- From: 木田泰夫 <kida@mac.com>
- Date: Wed, 4 Aug 2021 16:38:07 +0900
- To: JLReq TF 日本語 <public-i18n-japanese@w3.org>
- Message-Id: <80CDA39E-E9C6-42C7-9272-02B2A16283E3@mac.com>
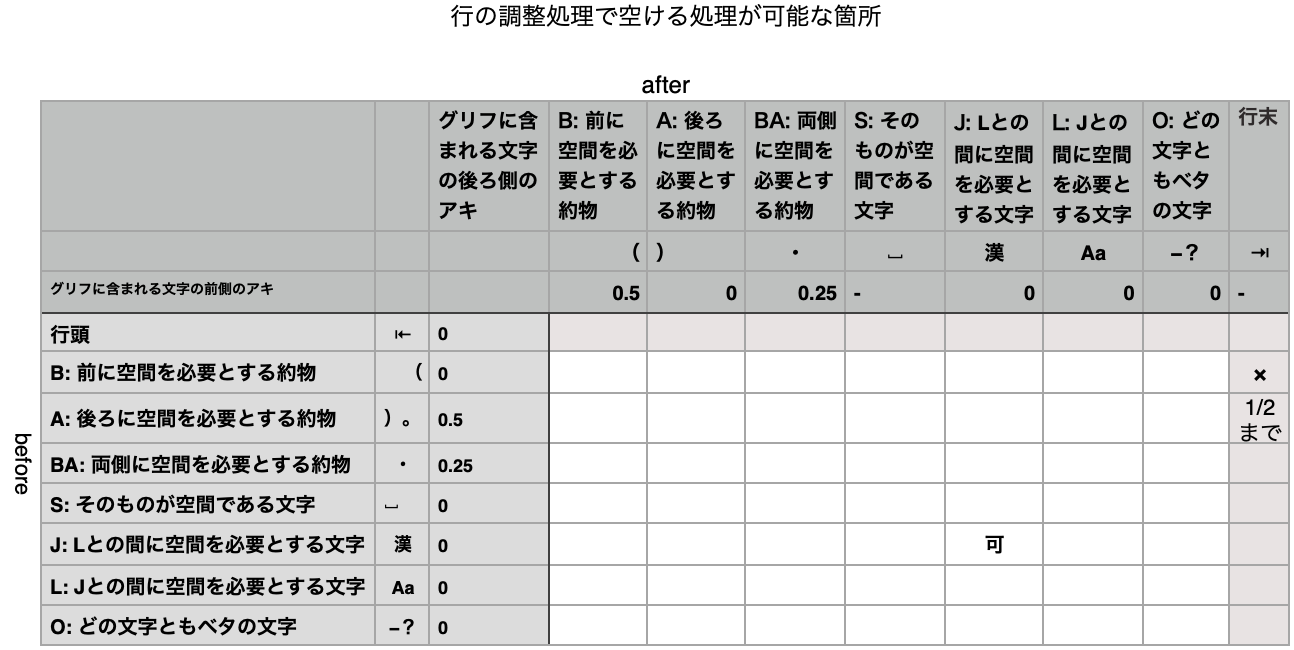
文書を markdown 形式にして GitHub に入れました。結構書き加えて 8/4 バージョンになっています。 https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md 木田 ––––––––––––––––––––––––––––––––––– Unicode に拡張した字間プロパティ JLReq の国際化に向けて、JLReq 第二版 (11 August 2020) が定義している文字クラスを再構成し、文字間の空き量および行の調整処理のための新たなクラスのセットを定義した。目的はUnicode への拡張、およびよりシンプルにすることである。再構成されたクラスは文字に対して一意に定まるため、これをこの文章ではこれを字間プロパティと呼ぶ。 実際の字間量、調整量、それらを確保するためのなど方法については、新たに書かれるであろう組版要件のドキュメントに譲る(「簡便な行組版ルール(案)」をベースとしたものになろう)。 <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E6%96%B9%E9%87%9D>方針 Unicode 全体を対象に定義する 特に、第二版の文字クラス定義では全角互換文字が除外されているが、これらを陽に扱う 機能別にプロパティを定義する JLReq 第二版において文字クラスは、文字間の空き量 (Appendix B)、文字間での分割の可否 (Appendix C)、行の調整処理で詰める処理が可能な箇所 (Appendix D)、行の調整処理で空ける処理が可能な箇所 (Appendix E)、の四つの機能全てを記述できるように設計されている。この再構成ではクラス分けをシンプルにするため、機能ごとに分割して必要なプロパティを定義する。調査の結果、行の調整処理で空ける処理が可能な箇所 (Appendix E) に必要なプロパティは、文字間の空き量 (Appendix B) に必要なプロパティのサブセットであることが判明した。ゆえ、字間プロパティはこの両方の機能をサポートする。行の調整処理で詰める処理が可能な箇所、は「簡便な行組版ルール(案)」において削除されているので対象外。また、文字間での分割の可否に対応するプロパティは別の定義となる。 高レベルの構造に依存する組版機能のためのクラスを別に扱う 2020年に JLReq TF において文字クラスの見直しを行ない、高レベルの構造に依存する組版機能のためのクラスを別に扱うこととした。これらは各々の組版機能の項で振る舞いを定義する、もしくは仮想のクラス用いるなどの方法で定義する。この切り離しによりクラスを文字に対して一意に定まるプロパティとして定義することが可能になった。下記「除外するクラス」参照。 なお、最後の方針は「簡便な行組版ルール(案)」においても示されており、除外しているクラスは同一である。この文書で表すクラスは、「簡便な行組版ルール(案)」に示されたクラスを機能別に分け、Unicode に拡張したものと考えることができる。 <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E9%99%A4%E5%A4%96%E3%81%99%E3%82%8Bjlreq%E6%96%87%E5%AD%97%E3%82%AF%E3%83%A9%E3%82%B9>除外するJLReq文字クラス プレーンテキストでは存在せず、高レベルの構造に依存する組版機能のために定義されているJLReq文字クラスを除外する。これらは各々の組版機能の項で振る舞いを定義する。これらのクラスに属する全ての文字は、存続するクラスに含まれているためこれらのクラスは単に考慮から除外することができる。 cl-20 合印中の文字 cl-21 親文字群中の文字(添え字付き) cl-22 親文字群中の文字(熟語ルビ以外のルビ付き) cl-23 親文字群中の文字(熟語ルビ付き) cl-25 単位記号中の文字 cl-28 割注始め括弧類 cl-29 割注終わり括弧類 cl-30 縦中横中の文字 下記 cl-24 連数字中の文字は、コンピュータ組版が開発された当時に和文と組み合わせて使用された半角のアラビア数字であり、現代のシステムではほとんど用いられない。ゆえ、クラス、組版機能共に廃止する。文字コードとしては通常の数字であり、属する文字は全て存続するクラスに含まれる。