- From: Timothy Holborn <timothy.holborn@gmail.com>
- Date: Fri, 8 Mar 2024 07:50:11 +1000
- To: public-humancentricai@w3.org
- Message-ID: <CAM1Sok0k64DEO3x6dNVsw7jM9omWFTsVt3R_dc+ZE5sEW=J98g@mail.gmail.com>
Hi All,
This is an early note about an idea I'm working on, that I've called 'ADP'
for now.. I'm going to IETF brisbane, and as i've not done that before; i
thought, the best way to learn would be to think about an RFC...
The general gist of it, is that there's a RDF file on a domain that
provides directions.
The RDF file is somehow 'checkable' so that the consumer of it has
confidence that it has the same contents as the creator of it, intended.
My thinking is that this could be achieved by doing a checksum, and that
the checksum value can be stored in the TLS Certificate via an OID... I'm
open to suggestions otherwise... Below are some early notes about the
general idea....
There's a few different threads that have fed into the process of thinking
about this general idea.
1. i've been looking to figure out how to better support humanitarian ict
infrastructure, work & workers; therein, some crypto-apps (ie: web-wallets)
require users to share their addresses, which can be mixed up. it would be
easier if users just needed to remember each-others domains. This is
similarly the case also, for 'social web' related works - where i've been
looking at how to create a web-extension to support 'social web'
functionality into the browser, as a POC; which is then intended to be
developed further to look at how to better define personal & private
(local) Human Centric AI Agents...
2. thoughts about UN Global Digital Compact & related efforts; where, i
think there's a need to define humanitarian ICT services... I am mindful
of the use-case examples for 'refugee credentials', alongside recent
examples where internet has been turned-off (entirely, afaik) in conflict
zones; the means to ensure 'humanitarian services' are able to be supported
as an extension of IHL seems like a good thing to better support.
Noting also, in bandwith poor environments (ie: post natural disasters)
where choices need to be made, perhaps humanitarian ICT services need to be
prioritised over other options...
3. other use-cases - nb:
https://twitter.com/sotonWSI/status/1172458143428816896/photo/1
Overall, part of the underlying consideration is also about the 'web of
data', whereby the means for a library or other website (could be
wikipedia) to provide a sparql address or similar, is likely also part of
the commons data support requirements (not simply http(s), could also by
IPFS, & other DLTs, etc.); that in-turn support the means for a personal
'human centric ai' agent, to function.
but in the short-term, as a basic illustrator of 'smart domains' (personal
domain profile? subclass of 'agent discovery protocol?); I think it would
be helpful to be able to use a domain name as a high-level (personal)
identifier, as its memorable & computationally flexible; and, the method
SHOULD also be helpful for legal personalities, products and services...
similar, yet different to robots.txt or sitemap.xml; Therein, employing a
Trustworthy RDF document in the root of the domain that provides basic
information, is thought to provide an extensible pattern...
*Q: Does anyone know anything about OIDs[1]? *
OIDs can be searched: http://oid-info.com/index.htm they exist for
organisations, but i'm not sure about which to use for individuals...
("natural person"); noting, the method is intended to be used in relation
to a checksum value, so, maybe i just need to figure out which one to use
for the checksum..
Background.
To ensure the RDF document is the same as intended, I've been going through
different options of how to do so. atm, i' thinking the easiest method
might be to encode both the URI and the RDF File Checksum (perhaps also the
IP) into the TLS Cert; thereafter, the client then reviews the info in the
TLS Cert, gets the RDF document and compares the checksum. This can be
achieved through certbot and/or similar at the server-side...
NOTE:
1. This function is presently supported by Firefox but I'm not sure about
other browsers, yet...
2. Checksums don't easily go into TLS certs; so, the method is to refer to
them as a property of an OIDs.
so, there would be a SAN[2] that provides the OID (for an organisation or
natural person or simply a 'checksum' of the RDF/'ADP' file ie:
http://oid-info.com/get/1.3.112.4.59 ), to provide the checksum of the RDF
file.
3. If the user changes the document, they've got to regenerate the
certificate.
But, I'm not sure what the best OID is for individuals (personal domain
ownership), if the OID method is defined in that way?
IF there's a better method, I welcome the input - or if this is considered
to be a flawed idea for some reason, then constructive criticism is
welcomed also....
some notes are otherwise provided below;
ACKNOWLEDGEMENT: The RDF file is not unlike WebID[3]; but there's some
differences in my thinking, so I'm NOT presently proposing it AS WebID.
