary T. (Fed) <zachary.trautt@nist.gov>
- Date: Fri, 19 Feb 2021 20:13:23 +0000
- To: "smrtucson@gmail.com" <smrtucson@gmail.com>, 'Dan Brickley' <danbri@google.com>, 'Thad Guidry' <thadguidry@gmail.com>
- CC: 'schema.org Mailing List' <public-schemaorg@w3.org>
- Message-ID: <C820A9AA-99AA-4E55-8195-C93159D7927D@nist.gov>
I’m grateful for the dedication of the schema.org community and the growing impact of widespread adoption!
I am writing to agree with a statement made earlier in issue 2573 where an individual expressed that schema.org has grown too big for any one committee to manage. I think a voluntary subcommittee structure could align itself to individual Types or clusters of Types.
Cheers,
-Zach
--
Zachary Trautt, Ph.D.
ORCID: 0000-0001-5929-0354
Materials Research Engineer
Materials Measurement Science Division
National Institute of Standards and Technology
(301) 975-4539
zachary.trautt@nist.gov<mailto:zachary.trautt@nist.gov>
Preferred pronouns: he/him/his
From: "smrtucson@gmail.com" <smrtucson@gmail.com>
Date: Friday, February 19, 2021 at 2:08 PM
To: 'Dan Brickley' <danbri@google.com>, 'Thad Guidry' <thadguidry@gmail.com>
Cc: "'schema.org Mailing List'" <public-schemaorg@w3.org>
Subject: RE: GitHub Discussions FTW!
Resent-From: <public-schemaorg@w3.org>
Resent-Date: Friday, February 19, 2021 at 2:05 PM
Dan—Interesting conversation.
I was struck by the statement “the systematic problem we have: there's a lack of conventions for where and how to file issues and comments on schema.org<https://gcc02.safelinks.protection.outlook.com/?url=http%3A%2F%2Fschema.org%2F&data=04%7C01%7Czachary.trautt%40nist.gov%7C2db9f4c727a0421d6a5408d8d509b52f%7C2ab5d82fd8fa4797a93e054655c61dec%7C1%7C1%7C637493584966257234%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C3000&sdata=F%2BAWYHsKyzDkQN%2FjloJBvZVlVqv28fFgrihjNSX2SIg%3D&reserved=0> terms after they've been added”; I’d add that from my perspective as a user trying to use and promote schema.org descriptions for science data, a larger issue is a lack of transparency on the decision making process that determines when terms will be added to the vocabulary.
I recognize that schema.org is intended to be useful, but there’s a trade off. Developers generally take the simplest route to solving their immediate problem; conforming to standards requires more thought and work in general. Thus if the criteria for adoption is that a term is used in applications, we get what we have—a giant cloud of terms that are specific to some particular application but commonly difficult to extend for other applications. This is not good for interoperability. In my particular applications, funder, Grant, Award, measuredVariable and Observation come to mind. It seems that modularization of the namespace is going to have to happen at some point, with teams managing terms in specific application domains.
steve
From: Dan Brickley <danbri@google.com>
Sent: Friday, February 19, 2021 10:29 AM
To: Thad Guidry <thadguidry@gmail.com>
Cc: schema.org Mailing List <public-schemaorg@w3.org>; Vladimir Alexiev <vladimir.alexiev@ontotext.com>
Subject: Re: GitHub Discussions FTW!
I hadn't seen Vladimir's frustrated tweet until your email arrived, but I share the frustration.
While much of the specific criticism lands on my desk, I will ask more generally for everyone's sake: let's try to be positive rather than angry. When you write angry messages to collaborators in a project like this during a pandemic, you are raising the emotional temperature in a room filled with people who are already dealing with the pandemic situation and its life-changing and life-threatening effects on their family, friends, colleagues, jobs, and priorities. Nobody here knows who exactly is dealing with what in their private lives right now, so if you feel like shouting at strangers on the internet, please take a socially distanced walk instead, or do it in another project; preferably your own. I will not use the pandemic as an excuse, there are certainly issues in our project here that should be addressed, and which predate the pandemic, but it is better to be kind, now especially.