また、cl-12 前置省略記号、cl-13 後置省略記号は cl-24 連数字中の文字と共に用いられるべきクラスであり、これらを同時に除外する。含まれる文字は全て下記に解説する字間プロパティにおいて、どの文字ともベタとなるクラスOとして扱う。 cl-24 連数字中の文字 cl-12 前置省略記号 cl-13 後置省略記号 <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E5%AF%BE%E8%B1%A1%E3%81%A8%E3%81%AA%E3%82%8Bjlreq%E6%96%87%E5%AD%97%E3%82%AF%E3%83%A9%E3%82%B9>対象となるJLReq文字クラス 従って以下のクラスが再構成の考慮対象となる。 cl-01 始め括弧類 cl-02 終わり括弧類 cl-03 ハイフン類 cl-04 区切り約物 cl-05 中点類 cl-06 句点類 cl-07 読点類 cl-08 分離禁止文字 cl-09 繰返し記号 cl-10 長音記号 cl-11 小書きの仮名 cl-14 和字間隔 cl-15 平仮名 cl-16 片仮名 cl-17 等号類 cl-18 演算記号 cl-19 漢字等 cl-26 欧文間隔 cl-27 欧文用文字 <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E5%AD%97%E9%96%93%E3%83%97%E3%83%AD%E3%83%91%E3%83%86%E3%82%A3%E3%81%AE%E6%A6%82%E8%A6%81>字間プロパティの概要 文字間の空き量、および行の調整処理で空ける処理が可能な箇所の定義に必要なクラスを7つに単純化することができた。それぞれのクラスは空き要求の性質だけで簡潔に説明することができる。 以下にそのクラスのプロパティ値、空き要求の簡潔な説明、およびJLReq第2版の文字クラスの文字がどこに属するかを示す。 B (space before): 前に空間を必要とする約物:始め括弧類 cl-01 A (space after): 後ろに空間を必要とする約物:終わり括弧類と句読点 cl-02, 06, 07 BA (space before and after): 両側に空間を必要とする約物:中点類 cl-05 S (space): そのものが空間である文字:和字間隔 cl-14 J (japanese): Lとの間に空間を必要とする文字:仮名と漢字 cl-09,10,11,15,16、および cl-19 の漢字 L (latin): Jとの間に空間を必要とする文字:cl-27 のうち Letter であるもの O (other): どの文字ともベタの文字:その他全ての文字。cl-03, 04, 08, 17, 18, 26、cl-19 の非漢字、cl-27 の非ラテンアルファベット ここで、B / A / BA に属する文字は、デジタルフォントの実装において、グリフ内部に必要な空間が埋め込まれているので、組版の際に文字の組み合わせによってそのスペースを削除するというレイアウト動作が必要になる。 また、典型的なデジタルフォントの実装では、B / A / BA / S / J の文字は全角幅、L の文字はプロポーショナル幅で実装されるが、そのような実装を必要とするわけではない。 この字間プロパティと、小林敏先生の著された「簡便な行組版ルール(案)」とを比較すると、cl-19 / 27 の分割、および行の折り返しをサポートするために J と O がさらに分割されている部分を除いて、一致している。 cl-19 / 27 の文字と記号への分離は、JLReq TF での議論の中で提案された方法である。記号類は全角であってもラテンアルファベットとの間に空間をとることの必要性が薄いことによる。この点が、JIS X 4051 や JLReq 第二版に沿った組版と、この字間プロパティを使用した組版の大きな違いである。今後具体例を見ながら熟成させる必要があろう。 <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E6%89%80%E5%B1%9E%E3%82%92%E5%A4%89%E6%9B%B4%E3%81%97%E3%81%9F%E6%96%87%E5%AD%97>所属を変更した文字 JLReq 文字クラスの見直しの議論の結果若干の文字の移動があった。字間プロパティに影響のあるもののみ以下に示す。 U+00AB 始め二重山括弧引用記号・始めギュメ:cl-01 から削除。クラス O に U+00BB 終わり二重山括弧引用記号・終わりギュメ:cl-01 から削除。クラス O に また、以下のコードポイントは和文書体であってもプロポーショナルで実装されているゆえ、cl-01 / cl-02 から除外して取り扱い、結果クラス O となる。