- From: 木田泰夫 <kida@mac.com>
- Date: Sun, 01 Aug 2021 11:13:21 +0900
- To: JLReq TF <public-jlreq-admin@w3.org>
- Message-Id: <D982A95A-B79E-46A4-B940-A7C27FB732E9@mac.com>
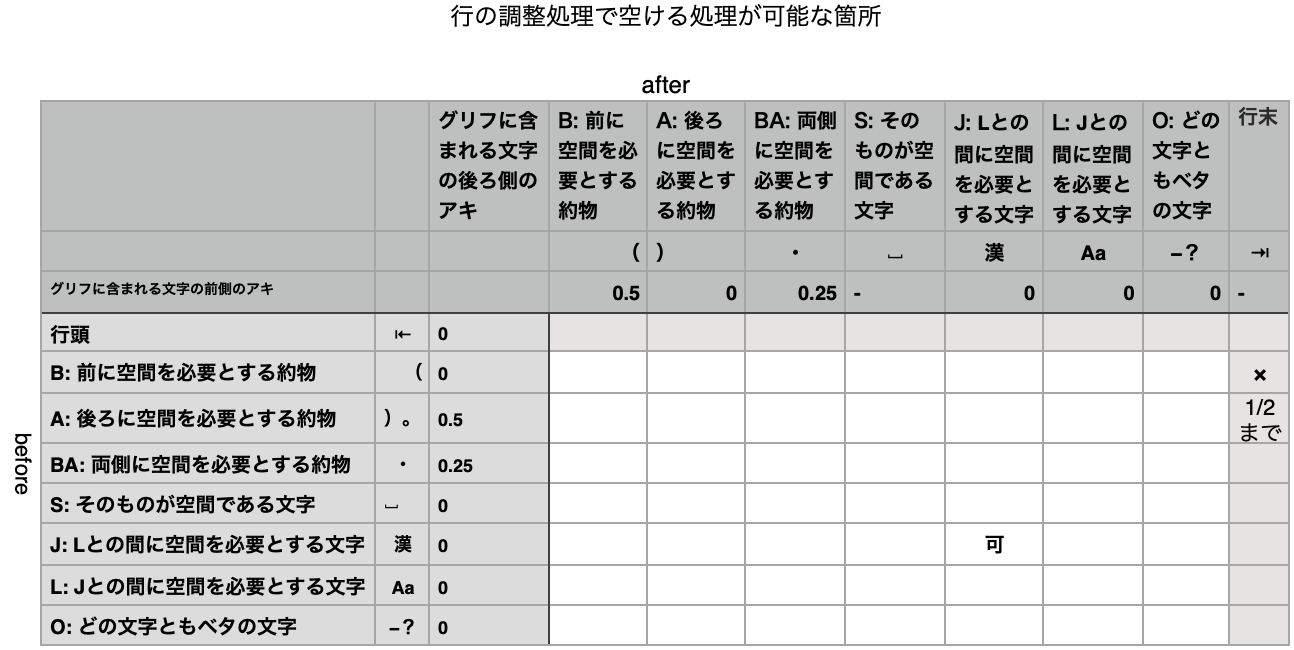
このタイトルの最初のメールは JLReq TF の英語の方に送ってしまっていました。日本語の方に再送します。また、ドキュメントの内容を少々アップデートしました。変更内容は: 所属を変更した文字、の記述を追加 字間プロパティの概要、の最後に議論を少々追加 行の調整処理で空ける処理が可能な箇所の表、組版要件のためのメモ、に勘違いによる記述があったので削除 表のイメージが小さくて見にくかったのを大きくした JLReq TF のメーリングリスト上で議論もしくは合意されたことで漏れていることがあればぜひ指摘してください。 –––––––––––––––– JLReq TF の皆様、 なんとか最初のドラフトをまとめました。ご査収ください。明後日のミーティングでは、この文書をレビューしましょう。 書いてみると、まだあちこちに未解決で決めなければならない箇所があります。GitHub に登録して潰してゆきますかね? 敏先生の「簡便な行組版ルール(案)」が参考になっており、それを参照している箇所も多いのですが、この文章って APL の報告書 <https://310f52f6-bfce-4d70-bd86-07371d7f98c5.filesusr.com/ugd/eb8538_e921485ff03b4900aff942b28019d9f4.pdf>の中にあるものが唯一でしたっけ? どこかにHTML文書として欲しいですね。 下農さん:このようなもの、どのように変更をトラックしてアーカイブするのが良いでしょう? 木田 –––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– Unicode に拡張した字間プロパティ JLReq の国際化に向けて、JLReq 第二版 (11 August 2020 <https://www.w3.org/TR/2020/NOTE-jlreq-20200811/>) が定義している文字クラスを再構成し、文字間の空き量および行の調整処理のための新たなクラスのセットを定義した。目的はUnicode への拡張、およびよりシンプルにすることである。再構成されたクラスは文字に対して一意に定まるため、これをこの文章ではこれを字間プロパティと呼ぶ。 方針 Unicode 全体を対象に定義する。特に、第二版の文字クラス定義では全角互換文字が除外されているが、これらを陽に扱う 文字クラスの見直しを反映する。2020年に JLReq TF において文字クラスの見直しを行ない、コンテキストに依存するクラスを将来の定義において採用しないことを合意した。これによりクラスを文字に対して一意に定まるプロパティとして定義することが可能になった。下記「削除するクラス」参照 機能別にプロパティを定義する。JLReq 第二版において文字クラスは、文字間の空き量 (Appendix B)、文字間での分割の可否 (Appendix C)、行の調整処理で詰める処理が可能な箇所 (Appendix D)、行の調整処理で空ける処理が可能な箇所 (Appendix E)、の四つの機能全てを記述できるように設計されている。この再構成ではクラス分けをシンプルにするため、機能ごとに分割して必要なプロパティを定義する。調査の結果、行の調整処理で空ける処理が可能な箇所 (Appendix E) に必要なプロパティは、文字間の空き量 (Appendix B) に必要なプロパティのサブセットであることが判明した。ゆえ、字間プロパティはこの両方の機能をサポートする。行の調整処理で詰める処理が可能な箇所、は「簡便な行組版ルール(案) 2018年5月19日(敏) Ver. 2. 