Where appropriate, the ADP protocol would in-turn provide a means to
provide the POD address that provides a WebID (perhaps, after AUTH); but
also, there's a number of use-cases for organisations; and I was also
thinking, that perhaps also a subclass concept for 'personal intelligent
domains' or Personal Domain Profile (given there's lots of PIDs already),
that i thought was overall different to WebID? Thoughts & Feedback is
welcomed... .
PURPOSE OF THE RDF File (calling it an ADP file atm - 'agent discovery
protocol')
For organisations in particular; the RDF document could also contain links
to credentials that could be issued to organisations, as well as
information provided simply by the organisation; some thoughts are,
- '*humanitarian ICT*' sites; which then, could be used to prioritise the
availability of those websites over others (if there's a need to make a
choice).
- '*age appropriate*' information; could be used to improve protections for
children.
- '*validation*' provides support for other software to check if the link
(ie: in an email, etc) is actually from the bank or government site, it
claims to be from... (based on the domain + verifiable claim / credential).
The method could also help with various other AI / LLM use-cases, as
providing the domain of a source is relatively simple (and short); but, I
haven't fully explored all the use-cases yet... the means to provide
schemaorg and/or similar is also considered to be fairly straight-foward..
but the hard bit is the 'human centric' constituencies...
*For individuals / Natural Persons;*
The purpose of this tool, for natural persons; would be to define the
domain as a personal or family domain (ie: natural persons) (which may
also, thereby, be granted different priority in case of emergency). I have
also thought that it may have many beneficial use-cases relating to support
for children in particular, whereby the identifier may be a subdomain of
the family domain; but, this is yet to be more fully explored... similarly
also, various use-cases relating to changes in people's personal lives,
etc... nonetheless,
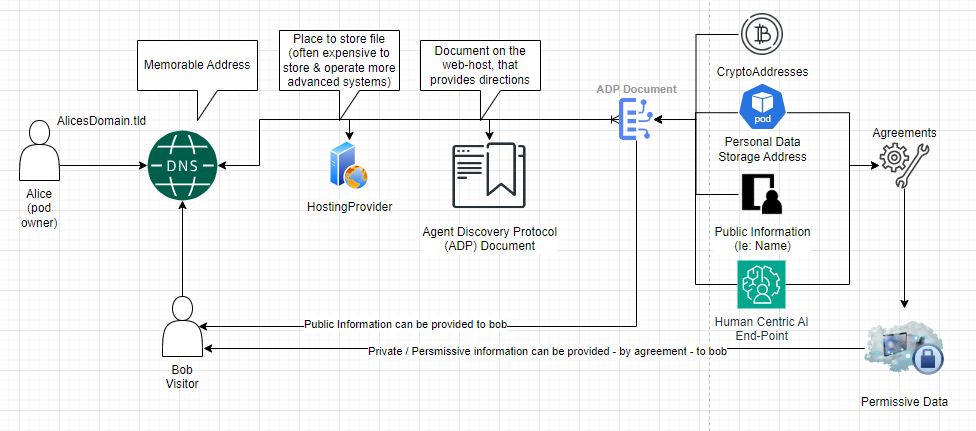
*The RDF file would contain the very basic, public information only.*
Basically provide the 'open' information (ie: crypto accounts, POD Address,
even graph.facebook.com/[myuserid] endpoint, etc.) such as to provide the
URIs of a persons (bob) 'APIs'; that then in-turn provides a means for the
user (bob) to seek permission from 'alice' to get more information (ie:
personal info, etc.); but that, the 'root' identifier that the user would
need to remember in these examples, is the domain name...
[image: 2024-03-02_diagram-2.png]
That way, a user can update their details / pod providers, etc... and, so
long as their network still has the correct domain name, discovery is still
achievable. This in-turn, provides a means to use a domain as the primary
identifier for a person (ie: mydomain.tld), to discover the service
locations associated to that user (ie: mypodprovider.tld/mypodaddress, or
whatever their 'bitcoin' or 'xec' address is, etc. ), which may in-turn
change overtime.
Design considerations / thoughts;
1. I'm trying to keep it as simple as possible, therefore lowering the cost
(ie: could be done by a registrar even if the user doesn't have a more
expensive 'web hosting' service)
2. There are other issues relating to 'social web' support, thought to be
important enablers for 'human centric ai' services that are thought to be
related issues - but thought best kept separate at this stage? at least,
for the purpose of any IETF RFC considerations... or is this a mistake?