これらのコードポイントに対応する和文文字をどのようにするかの議論が必要である。注 U+2018 LEFT SINGLE QUOTATION MARK(左シングル引用符 cl-01) U+201C LEFT DOUBLE QUOTATION MARK(左ダブル引用符 cl-01) U+2019 RIGHT SINGLE QUOTATION MARK(右シングル引用符 cl-02) U+201D RIGHT DOUBLE QUOTATION MARK(右ダブル引用符 cl-02) 注: 同様な問題のある文字には他に、U+2010 HYPHEN(ハイフン)、U+2013 EN DASH(ダッシュ(二分))、U+2014 EM DASH(ダッシュ(全角))、U+2025 TWO DOT LEADER(二点リーダ)、U+2026 HORIZONTAL ELLIPSIS(三点リーダ)がある。これらは字間プロパティの定義に影響はなく、和字グリフであろうと欧文グリフであろうと、クラス O となる。 <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E6%96%87%E5%AD%97%E9%96%93%E3%81%AE%E7%A9%BA%E3%81%8D%E9%87%8F%E3%81%AE%E8%A1%A8>文字間の空き量の表 JLReq 第二版 Appendix B の表を、新たなクラスで表現したものを参考のためここに示す。数値がマイナスの場合、それは文字の組み合わせの間に含まれるグリフ由来の空間を指定量だけ削除することを意味する。 ここに示した数字は JLReq 第2版が示している空き量を新しい字間プロパティで表現するとどうなるかを示すための参考であって、実際の量やそれを確保するための方法については、新たに書かれるであろう組版要件のドキュメントに譲る。 <https://user-images.githubusercontent.com/33173251/128131343-8b716e8c-c1f2-4e1c-9357-938b20230866.png> <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#jlreq-%E7%AC%AC%EF%BC%92%E7%89%88%E3%81%8B%E3%82%89%E3%81%AE%E7%A9%BA%E3%81%8D%E9%87%8F%E3%81%AE%E5%A4%89%E6%9B%B4%E7%82%B9>JLReq 第2版からの空き量の変更点 クラスをよりシンプルにするため、以下の文字の組み合わせに対し空き量の変更を行った。以下に JLReq の記述に沿って和文約物を半角と考えた場合の空き量で変更点を示す。 句読点|中点:3/4 アキ→ 終わり括弧に合わせて四分アキ 句読点|和字間隔:二分アキ→ 終わり括弧に合わせてベタ 区切り約物|欧文:四分空き→ ベタ cl-19 を漢字と非漢字に分離。漢字のみがアルファベットと空間を作り J、非漢字はどの文字ともベタで O cl-27 をラテンアルファベットと記号に分離。ラテンアルファベットは漢字と空間を作るので L、記号はどの文字ともベタで O 上から三点は、「簡便な行組版ルール(案)」でも同じ変更がなされており、一致する。 <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E7%B5%84%E7%89%88%E8%A6%81%E4%BB%B6%E3%81%AE%E3%81%9F%E3%82%81%E3%81%AE%E3%83%A1%E3%83%A2>組版要件のためのメモ 上記の表で削除量を一般的な全角文字での実装を前提に示しているが、一般にどの量の空間を削除するのが適切かは書体デザインに依存する。そのため、組版要件のドキュメントを参考にしつつ、フォントが適切な削除可能量をアプリケーションに伝える方法での実装が期待される。(i.e. halt & chws) 空間の追加の必要な箇所は、J と L の間、つまり和欧文間である。上記に示された四分の量は、過去の技術的制約からきており、実際には大きすぎるとの意見が多い。 和欧文間の空間に関して、長期間にわたって空間が適切に確保されない実装が続いているため、この空間を確保する目的で U+0020 などのスペースが挿入されているテキストデータが多く存在し、また、コンテキストによって U+0020 を挿入するかどうかを切り替えてある例も見受けられる。 また、html のSegment Break Transformation Rules において、欧文との界面などに自動的に U+0020 が挿入される(”和欧文間の空き or Segment Break Transformation Rules”のメールスレッド参照)。