1」において削除されているので対象外。また、文字間での分割の可否に対応するプロパティは別の定義となる。 削除するJLReq文字クラス プレーンテキストでは存在せず、高レベルの構造に依存する組版機能のために定義されているJLReq文字クラスを削除する。これらは各々の組版機能の項で振る舞いを定義する。これらのクラスに属する全ての文字は、存続するクラスに含まれているためこれらのクラスは単に考慮から除外することができる。 cl-20 合印中の文字 cl-21 親文字群中の文字(添え字付き) cl-22 親文字群中の文字(熟語ルビ以外のルビ付き) cl-23 親文字群中の文字(熟語ルビ付き) cl-25 単位記号中の文字 cl-28 割注始め括弧類 cl-29 割注終わり括弧類 cl-30 縦中横中の文字 下記 cl-24 連数字中の文字は、コンピュータ組版が開発された当時に和文と組み合わせて使用された半角のアラビア数字であり、現代のシステムではほとんど用いられない。ゆえ、クラス、組版機能共に廃止する。文字コードとしては通常の数字であり、属する文字は全て存続するクラスに含まれる。また、cl-12 前置省略記号、cl-13 後置省略記号は cl-24 連数字中の文字と共に用いられるべきクラスであり、これらを同時に削除する。含まれる文字は全て下記に解説する字間プロパティにおいて、どの文字ともベタとなるクラスOとして扱う。 cl-24 連数字中の文字 cl-12 前置省略記号 cl-13 後置省略記号 対象となるJLReq文字クラス 従って以下のクラスが再構成の考慮対象となる。 cl-01 始め括弧類 cl-02 終わり括弧類 cl-03 ハイフン類 cl-04 区切り約物 cl-05 中点類 cl-06 句点類 cl-07 読点類 cl-08 分離禁止文字 cl-09 繰返し記号 cl-10 長音記号 cl-11 小書きの仮名 cl-14 和字間隔 cl-15 平仮名 cl-16 片仮名 cl-17 等号類 cl-18 演算記号 cl-19 漢字等 cl-26 欧文間隔 cl-27 欧文用文字 所属を変更した文字 JLReq 文字クラスの見直しの議論の結果より、字間プロパティに影響のあるもののみ、以下に示す。 U+00AB 始め二重山括弧引用記号・始めギュメ:cl-01 から削除。cl-27 のみ U+00BB 終わり二重山括弧引用記号・終わりギュメ:cl-01 から削除。cl-27 のみ 字間プロパティの概要 文字間の空き量、および行の調整処理で空ける処理が可能な箇所の定義に必要なクラスを7つに単純化することができた。それぞれのクラスは空き要求の性質だけで簡潔に説明することができる。以下にそのクラスのプロパティ値、空き要求の簡潔な説明、およびJLReq第2版の文字クラスの文字がどこに属するかを示す。 B (space before): 前に空間を必要とする約物:始め括弧類 cl-01 A (space after): 後ろに空間を必要とする約物:終わり括弧類と句読点 cl-02, 06, 07 BA (space before and after): 両側に空間を必要とする約物:中点類 cl-05 S (space): そのものが空間である文字:和字間隔 cl-14 J (japanese): Lとの間に空間を必要とする文字:仮名と漢字 cl-9,10,11,15,16、および cl-19 の漢字 L (latin): Jとの間に空間を必要とする文字:cl-27 のうち Letter であるもの O (other): どの文字ともベタの文字:その他全ての文字。cl-03, 04, 08, 12, 13, 17, 18, 26、cl-19 の非漢字、cl-27 の非ラテンアルファベット ここで、B / A / BA の文字はデジタルフォントの実装においては、グリフ内部に必要な空間が埋め込まれているので、文字の組み合わせによってそのスペースを削除するというレイアウト動作が必要になる。 