- From: Michael Kifer <kifer@cs.sunysb.edu>
- Date: Fri, 12 Oct 2007 00:05:38 -0400
- To: Sandro Hawke <sandro@w3.org>
- Cc: public-rif-wg@w3.org
- Message-ID: <11673.1192161938@cs.sunysb.edu>
>
> I'm trying to think in minimalist, practical terms about Arch. What do
> we really need to say? I see a few things:
Good start. Some comments below.
> 1. What is required of all systems which take RIF documents as
> input? ("Minimal Requirements for all RIF Systems").
>
> Until we have a RIF Core, there's not very much to say here.
> Maybe if we end up with BLD and PRD but not Core, we'll say it
> has to conform to at least one of the two of them.
>
> One thing we do need to mandate here is forward compatibility;
> how must a system behave when given a RIF document which does
> not conform to the syntax of a dialect it implements? This
> section could get long if we go with a powerful fallback
> mechanism.
>
> I think the BLD document needs a conformance clause. Or maybe
> that goes in the BLD Test Cases document (as it did with OWL
> http://www.w3.org/TR/owl-test/#conformance ).
>
> 2. What does one need to do to define a proper RIF dialect?
> ("Publishing a New RIF Dialect")
>
> I suggest that the basic rules are:
>
> * No Language Conflict: every dialect MUST give the same
> semantics as each prior dialect does to any document
> which has a defined meaning in both dialects.
This may be too strict. An extension dialect should be allowed to make more
inferences, but should not invalidate existing inferences of the subdialects.
What this means precisely is open to interpretation. For instance, with CWA
the above should probably apply only to positive inferences (but I am not
sure whether this does not have undesirable side-effects).
> * Maximize Overlap: every dialect SHOULD reuse as much of
> the the syntax as possible from prior dialects.
Certainly as far as the XML syntax goes it should preserve all the syntax.
Otherwise, documents in a subdialect will not be legal docs in an extension
dialect.
> I think we should try defining some dialects using these
> principles, coordinating loosely as we like, but eventually I
> think we need to figure out how to open the process to 3rd
> parties. That's going to involve some careful work around
> defining "prior dialect".
>
> 3. What does one need to do to define a RIF extension?
>
> As I see it, an extensions is a "delta" between dialects where
> one dialect is a superset of the other.
>
> NewDialect = OldDialect + Extension
>
> What is challenging about extensions is that we want them to
> be orthogonal; we want users to be able to combine extensions
> which were developed independently. For this example, I'll
> assume Lists end up in an extension, instead of in BLD. I don't
> want to do that, but it makes a good example:
>
> BLD_with_NAF = BLD + NAF_Extension
>
> The BLD_with_NAF dialect should be fully specified
> by the NAF_Extension spec read in combination with
> BLD.
>
> BLD_with_Lists = BLD + Lists_Extension
>
> The BLD_with_Lists dialect should be fully specified
> by the Lists_Extension spec read in combination with
> BLD.
>
> BLD_with_Lists_and_NAF = BLD + NAF_Extension + Lists_Extension
>
> We would like the semantics here to be fully
> determined by the two extension specs and BLD. This
> is the challenge. How can the documents be written
> such that this is the case?
>
> At the syntactic level this is clear enough, if you think of the
> sets of strings/documents conforming to the syntax. An
> extension provides a set of strings, and "+" above is set-union.
> The question is how do we address this at the semantic level?
> Is there a way to address it across all approaches to defining
> semantics, or is this easy to do for model-theoretic semantics
> and impossible for procedural semantics? (My sense is that it's
> trivial for proof-theoretic semantics; I'm unclear on the
> others. I think Michael Kifer has in mind how to do this with
> MT semantics on BLD, but I don't understand that part yet.)
>
> It may well be that some extensions are incompatible (such as
> NAF and classical negation?), in which case the combination
> procedure should fail, I would hope.
Many extensions are orthogonal both syntactically and semantically. But not
all, as you said. We should strive to define extensions that are orthogonal
as much as possible, and when they are not we should indicate that.