欧文空白は通常全角の1/3ほどであるから、四分よりもさらに大きく空くことになり見かけが悪い。 我々は和欧文間に欧文空白 U+0020 が挿入されているデータと向き合う必要がある。U+0020 などが挿入されている場合に、どのような組版になるべきかの議論が必要であろう。 高レベルの構造に依存する組版機能を表す仮想クラスを作った場合、この表に対してどのようなものになるか調べてみた。 cl-30 縦中横:単純に J と同じ cl-20 合印:後ろに対してはベタで O、前に対してはアキを詰めるので A/BA/S または行末のように振る舞う cl-22/23 ルビ親文字:親文字の挙動は、ルビがはみ出るために空ける場合を除いてほぼ J に等しい、が、親文字が英字だったら? 結局、はみ出る時だけ例外処理すれば良いのでは cl-21 添え字付きの親文字、cl-25 単位記号中の文字:和文組版で定義する必要があるか要議論 cl-28 割注始め括弧類:後ろに対しては行頭的、前に対しては J と同じ(前側の二分の空白がないとして)。そもそも割注の括弧のグリフはどれ? cl-29 割注終わり括弧類:後ろに対しては J と同じ、前に対しては S 和文空白と同じ <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E8%A1%8C%E3%81%AE%E8%AA%BF%E6%95%B4%E5%87%A6%E7%90%86%E3%81%A7%E7%A9%BA%E3%81%91%E3%82%8B%E5%87%A6%E7%90%86%E3%81%8C%E5%8F%AF%E8%83%BD%E3%81%AA%E7%AE%87%E6%89%80%E3%81%AE%E8%A1%A8>行の調整処理で空ける処理が可能な箇所の表 同様に、調整処理で空ける処理が可能な箇所の表を、新たなクラスで表現したものを参考のためここに示す。こちらは「簡便な行組版ルール(案)」の表をベースとしている。U+0020 SPACE を空ける処理はこの表の前に最優先で行われる(が、本当にそれが最適?)。 ここに示した数字は JLReq 第2版が示している「調整処理で空ける処理が可能な箇所の表」を新しい字間プロパティで表現するとどうなるかを示すための参考であって、実際の調整量は、新たに書かれるであろう組版要件のドキュメントに譲る。 <https://user-images.githubusercontent.com/33173251/128131374-4c3d07a4-08ed-4ed5-9d1f-2c434e947a34.png> <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E5%AD%97%E9%96%93%E3%83%97%E3%83%AD%E3%83%91%E3%83%86%E3%82%A3%E3%81%AE-unicode-%E3%81%B8%E3%81%AE%E6%8B%A1%E5%BC%B5>字間プロパティの Unicode への拡張 上記のように JLReq の文字クラスを通じて定義した字間プロパティの Unicode への拡張を試みた。アプローチとして、各々のクラスの Unicode プロパティによる記述を試みた。この方法は、以下の議論に見るように、各クラスの性質を理解し、現在 JLReq で対象となっていない文字がどのクラスに属するべきかの考察に有用であった。 最終的に字間プロパティを Unicode に対して定義する方法は、字間プロパティを独立のプロパティとする方法や、ここで試みたように複数のプロパティの組み合わせとして定義する方法などが考えられるが、それは今後の議論にゆずる。 <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E7%94%A8%E3%81%84%E3%81%9F-unicode-%E3%83%97%E3%83%AD%E3%83%91%E3%83%86%E3%82%A3>用いた Unicode プロパティ General Category (GC) East Asian Width (EAW) EAW = F or W だと全角。A は全角とプロポーショナルと両方の可能性がある文字で注意が必要。