- From: Young,Jeff (OR) <jyoung@oclc.org>
- Date: Sat, 4 Sep 2010 22:49:54 -0400
- To: "Thomas Baker" <tbaker@tbaker.de>
- Cc: "Andy Powell" <andy.powell@eduserv.org.uk>, "Karen Coyle" <kcoyle@kcoyle.net>, <public-lld@w3.org>
- Message-ID: <52E301F960B30049ADEFBCCF1CCAEF5909994E9D@OAEXCH4SERVER.oa.oclc.org>
Tom,
I agree that HTTP URIs are ultimately opaque and the semantics need to
be expressed in RDF. Nevertheless, I believe that every URI token and
truncation point should be modeled for usability and consistency. It
would be great if we could articulate this convincingly on the wiki
eventually. See if the arguments below help:
> > > > http://example.org/bib/12345/x-dc.rdf
> > > > http://example.org/bib/12345/frbr.rdf
> > > > http://example.org/bib/12345/marc21.xml
> > > > http://example.org/bib/12345/marc21.mrc
> >
>
http://www.w3.org/2005/Incubator/lld/wiki/Use_Case_Subject_Search#Prefa
> ce_on_URI_patterns
>
> Picking up on this point... The examples given for
> "303 URIs forwarding to One Generic Document" show
>
> http://www.example.com/doc/alice
>
> redirecting to
>
> http://www.example.com/doc/alice.rdf
> http://www.example.com/doc/alice.html
Sorry for the nitpick, but the 1st URI identifies the "generic document"
and doesn't do a redirect in this Linked Data pattern (note the /doc vs.
/id path segment). Here's the diagram we can refer to if the situation
is somehow unclear:
http://www.w3.org/TR/cooluris/img20081203/hash_conneg.png
> If one were to retrieve these files using HTTP (e.g., with "wget"),
the
> files would be called:
>
> alice.rdf
> alice.html
The concept of "file" is problematic and may be worth discussing. The
Cool URIs document actually makes a point about this:
"Note that a Web document is not the same as a file:"
http://www.w3.org/TR/cooluris/#oldweb
I would argue that the URI pattern that appears in the Cool URIs
document is only useful for toy examples. This is because every single
individual in every single class would be competing for the same XYZ
path segment tokens:
http://www.example.org/id/XYZ
This would quickly become a headache if the domain cares about multiple
people named "alice" and possibly also some rock bands and places named
"alice". The domain could go to the extreme of assigning an opaque
sequential number to individuals across classes, but this is an
excessive constraint that is directly analogous to such a restriction on
relational database primary keys.
> In your example, if one were to retrieve the following MARC21-in-XML
> records:
>
> http://example.org/bib/12345/marc21.xml
> http://example.org/bib/67890/marc21.xml
> http://example.org/bib/45678/marc21.xml
>
> they would by default all have the same name:
>
> marc21.xml
We need to parse the meaning of "the same name" carefully. Based on the
URI pattern I'm using, I would argue that "marc21.xml" is the
"representation-name" only:
http://example.org/{class-name}/{instance-name}/{representation-name}
class-name: "bib"
instance-name: "12345", "67890", "45678", etc.
representation-name: "marc21.xml", "about.rdf", "default.html", etc.
I'm not saying this is the only way to model URI patterns that makes
sense, but these path segment abstractions should align with facets in
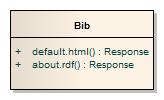
the domain's ontologies and facilitate unexpected reuse. I like modeling
OWL in UML, so check the attached image to see how I would model
representation-names in a class diagram.
> Granted, URIs are opaque, and maybe I'm looking at this too
> simplistically, but it seems prudent to follow examples such as
>
> http://www.bbc.co.uk/music/artists/a3cb23fc-acd3-4ce0-8f36-
> 1e5aa6a18432.rdf
By my way of thinking, every single path segment in a URI can and SHOULD
be modeled. Here's how I would rationalize your BBC example:
class-name: "Music/Artist"
instance-name: "a3cb23fc-acd3-4ce0-8f36-1e5aa6a18432"
representation-name: ".rdf"
Light alteration to fit my preferred pattern would result in something
like this:
http://example.org/MusicArtist/a3cb23fc-acd3-4ce0-8f36-1e5aa6a18432/abou
t.rdf
I like this pattern better for a variety of reasons that include 1)
direct translation to and from the domain model, 2) hackability to a
generic document and real world object URI, and 3) support for multiple
content-negotiable representations with the same media-type:
Real World Object:
http://example.org/MusicArtist/a3cb23fc-acd3-4ce0-8f36-1e5aa6a18432
Generic Document:
http://example.org/MusicArtist/a3cb23fc-acd3-4ce0-8f36-1e5aa6a18432/
Conventional HTML:
http://example.org/MusicArtist/a3cb23fc-acd3-4ce0-8f36-1e5aa6a18432/defa
ult.html
Mobile HTML:
http://example.org/MusicArtist/a3cb23fc-acd3-4ce0-8f36-1e5aa6a18432/mobi
le.html
> http://id.loc.gov/authorities/sh85017454.rdf
Based on my belief that every path segment SHOULD be modeled, my
instinct would be to rationalize this URI like so:
class-name: "Authority"
instance-name: "sh85017454"
representation-name: ".rdf"
The actual class modeled in RDF by LCSH is (SKOS) "Concept", though, so
the URI pattern I prefer would have looked something like:
http://example.org/Concept/sh85017454/about.rdf
> which, when retrieved with HTTP, result in the files:
>
> a3cb23fc-acd3-4ce0-8f36-1e5aa6a18432.rdf
> sh85017454.rdf
>
> In other words, I would expect:
>
> http://example.org/bib/12345
>
> to be associated with a MARC21-in-XML representation named
> along the lines of:
>
> http://example.org/bib/12345-marc21.xml
For the reasons state above, my preferred URI pattern for this example
would have been:
http://example.org/bib/12345/marc21.xml
class-name: "bib"
instance-name: 12345
representation-name: marc21.xml
"Linked Data" factors into all this like so:
Real World Object: http://example.org/bib/12345
Generic Document: http://example.org/bib/12345/
Web Document: http://example.org/bib/12345/default.html
Web Document: http://example.org/bib/12345/mobile.html
Web Document: http://example.org/bib/12345/about.rdf
Web Document: http://example.org/bib/12345/marc21.xml
Web Document: http://example.org/bib/12345/marc21.html
Etc.
Ultimately, the value of Linked Data boils down to unexpected reuse of
well-modeled resources suitable for use from diverse perspectives.
Regrettable URI patterns limit the domain's ability to reuse these
resources unexpectedly themselves. Take any of the URI examples you've
given and ask yourself how they could be enhanced to support mobile
browsers without crippling desktop browsers or separating themselves
from the Semantic Web in the process.
There's more to this URI pattern's story, but this seems like a good
start. The $64 question is whether people think URI patterns are the
latter-day equivalent of angels on the head of a pin?
Jeff
>
> i.e., when retrieved, the file:
>
> 12345-marc21.xml
>
> Tom
>
> [1] http://www.w3.org/TR/cooluris/#r303gendocument
>
> --
> Thomas Baker <tbaker@tbaker.de>
>
Attachments
- image/jpeg attachment: Web_Bib_Class.jpg
Received on Sunday, 5 September 2010 02:50:27 UTC