また、典型的なデジタルフォントの実装では、B / A / BA / S / J の文字は全角幅、L の文字はプロポーショナル幅で実装されるが、そのような実装を必要とするわけではない。 この字間プロパティと、小林敏先生の著された「簡便な行組版ルール(案) 2018年5月19日(敏) Ver. 2. 1」とを比較すると、cl-19 / 27 の分割を除いて、および行の折り返しをサポートするために J と O がさらに分割されている部分を除いて、一致している。 cl-19 / 27 の文字と記号への分離は、JLReq TF での議論の中で提案された方法である。記号類は全角であってもラテンアルファベットとの間に空間をとることの必要性が薄いことによる。おそらくこの点が、JIS X 4051 や JLReq 第二版に沿った組版と、この字間プロパティを使用した組版の最も大きな違いの一つである。今後具体例を見ながら少々熟成させる必要がある。 後にこれらのクラスの Unicode への拡張について述べるが、日本語で使用頻度の高い文字のクラス分けが最重要であるので、JLReq文字クラスから字間プロパティへのマッピングを合理的で安定したものにすることが最重要である。 文字間の空き量の表 Appendix B の表を、新たなクラスで表現したものを参考のためここに示す。数値がマイナスの場合、それは文字の組み合わせの間に含まれるグリフ由来の空間を指定量だけ削除することを意味する。 ここに示した数字は JLReq 第2版が示している空き量を新しい字間プロパティで表現するとどうなるかを示すための参考であって、実際の量やそれを確保するための方法については、新たに書かれるであろう組版要件のドキュメントに譲る。 JLReq 第2版からの空き量の変更点 クラスをよりシンプルにするため、以下の文字の組み合わせに対し空き量の変更を行った。以下に JLReq の記述に沿って和文約物を半角と考えた場合の空き量で変更点を示す。 句読点|中点:3/4 アキ→ 終わり括弧に合わせて四分アキ 句読点|和字間隔:二分アキ→ 終わり括弧に合わせてベタ 区切り約物|欧文:四分空き→ ベタ cl-19 を漢字と非漢字に分離。漢字のみがアルファベットと空間を作り J、非漢字はどの文字ともベタで O cl-27 をラテンアルファベットと記号に分離。ラテンアルファベットは漢字と空間を作るので L、記号はどの文字ともベタで O 上から三点は、「簡便な行組版ルール(案) 2018年5月19日(敏) Ver. 2. 1」においても同一の変更がなされている。 組版要件のためのメモ 上記の表では削除量を、一般的な全角文字での実装を前提に示しているが、一般にどの量の空間を削除するのが適切かは書体デザインに依存する。そのため、組版要件のドキュメントを参考にしつつ、フォントが適切な削除可能量をアプリケーションに伝える方法での実装が期待される。 J と L の間の空間、つまり和欧文間の空間について、上記に示された四分の量は、過去の技術的制約からきており、実際には大きすぎるとの意見が多い。 また、長期間にわたって和欧文間の空間が適切に確保されない実装が続いているため、この空間を確保する目的で U+0020 などのスペースが挿入されているテキストデータが多く存在し、また、コンテキストによって U+0020 を挿入するかどうかを切り替えてある例も見受けられる。また、html のSegment Break Transformation Rules において、欧文との界面などに自動的に U+0020 が挿入される(”和欧文間の空き or Segment Break Transformation Rules”のメールスレッド参照)。我々は和欧文間に欧文空白 U+0020 が挿入されているデータと向き合う必要がある。U+0020 などが挿入されている場合に、どのような組版になるべきかの議論が必要であろう。 行の調整処理で空ける処理が可能な箇所の表 同様に、調整処理で空ける処理が可能な箇所の表を、新たなクラスで表現したものを参考のためここに示す。