Na はプロポーショナル、N はアジア圏では通常使われないという意味 PropList.txt にあるプロパティ (Property) Script Decomposition Type <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E6%99%AE%E9%80%9A%E3%81%AE%E5%85%A8%E8%A7%92%E3%81%AE%E5%AE%9A%E7%BE%A9>「普通の全角」の定義 「普通の全角」とは、 East Asian Width = W/F(全角)かつ Decomposition Type が vertical や small でない <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#b-%E5%89%8D%E3%81%AB%E7%A9%BA%E9%96%93%E3%82%92%E5%BF%85%E8%A6%81%E3%81%A8%E3%81%99%E3%82%8B%E7%B4%84%E7%89%A9%E5%A7%8B%E3%82%81%E6%8B%AC%E5%BC%A7%E9%A1%9E%E3%81%AE%E6%8B%A1%E5%BC%B5>B: 前に空間を必要とする約物:始め括弧類の拡張 普通の全角かつ General Category = Ps (Open_Punctuation: an opening punctuation mark (of a pair)) <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E6%96%B0%E3%81%9F%E3%81%AB%E5%8A%A0%E3%82%8F%E3%82%8B%E6%96%87%E5%AD%97>新たに加わる文字 新規に下二つの文字が加わる。どれもEAW全角で、手元の環境ではグリフ前半に半角空白があり、クラス B に含めて問題がなさそうだが、要確認。 〈 U+2329 LEFT-POINTING ANGLE BRACKET 〚 U+301A LEFT WHITE SQUARE BRACKET <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#a-%E5%BE%8C%E3%82%8D%E3%81%AB%E7%A9%BA%E9%96%93%E3%82%92%E5%BF%85%E8%A6%81%E3%81%A8%E3%81%99%E3%82%8B%E7%B4%84%E7%89%A9%E7%B5%82%E3%82%8F%E3%82%8A%E6%8B%AC%E5%BC%A7%E9%A1%9E%E3%81%A8%E5%8F%A5%E8%AA%AD%E7%82%B9%E3%81%AE%E6%8B%A1%E5%BC%B5>A: 後ろに空間を必要とする約物:終わり括弧類と句読点の拡張 普通の全角かつ [ General Category = Pe(終わり括弧類) または PropList に Terminal_Punctuation がある (cl-06, 07)(これらは GC=Po)(句読点) ] <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E6%96%B0%E3%81%9F%E3%81%AB%E5%8A%A0%E3%82%8F%E3%82%8B%E6%96%87%E5%AD%97-1>新たに加わる文字 新規に下三つの文字が加わる。どれもEAW全角で、手元の環境ではグリフ後半に半角空白があり、クラス A に含めて問題がなさそうだが、要確認。 〉 U+232A RIGHT-POINTING ANGLE BRACKET 〛 U+301B RIGHT WHITE SQUARE BRACKET 〞 U+301E DOUBLE PRIME QUOTATION MARK(終わりダブルミニュートに類似) 注:上の条件で区切り約物 cl-04 と中点類 cl-05 の全角コロン、セミコロンが混入する。これらはどれも句読点と同様に文を区切る役割があり、約物の役割としては同一なので既存 Unicode プロパティで見分けることができない。cl-06, 07 を独特にしているのはアキの必要量だけだと考えられるので、これらを見分けるには、アキの必要量を示す属性が Unicode に必要なことになる。が、字間プロパティ自体をプロパティにする方がスマートかもしれない。 <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#ba-%E4%B8%A1%E5%81%B4%E3%81%AB%E7%A9%BA%E9%96%93%E3%82%92%E5%BF%85%E8%A6%81%E3%81%A8%E3%81%99%E3%82%8B%E7%B4%84%E7%89%A9%E4%B8%AD%E7%82%B9%E9%A1%9E%E3%81%AE%E6%8B%A1%E5%BC%B5>BA: 両側に空間を必要とする約物:中点類の拡張 普通の全角かつ [ PropList に Hyphen があり、かつ General Category = Po (Other_Punctuation) (中点) または PropList に Terminal_Punctuation がある(全角コロン、セミコロン) ] 注:A で述べたように上の全角コロン、セミコロンを捕まえる条件で cl-04 区切り約物、cl-05/06 句読点も捕まってしまう。