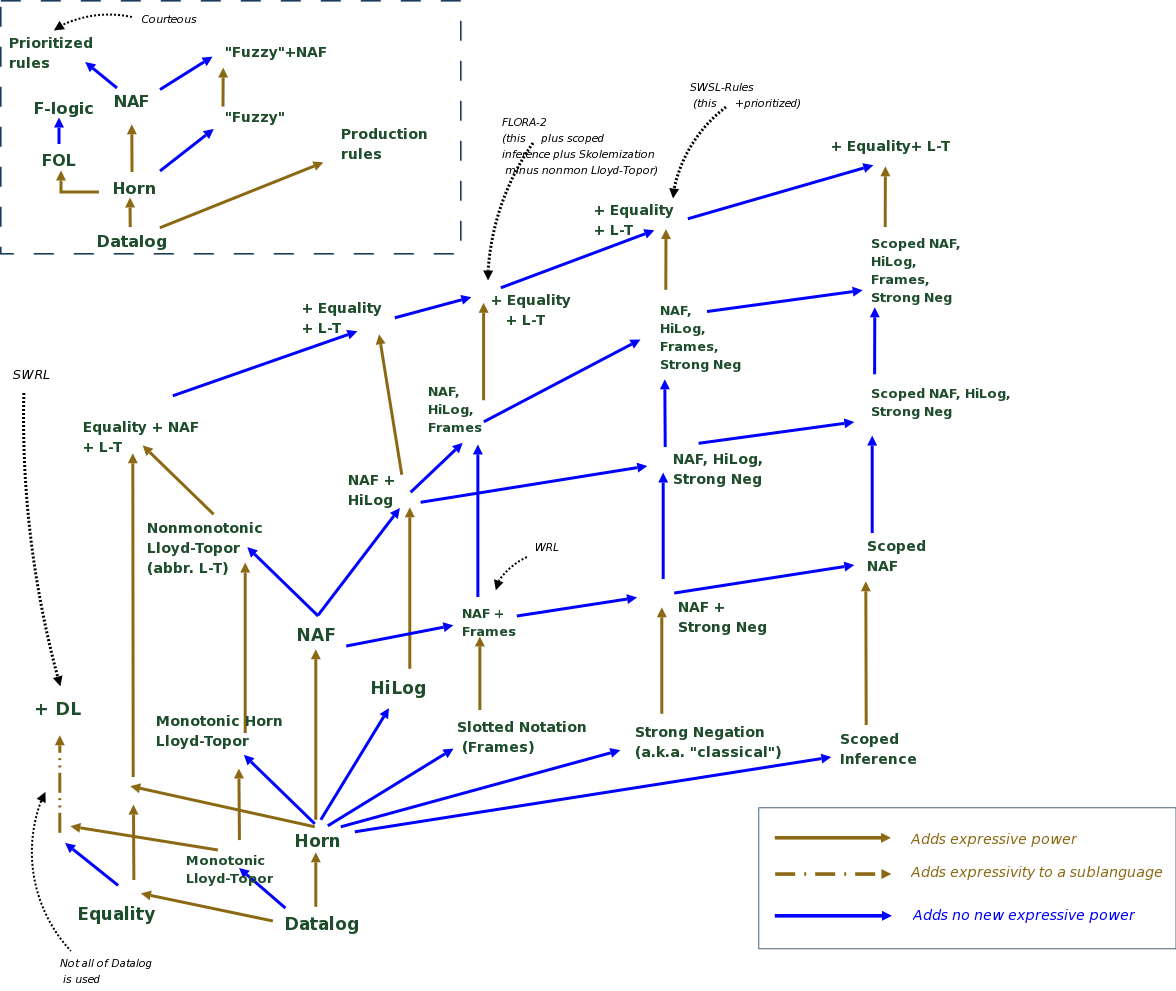
A while ago I sent around a picture that contained the various extensions.
The picture is very complicated to my taste, but it is fairly comprehensive.
I am attaching it again.
The SWSF member note
http://www.w3.org/Submission/2005/SUBM-SWSF-SWSL-20050909/#sec-language
has a much simpler picture, but not as complete.
>
> Note that I see no need to mention abstract syntaxes or presentation
> syntaxes. For these purposes, all we care about is the XML. (I'm not
> thrilled about it, but I can't find a compelling reason to address
> more than XML in this material. At least, not yet.)
We should advise/encourage to make the presentation syntaxes compatible as
well, but it should not be a requirement, I agree. This is because the
usual presentation syntaxes do not have as many tricks in their hat as XML
does.
--michael
> Oh yeah, and external data and data models. I keep forgetting about
> that. Or is that in an extension? :-) [the charter puts it in Phase 2,
> remember.]
>
> -- Sandro
>
>
Attachments
- image/png attachment: taxonomy.png
Received on Friday, 12 October 2007 04:06:22 UTC