First - on the specific proposal from Thad: Github Discussions is definitely worth investigating here. In fact Richard Wallis this week was ready to hit the switch and move
There is some backstory too: you might recall last year we had over 1000 open issues in https://github.com/schemaorg/schemaorg/issues and I flagged this as an unsustainable situation.
Since our vocabulary now has over 2500 terms in it (see https://schema.org/docs/schemas.html<https://gcc02.safelinks.protection.outlook.com/?url=https%3A%2F%2Fschema.org%2Fdocs%2Fschemas.html&data=04%7C01%7Czachary.trautt%40nist.gov%7C2db9f4c727a0421d6a5408d8d509b52f%7C2ab5d82fd8fa4797a93e054655c61dec%7C1%7C1%7C637493584966267191%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C3000&sdata=UwCcD8iLNvkp7OnrCsMc0QT0AuMV4lgsfW0zjjTTj1U%3D&reserved=0>) it is not unreasonable for there to be hundreds and hundreds of discussions of those terms. But 1000+ issues in our main repository was a dysfunctional situation, which I acknowledged in https://github.com/schemaorg/schemaorg/issues/2573, "We have too many open issues (1000)".
In that issue and nearby we discussed a few approaches to the problem, one of which was to tag stale issues automatically so that the can be bumped back up to get more of everyone's limited attention. The initial configuration of that Github addon was accidentally auto-closing issues at the same time for a few days, which didn't help matters.
The main change we implemented (which cut our core issue list from 1000+ to around 500 issues) was to move questions, suggestions and brainstorming off into another repository. I implemented this after discussing with Google Opensource colleagues how other high-visibility opensource projects were handling such issues (https://github.com/schemaorg/schemaorg/issues/2573#issuecomment-629470279) and just as Thad highlights the NodeJS experience ("I have seen firsthand just how wonderful it has made Nodejs community come together"), this change was also inspired by the NodeJS project's experience.
The result was that we ended up with many questions moved to the suggestions-questions-brainstorming repository (https://github.com/schemaorg/suggestions-questions-brainstorming). Maybe this was not ideal, and people have in recent weeks been mentioning Github Discussions as something that is mature and could help here. And on Monday's Twitter thread, we were being urged to set up a https://www.discourse.org/about<https://gcc02.safelinks.protection.outlook.com/?url=https%3A%2F%2Fwww.discourse.org%2Fabout&data=04%7C01%7Czachary.trautt%40nist.gov%7C2db9f4c727a0421d6a5408d8d509b52f%7C2ab5d82fd8fa4797a93e054655c61dec%7C1%7C1%7C637493584966267191%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C3000&sdata=1kuaIPond9jXubTdNT7cTu0%2BSbBhVJGSVUYAx6WONZ0%3D&reserved=0> server.
I recently asked Richard Wallis (who works as a part-time developer supporting the project, under contract from Google) to take a look into moving those threads back into the main repository as Discussions, but I think there is also a risk of seeking technical solutions to workflow/documentation and related problems here. Rather than jumping from tool to tool and implementing the switch to Discussions I asked him to hold off so we could get v12 out and have a workflow discussion. There are also other pieces of Github infrastructure that we could certainly be making better use of; most trivially issue tagging, but also the .github/ISSUE_TEMPLATE/ mechanism for creating workflows for different kinds of issues. For example Richard has migrated our integrity-checking tests from Travis-CI to Github Actions in this release, while integrating a link checker.
I have always believed that closed issues remain perfectly fine places to continue to share information, but I can understand if commentators feel that their insights will be going to waste if typed into an already-closed issue. So in https://github.com/schemaorg/schemaorg/issues/2291 Vladimir quite reasonably expressed his perspective on the proposal the issue tracked. Simon Cox suggested making a fresh issue. Let's set aside for now the substance of the critique ("ill conceived and badly executed") and look at the systematic problem we have: there's a lack of conventions for where and how to file issues and comments on schema.org<https://gcc02.safelinks.protection.outlook.com/?url=http%3A%2F%2Fschema.org%2F&data=04%7C01%7Czachary.trautt%40nist.gov%7C2db9f4c727a0421d6a5408d8d509b52f%7C2ab5d82fd8fa4797a93e054655c61dec%7C1%7C1%7C637493584966277150%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C3000&sdata=siGK1N1B27oQWFdXPa%2B6IIkVYSxVDzv4TEf2sHd%2BvvM%3D&reserved=0> terms after they've been added.
