- From: <jrmt@almas.co.jp>
- Date: Thu, 26 Jan 2017 10:30:21 +0900
- To: "'Liang Hai'" <lianghai@gmail.com>
- Cc: "'Greg Eck'" <greck@postone.net>, "'r12a'" <ishida@w3.org>, <public-i18n-mongolian@w3.org>, <foximoyi@icloud.com>, <csmhjy@126.com>, "'siqin'" <siqin@almas.co.jp>
- Message-ID: <001301d27773$c3167920$49436b60$@almas.co.jp>
Liang Hai, I am not sure you can read Mongolian or not ? But you are really not understanding current Unicode Mongolian Encoding standard is confusing users and the main reason is encoding a lot of Ancient Mongolian with Modern Mongolian. Because, There are a lot of Ancient Mongolian characters had been introduced to encode in WG2, It is clear we have other selection beside using VS. But if, introduce VS and push the Modern Mongolian Encoding on the unstable status for a long term. That is killing the Mongolian Language itself. For your reference, Most of other Language, like Chinese, Japanese, all have their modern character part is in the BMP. But their Ancient Characters are using VS or Ligatures of the special Components which is defined in Unicode Extended Plane. My proposal is constructive as well as technically possible. Please consider it carefully again. Regards, Jirimutu =============================================================== Almas Inc. 101-0021 601 Nitto-Bldg, 6-15-11, Soto-Kanda, Chiyoda-ku, Tokyo E-Mail: jrmt@almas.co.jp <mailto:jrmt@almas.co.jp> Mobile : 090-6174-6115 Phone : 03-5688-2081, Fax : 03-5688-2082 http://www.almas.co.jp/ http://www.compiere-japan.com/ http://www.mongolfont.com/ --------------------------------------------------------------- Inner Mongolia Delehi Information Technology Co. Ltd. 010010 13th floor of Uiles Hotel, No 89 XinHua east street XinCheng District, Hohhot, Inner Mongolia Mail: jirimutu@delehi.com <mailto:jirimutu@delehi.com> Mobile:18647152148 Phone: +86-471-6661969, Ofiice: +86-471-6661995 http://www.delehi.com/ =============================================================== From: Liang Hai [mailto:lianghai@gmail.com] Sent: Thursday, January 26, 2017 12:49 AM To: jrmt@almas.co.jp Cc: Greg Eck <greck@postone.net>; r12a <ishida@w3.org>; public-i18n-mongolian@w3.org; foximoyi@icloud.com; csmhjy@126.com; siqin <siqin@almas.co.jp> Subject: Re: Bordering clearly between Mordern Mongolian and Ancient Mongolian solution. <https://tr.cloudmagic.com/h/v6/emailtag/tag/1485359318/2b566f421423f5d0ca9f4185f69ad7cc/10a8f86eb471143d1a21b676521d3e60/5de84a229fc01f1e56ab1b40ca46abc8/9f9d39c8ed1e4903a9f233fc361422a7/newton.gif> About variants, for now my major concerns are: 1. There is clear correspondence between modern variant forms and most (if not all) of those proposed historical ones. Isn't it a typical case that should be handled by fonts? It's crazy to ask for separate encoding. Reasoning must be clearly documented for why such a two-dimensional (synchronic graphemic opposition vs diachronic evolution) issue is proposed to be handled in a single dimension. 2. VS and FVS are intended to be different and have different technical aspects and implementations. There should be a thorough study with text engine developers (say, Roozbeh) about potential side effect of any kind of planned mixed use in Mongolian encoding. 梁海 Liang Hai On Wed, Jan 25, 2017 at 6:19 PM, jrmt@almas.co.jp <mailto:jrmt@almas.co.jp> <jrmt@almas.co.jp <mailto:jrmt@almas.co.jp> > wrote: (Resending by my registered mail address.) Hi Greg & Richard Ishida I am reading Mongolian Variant Form list on <https://r12a.github.io/mongolian-variants/> https://r12a.github.io/mongolian-variants/ now. We have got another one additional column WG2, that is sourced from the proposals in <http://www.unicode.org/L2/L2016/16309-mongolian-adds.pdf> L2/16-309, Proposed additions for Mongolian in 5th edition of UCS (26 October, 2016). I did read the original proposal documents in Inner Mongolia, but it was slightly different with this final version. I think this L2/16-309 document is the final version of the proposal to WG2 from Chinese government. Before getting into detailed discussion, I should introduce the current situation of this document in Inner Mongolia. This document is not widely accepted by most of the Inner Mongolian Experts till now. There are a lot of Mongolian people are discussing and arguing on this proposals making more confusion on Mongolian Unicode Encoding. Most of the end users are angering at the proposed experts are only concentrating on Ancient Mongolian and clearly ignoring the Modern Mongolian Usage. Currently, the Modern Mongolian Unicode part have not been able to get reach to stabilized and unified status. All of the Mongolian users are greatly confused the implementation differences and are strongly expecting all of them unified on one encoding rule as soon as possible. According to current situation, we should primarily concentrate our all discussion on Modern Mongolian part (include Mongolian, Todo, Sibe, Manchu) is the proper approach. After get the Modern Mongolian stabilized, we can continue to discuss the Ancient Mongolian part to get broaden ability to handle all of the history materials. When we are implementing the Modern Mongolian part of the Encoding, if we discuss them with the Ancient Mongolian part, 1. It will become long term discussion or endless argument. 2. The Ancient Mongolian character variant occupies the Modern Mongolian Encoding space, and lead the FVSs shortage. (L2/16-309 already introduced VS1, VS2…). Here I would like to introduce one Bordering Principle for Modern Mongolian and Ancient Mongolian. 1. For the Modern Mongolian Variant Form, we use FVS1, FVS2, FVS3. 2. For the Ancient Mongolian Variant Form, we use VS1, VS2, VS3, VS4,…….. Currently, in our DS01, we are facing one FVS shortage for U182D_GA medial form. 3. I propose we pull all of the U182C_QA and U182D_GA, feminine forminto the Ancient Mongolian. It will make the Modern Mongolian Encoding more easy and more clear.(DS01 already put the medial U182C_QA,and U182D_GA) I would like to ask all of your opinion on this and expect to get agreement on it. It will give our Mongolian End user more understandable, clear encoding solution and not restricting the researchers requirements. I would like to ask Chen Zhuang, if you are reading this forum,please ask if Professor Que agrees this proposals or not. Otherwise, It is hardly to persuade all of the Mongolian people who are arguing against him now, I think. Thanks and Best regards, Jirimutu =============================================================== Almas Inc. 101-0021 601 Nitto-Bldg, 6-15-11, Soto-Kanda, Chiyoda-ku, Tokyo E-Mail: jrmt@almas.co.jp <mailto:jrmt@almas.co.jp> Mobile : 090-6174-6115 Phone : 03-5688-2081, Fax : 03-5688-2082 http://www.almas.co.jp/ http://www.compiere-japan.com/ http://www.mongolfont.com/ --------------------------------------------------------------- Inner Mongolia Delehi Information Technology Co. Ltd. 010010 13th floor of Uiles Hotel, No 89 XinHua east street XinCheng District, Hohhot, Inner Mongolia Mail: jirimutu@delehi.com <mailto:jirimutu@delehi.com> Mobile:18647152148 Phone: +86-471-6661969, Ofiice: +86-471-6661995 http://www.delehi.com/ ===============================================================
Attachments
- application/octet-stream attachment: image001.png
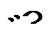{kind=link}
Received on Thursday, 26 January 2017 01:30:55 UTC