議論は A を参照。 <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E6%96%B0%E3%81%9F%E3%81%AB%E5%8A%A0%E3%82%8F%E3%82%8B%E6%96%87%E5%AD%97-2>新たに加わる文字 なし <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#s-%E3%81%9D%E3%81%AE%E3%82%82%E3%81%AE%E3%81%8C%E7%A9%BA%E9%96%93%E3%81%AA%E7%B4%84%E7%89%A9%E5%92%8C%E5%AD%97%E9%96%93%E9%9A%94>S: そのものが空間な約物:和字間隔 属する文字は一文字なので U+2000 決め打ち。 <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E6%96%B0%E3%81%9F%E3%81%AB%E5%8A%A0%E3%82%8F%E3%82%8B%E6%96%87%E5%AD%97-3>新たに加わる文字 なし <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#j-%E3%82%A2%E3%83%AB%E3%83%95%E3%82%A1%E3%83%99%E3%83%83%E3%83%88%E3%81%A8%E3%81%AE%E9%96%93%E3%81%AB%E7%A9%BA%E9%96%93%E3%82%92%E5%BF%85%E8%A6%81%E3%81%A8%E3%81%99%E3%82%8B%E6%96%87%E5%AD%97--%E4%BB%AE%E5%90%8D%E3%82%84%E6%BC%A2%E5%AD%97>J: アルファベットとの間に空間を必要とする文字 = 仮名や漢字 平仮名:全角、Script=Katakana、GC=L*(ヽヾが Lm、その他は Lo)注1 片仮名:全角、Script=Katakana、GC=L*(ゝゞが Lm、その他は Lo)注1 象形文字:全角、PropList = Ideographic, GC=Lo/Nl 注2 注1: GC=L* を入れないと丸で囲まれた片仮名などが捕まってしまう。GC=Lm のものは cl-09 で「簡便な行組版ルール(案)」においても和字、つまり J として扱われている。(が、大多数の cl-09 はここから漏れてしまう) 注2: GC は Lo か Nl のみ。CG=Nl を外すと〇および蘇州号碼 (HANGZHOU NUMERAL) が外れる。蘇州号碼は漢数字の一部も使用するので、これが入ることは理屈に合う。この定義で〆も拾う。漢字(Script=Han)以外の Script は、Common(〆のみ), Khitan_Small_Script, Tangut, Nushu。 <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E6%96%B0%E3%81%9F%E3%81%AB%E5%8A%A0%E3%82%8F%E3%82%8B%E6%96%87%E5%AD%97-4>新たに加わる文字 JIS X 0213 の範囲以外の漢字 女真文字 西夏文字 契丹文字 蘇州号碼 <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E8%AD%B0%E8%AB%96>議論 漢字や仮名と交換して使われる記号をどうするか。8/3 のミーティングで、〇 は数字の十や百などと入れ替わるので入れる、他はベタでも良いことに。ただし上の定義だと〆も J に入る。 上の定義で J に入るもの ゝ U+309D HIRAGANA ITERATION MARK (Lm, Script=Hiragana) ゞ U+309E HIRAGANA VOICED ITERATION MARK (Lm, Script=Hiragana) ヽ U+30FD KATAKANA ITERATION MARK (Lm, Script=Katakana) ヾ U+30FE KATAKANA VOICED ITERATION MARK (Lm, Script=Katakana) 〆 U+3006 IDEOGRAPHIC CLOSING MARK (Lo, Ideographic, Script=Common) 〇 U+3007 IDEOGRAPHIC NUMBER ZERO (Nl, Ideographic, Script=Han) 入らないもの cl-09(全て GC=Lm, Block = CJK Symbols and Punctuation) 々 U+3005 