As part of the move to separate out suggestions, questions, and brainstorming from proposals that come with a serious commitment to implement in a *consuming* application, I have been encouraging everyone (including and especially my colleagues) to articulate explicitly if their proposals are associated with a commitment to implement. Schema.org was designed to be a vocabulary for large scale implementation by consuming applications, and we need to keep a focus on the need for its schemas to be *used* (i.e. consumed) rather than merely *published*. This has long been stated in https://github.com/schemaorg/schemaorg/blob/main/README.md and https://schema.org/docs/howwework.html<https://gcc02.safelinks.protection.outlook.com/?url=https%3A%2F%2Fschema.org%2Fdocs%2Fhowwework.html&data=04%7C01%7Czachary.trautt%40nist.gov%7C2db9f4c727a0421d6a5408d8d509b52f%7C2ab5d82fd8fa4797a93e054655c61dec%7C1%7C1%7C637493584966277150%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C3000&sdata=KmxMHikiYkhXna5Zkt4nNOc1jnhaxLQS1YGZHg52kIE%3D&reserved=0> but needs to be made a more explicit part of our workflow both for making significant schema additions but also for evaluating those terms while they are in a "Pending" state.
There are several pieces to this: minimally when a term e.g. StatisticalPopulation or ClaimReview or whatever is accepted into schema.org<https://gcc02.safelinks.protection.outlook.com/?url=http%3A%2F%2Fschema.org%2F&data=04%7C01%7Czachary.trautt%40nist.gov%7C2db9f4c727a0421d6a5408d8d509b52f%7C2ab5d82fd8fa4797a93e054655c61dec%7C1%7C1%7C637493584966277150%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C3000&sdata=siGK1N1B27oQWFdXPa%2B6IIkVYSxVDzv4TEf2sHd%2BvvM%3D&reserved=0>, we should have a more systematic practice for tracking how it is being used in consuming applications. It should be much easier to find URLs like https://datacommons.org/browser/StatisticalPopulation<https://gcc02.safelinks.protection.outlook.com/?url=https%3A%2F%2Fdatacommons.org%2Fbrowser%2FStatisticalPopulation&data=04%7C01%7Czachary.trautt%40nist.gov%7C2db9f4c727a0421d6a5408d8d509b52f%7C2ab5d82fd8fa4797a93e054655c61dec%7C1%7C1%7C637493584966287104%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C3000&sdata=tGdssWY5WxlaPC4Py3T7tKhzw9v0sNouWM3H64cqN4g%3D&reserved=0> or https://www.storybench.org/how-claimreview-is-simplifying-the-process-of-fact-checking/<https://gcc02.safelinks.protection.outlook.com/?url=https%3A%2F%2Fwww.storybench.org%2Fhow-claimreview-is-simplifying-the-process-of-fact-checking%2F&data=04%7C01%7Czachary.trautt%40nist.gov%7C2db9f4c727a0421d6a5408d8d509b52f%7C2ab5d82fd8fa4797a93e054655c61dec%7C1%7C1%7C637493584966287104%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C3000&sdata=uOiGLstROb4lXZ1SvtgAZLAFv9hfKnqEupHHQkV8nAQ%3D&reserved=0> or https://www.poynter.org/fact-checking/2020/how-the-duke-reporters-lab-used-the-political-conventions-to-perfect-its-automated-fact-checking-program/<https://gcc02.safelinks.protection.outlook.com/?url=https%3A%2F%2Fwww.poynter.org%2Ffact-checking%2F2020%2Fhow-the-duke-reporters-lab-used-the-political-conventions-to-perfect-its-automated-fact-checking-program%2F&data=04%7C01%7Czachary.trautt%40nist.gov%7C2db9f4c727a0421d6a5408d8d509b52f%7C2ab5d82fd8fa4797a93e054655c61dec%7C1%7C1%7C637493584966297059%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C3000&sdata=TjfcZpc6YCf6ROTmQ3BpUKJHrkEBFNxn0YV6kBJqg18%3D&reserved=0>. It should ideally also be part of our shared practice to document the specific structured data "graph shapes" that different consuming applications are using to validate schema.org<https://gcc02.safelinks.protection.outlook.com/?url=http%3A%2F%2Fschema.org%2F&data=04%7C01%7Czachary.trautt%40nist.gov%7C2db9f4c727a0421d6a5408d8d509b52f%7C2ab5d82fd8fa4797a93e054655c61dec%7C1%7C1%7C637493584966297059%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C3000&sdata=DOAa1YlbrS9LCsJV9rn2VLHue3j1nVS2KHqDibtdGKc%3D&reserved=0> data - using SHACL/ShEx standards. There should be a much clearer workflow for feedback on each term, and each bundle-of-terms-in-a-change-proposal. While I do not think it healthy to have 1000+ general open issues in the project's primary issue tracker, we could easily have e.g. 2500+ per-term threads in a dedicated repository or Discussions area, one per term. Vladimir is correct to point out that that it unclear whether feedback on pending terms is welcomed on closed issues, and that the conventions for when to leave issues open vs closed are unclear. It is also fair comment that the "leave public feedback" feedback form is not meeting any needs (it is very heavily spammed); we should remove it.