こちらは、「簡便な行組版ルール(案) 2018年5月19日(敏) Ver. 2. 1」の表をベースとしている。U+0020 SPACE を空ける処理はこの表の前に最優先で行われる。 字間プロパティの Unicode への拡張 上記のように定義した字間プロパティの Unicode への拡張を試みた。以下に、Unicode プロパティによる記述、および新たに加わった文字について解説し議論する。このように既存の Unicode プロパティの組み合わせによってこの字間プロパティを表すべきかどうかには疑問がある。しかし以下の議論で見られるように、現在 JLReq で対象となっていない文字がどのクラスに属するべきかの考察に有用であり、また漏れてしまう文字から問題点を炙り出すことができた。 用いた Unicode プロパティ General Category (GC) East Asian Width (EAW) EAW = F or W だと全角。A は全角とプロポーショナルと両方の可能性がある文字。注意が必要。Na はプロポーショナル、N はアジア圏では通常使われないという意味 PropList.txt にあるプロパティ (Property) Script Decomposition Type Name の部分文字列(避けたい) 「普通の全角」の定義 「普通の全角」とは、 East Asian Width = W/F(全角)かつ Decomposition Type != <vertical> or <small> B: 前に空間を必要とする約物:始め括弧類の拡張 普通の全角かつ General Category = Ps (Open_Punctuation: an opening punctuation mark (of a pair)) 漏れてしまう文字 二つある。「U+2018 左シングル引用符」と「U+201C 左ダブル引用符」。これらのコードポイントは和文書体であってもプロポーショナルで実装されている。それ自体は合理的なことで、これらは英文で頻繁に使われる文字であるから、これらが全角になってしまうと、英文を作るのに使い物にならないフォントになってしまう。現状の和文書体の実装を追認する立場でも、U+2018/201C は cl-01 から外れる事になる。和文で使用するシングル、ダブル引用符をどうするかの議論が必要。 加わる文字 新規に下二つの文字が加わる。どれもEAW全角で、手元の環境ではグリフ前半に半角空白があり、クラス B に含めて問題がなさそうだが、要確認。 〈 U+2329 LEFT-POINTING ANGLE BRACKET 〚 U+301A LEFT WHITE SQUARE BRACKET A: 後ろに空間を必要とする約物:終わり括弧類と句読点の拡張 普通の全角かつ [ General Category = Pe (cl-02: Close_Punctuation: a closing punctuation mark (of a pair)) または PropList に Terminal_Punctuation がある (cl-06, 07) ] 漏れてしまう文字 B と同様、「 U+2018 右シングル引用符」と「U+201C 右ダブル引用符」が上記条件から外れる。B と全く同様の議論が当てはまる。 混入する他クラスの文字 上の条件で区切り約物 cl-04 と中点類 cl-05 の全角コロン、セミコロンが混入する。これらはどれも句読点と同様に文を区切る役割があり、約物の役割としては同一なので既存 Unicode プロパティで見分けることができない。cl-06, 07 を独特にしているのはアキの必要量だけだと考えられるので、これらを見分けるには、アキの必要量を示す属性が Unicode に必要なことになる。 加わる文字 新規に下三つの文字が加わる。どれもEAW全角で、手元の環境ではグリフ後半に半角空白があり、クラス A に含めて問題がなさそうだが、要確認。 