IDEOGRAPHIC ITERATION MARK (Script=Han) 〻 U+303B VERTICAL IDEOGRAPHIC ITERATION MARK (Script=Han) 〱 U+3031 VERTICAL KANA REPEAT MARK(およびその断片)(Script=Common) 〲 U+3032 VERTICAL KANA REPEAT WITH VOICED SOUND MARK(およびその断片) 入らないもの cl-19(全て Block = CJK Symbols and Punctuation, Script=Common) 〓 U+3013 GETA MARK (GC=So) 〼 U+303C MASU MARK (GC=Lo, cl-19 かつ GC=Lo なのはこれと〆) 〃 U+3003 DITTO MARK (GC=Po、つまり約物) 偏や旁のブロックは文の中では使われることを想定しておらず、文中でで使われる場合には周りの文字と紛らわしくないように何らかの約物を伴って現れると思われる。クラス O で OK。 ハングル文字は klreq によると、全角の場合とプロポーショナルの場合があり、どちらでもラテン文字との間にスペースを取らない。ゆえこのクラスに入れないのが適当。 <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#l-%E6%BC%A2%E5%AD%97%E9%A1%9E%E3%81%A8%E3%81%AE%E9%96%93%E3%81%AB%E7%A9%BA%E9%96%93%E3%82%92%E5%BF%85%E8%A6%81%E3%81%A8%E3%81%99%E3%82%8B%E5%A4%96%E5%9B%BD%E8%AA%9E%E6%96%87%E5%AD%97>L: 漢字類との間に空間を必要とする外国語文字 全角でも半角でもない、かつ GC=L* または GC=Nd <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E6%96%B0%E3%81%9F%E3%81%AB%E5%8A%A0%E3%82%8F%E3%82%8B%E6%96%87%E5%AD%97-5>新たに加わる文字 JIS X 0213 にある以外のラテンアルファベット、ギリシャ文字、キリル文字 JIS X 0213 にある以外の数字 (GC=Nd) 全ての全角でない文字(GC=L*) <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E8%AD%B0%E8%AB%96-1>議論 ローマ数字など GC=Nl はここに入るべき? 桁を表す ⅬⅭⅮⅯ などローマ字そっりの字もある。 <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#o-%E3%81%A9%E3%81%AE%E6%96%87%E5%AD%97%E3%81%A8%E3%82%82%E3%83%99%E3%82%BF%E3%81%A8%E3%81%AA%E3%82%8B%E6%96%87%E5%AD%97>O: どの文字ともベタとなる文字 上のどれでもないもの <https://github.com/w3c/jlreq/blob/gh-pages/docs/spacing_property/spacing_property.md#%E6%96%B0%E3%81%9F%E3%81%AB%E5%8A%A0%E3%82%8F%E3%82%8B%E6%96%87%E5%AD%97-6>新たに加わる文字 新しい分類なので全ての文字が新しい。 B/A/BA/S に含まれない全ての記号、約物、発音区別符号、数字類のうちローマ数字・囲み文字・分数など、空白文字、機能文字(GC!=L* / Nd) ほとんどの Letter(GC=L*)は J/L に含まれるが、全角でかつ象形文字でない文字、および半角互換文字はここに含まれる 和字のうち Letter だが象形文字の分類にないもの:々〻〼、長音、くの字点 全角英字 半角互換文字 ボポモフォ (Script=Bopomofo) ハングル (Script=Hangul) 彝文字 (イ文字、ロロ文字、Script=Yi)
Attachments
- text/html attachment: stored
- image/png attachment: 128131343-8b716e8c-c1f2-4e1c-9357-938b20230866.png

- image/png attachment: 128131374-4c3d07a4-08ed-4ed5-9d1f-2c434e947a34.png
Received on Wednesday, 4 August 2021 07:38:33 UTC