There's more to say on all this, but my core response is that Github Discussions may work, but only if we use it as part of a recentering around a documented process, so that people don't feel like they are working thanklessly on things that are being ignored, or confused about the kinds of contributions and collaboration being solicited. I am prioritising these and related issues recently, even if the results are not immediately obvious. In the meantime, enjoy your weekends...
cheers,
Dan
On Fri, 19 Feb 2021 at 15:34, Thad Guidry <thadguidry@gmail.com<mailto:thadguidry@gmail.com>> wrote:
Hi Dan and Vladimir,
I saw Vladimir's tweet about Schema.org GitHub issues and failing the community.
I think I see a solution where GitHub Discussions instead is already providing several other open source communities such as Gatsby, Nodejs, ImageMagick, just to name a growing few. I have seen firsthand just how wonderful it has made Nodejs community come together and keep the devs focused on solving issues.
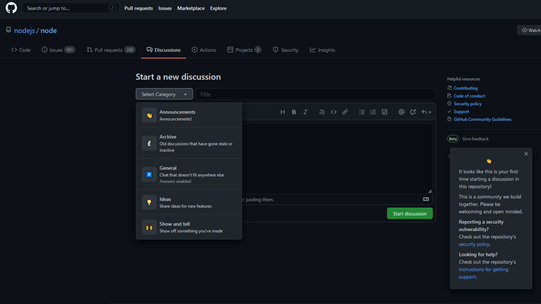
GitHub Discussions could be enabled to provide the community a place to discuss that is separate from GitHub Issues and where you and team would be able to turn any discussion into an issue with 1 click whenever desired or needed. Discussions are threaded, linkable, can upvote, and supports Markdown, and where you can create general categories such as below:
[cid:image001.png@01D706D1.C32D33D0]
GitHub Discussions can be enabled in the project settings.
https://docs.github.com/en/discussions/collaborating-with-your-community-using-discussions/about-discussions
Thad
https://www.linkedin.com/in/thadguidry/<https://gcc02.safelinks.protection.outlook.com/?url=https%3A%2F%2Fwww.linkedin.com%2Fin%2Fthadguidry%2F&data=04%7C01%7Czachary.trautt%40nist.gov%7C2db9f4c727a0421d6a5408d8d509b52f%7C2ab5d82fd8fa4797a93e054655c61dec%7C1%7C1%7C637493584966297059%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C3000&sdata=OR5eXrCG3JuAPjnKLXsUmKgwcxWDdbQ1EnPK%2FUa0Ono%3D&reserved=0>
https://calendly.com/thadguidry/<https://gcc02.safelinks.protection.outlook.com/?url=https%3A%2F%2Fcalendly.com%2Fthadguidry%2F&data=04%7C01%7Czachary.trautt%40nist.gov%7C2db9f4c727a0421d6a5408d8d509b52f%7C2ab5d82fd8fa4797a93e054655c61dec%7C1%7C1%7C637493584966307016%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C3000&sdata=fvIs0rGTHW%2F2%2FYMreVol1Y5XMqTqgUTAipLNOcNMgHQ%3D&reserved=0>
Attachments
- image/png attachment: image001.png
Received on Friday, 19 February 2021 20:15:06 UTC