〉 U+232A RIGHT-POINTING ANGLE BRACKET 〛 U+301B RIGHT WHITE SQUARE BRACKET 〞 U+301E DOUBLE PRIME QUOTATION MARK(終わりダブルミニュートに類似) BA: 両側に空間を必要とする約物:中点類の拡張 普通の全角かつ General Category = Po (Other_Punctuation) かつ [ PropList に Hypen がある(中点) または PropList に Terminal_Punctuation がある(全角コロン、セミコロン) ] 混入する他クラスの文字 A で述べたように上の全角コロン、セミコロンを捕まえる条件で cl-04 区切り約物、cl-05/06 句読点も捕まってしまう。これらを見分けるには、アキの必要量を示す属性が Unicode に必要。 S: そのものが空間な約物:和字間隔 属する文字は一文字なので U+2000 決め打ち。 J: アルファベットとの間に空間を必要とする文字 = 仮名や漢字 Unicode に拡張する場合、このクラスの定義はまだ柔らかい。漢字や仮名はここに所属することが明白だが、それ以外に議論の余地のある文字がある。J に入れない場合それらは O となるが、その影響は、欧文と間隔を作るか、および、空ける処理に使用できるか、の二点である。これらの文字をどうするかによって、PropList に Ideographic があるかどうか、Script = Han、および細かい調節、で拾うことができる。全て全角文字。 議論 ・漢字と交換して使われる記号をどうするかを考える必要がある。これらを入れる場合には、文字コード決めうちの例外となる。敏先生との会話によると〇と〓は入れたほうが良さそう。〇 は数字の十や百などと入れ替わる。〓 は漢字のないことを示すことが多い。〃 〆 は単独で使われることが多い。〼 は絵文字的なのでベタか? 〽 も絵文字的。 〃 U+3003 DITTO MARK 〆 U+3006 IDEOGRAPHIC CLOSING MARK 〇 U+3007 IDEOGRAPHIC NUMBER ZERO 〓 U+3013 GETA MARK 〼 U+303C MASU MARK 〽 U+303D PART ALTERNATION MARK ・偏や旁のブロックをどうするか。これらは文の中では使われることを想定しておらず、文中でで使われる場合には周りの文字と紛らわしくないように何らかの約物を伴って現れると思われる。とするとクラス O、ベタで良いか? ・契丹文字、西夏文字など全角かつ ideographic なものをどうするか。漢字と欧文との間に間隔が欲しい理由が文字のバランスだとすると、これらも入れるのが合理的な可能性がある。また、日本語のためのルールであることを考えると、日本語の中にこれらの文字が入る場合、文ではなく、偏や旁のように単独で使用されることが典型的であろう。そのような立場からは、ここに入れないのが合理的との議論もできる。Script=Han で除外できる。 F: 漢字類との間に空間を必要とする外国語文字 Unicode に拡張する場合のこのクラスの定義もまだ柔らかい。ラテンアルファベットだけに絞るか、他の言語の音を表す文字を一部、もしくは全て含めるか。漢字とアラビア文字やデヴァナガリやギリシャ文字が隣あった時に空間は必要かどうか。これをどう考えるかによって定義が異なってくる。文字は GC = Letter で拾うことができる。 G: 残り全て = どの文字ともベタ 上のどれでもないもの。全ての文字とベタ組となる。 ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
Attachments
- text/html attachment: stored
- image/png attachment: PastedGraphic-1.png

- image/png attachment: PastedGraphic-2.png
Received on Sunday, 1 August 2021 08:07:35 UTC