Therein; CORS[4] considered to be one of the bigger issues; as RWW [5]Apps
(ie: cimba[6][7] or even the people example of rdflibjs[8]) use to work in
the browser (ie: locally) but now need online hosts, to, in-effect, power
decentralised apps... IF there was a very low-footprint set of tools for
'social web' (web 3.0) enablement (as to support human centric ai); then, i
think designs should try to keep the costs as low as possible (ie: LAMP
shared hosting account); also,
- important to ensure computing still works even when the computer is
offline.
- ideally, the 'human centric ai' agent operates locally - and the POD
provider doesn't need to be queried for everything, all the time... but is
the online 'host' / back-up service, et.al. (therein, local caching, on
personal devices, in-effect).
- there's 'social web' related considerations, such as the means to assign
'email alias' to relationships; which can change the way email works (ie:
not me@emailprovider.tls but rather myfriendalias@mydomain.tld ) that is an
idea thought useful in seeking to address various problems... but that
also, there's various 'personal directory' challenges (relating also, to
nuance of social ai predicates), whereby overall; strengthening 'personal
domain ownership' is thought to be 'usefully beneficial' for various
reasons.
3. The word 'identity' has many meanings.. I generally prefer the older
'pre-web' meanings, noting the difficult problems sought to be addressed by
human centric AI works; relate to the n-dimensionality of 'human identity',
socially... furthermore, this is not intended to be an Authentication
Service, rather, moreover a discovery method.
The notion is similar to FOAF (atm: https://xmlns.com/foaf/0.1/ looks like
its down?), but in consideration of privacy / personal safety related
considerations; the belief is, that the RDF file should only really provide
the minimal information needed to validate whether its the domain of the
intended party; and, then direct the user to links contained in the RDF
file, that thereby provide 'agreements' based access, should that be
desired by the parties.. thereafter, more information would be provided by
the permissive online data service (ie: a solid / mydata pod), based upon
what they want to share...
4. Smart Homes / Web of Things / IPv6, etc...
Its entirely likely that people will WANT some sort of home-based AI
device, for 'smart homes', etc... as may in-turn, end-up being managed via
a sub-domain or a persons - personal domain..
Overall, I think there's a few differences to WebID / Foaf; although, I
think it's complimentary.. AND, fairly extensible..
5. other
*ONTOLOGY*
Yes, the view would be to define an ontology for it... I wanted to solve
some of these puzzles before making a note of the concepts / ideas on the
list, but wasn't sure about the 'OID' thing; so, here's an earlier note
than intended... Indeed also, I haven't had any feedback on it; maybe it's
not a very good idea for some reason, idk.. but, I figured that the IETF
part was more about the protocol layer than the ontology layer - whilst
knowingly interactive..
*Human Centric Internet*
There's been some talk about a 'human centric internet'... maybe, this
sort of thing is a stepping stone towards that; as may then be integral for
the growth of 'human centric ai' agents... therein also, if the 'social
web' interactions are based upon a users privately owned domain; then, its
kinda clear that the interaction is between two natural persons - rather
than between 'agents' of an organisation (ie: differentiating between
'natural persons' and 'employee' & related 'agency' considerations),
whether involving 'consumers' or natural persons in their private
capacities, or otherwise. herein, one of the more difficult challenges has
always been how to support the needs of natural persons...
Perhaps this might be helpful?
*Agreements*
I'm an advocate for 'agreements' methods to be defined to provide the means
for people to manage their own social relationships by negotiation between
the parties involved; rather than mandates, or 3rd party platform mediators
(such as social media silos) being REQUIRED between all human
relationships. But i think this requires "PODs" or similar.
*PODS*
There are various 'mydata' / POD solutions, and I think much of the RWW /
Solid works, are fairly close to systems already in-place (under the hood)
by a number of existing, large platforms... I personally believe TimBL will
deliver the foundational works required to provide 'social security' /
'digital prison', 'foundational standards' required - as an
interoperability (& portability) spec, to support human rights[9] no matter
the circumstances of the person.. BUT, The challenge is also, in seeking
to produce a method that can be used to support many different types of
systems, and the means to declare which system a user uses... a bit like
different web-browsers...
SO, that might end-up with something like,
:myDataService a :StorageService ;
:serviceName "MyData Storage" ;
:hasProvider :myDataOrg ;
:hasVersion :v1_0 ;
:hasFunctionality :fileStorage, :dataSharing ;
:hasTermsOfService <https://mydata.org/terms> .
(adding the users endpoint URI).
or
a adp:Agent, adp:DataStorageService ;
dct:description "My Personal PDS" ;
adp:dnsDomain "storage.ap.inrupt.com" ;
pds:storageType pds:PersonalDataPod ;
adp:dataLocation <
https://storage.ap.inrupt.com/b436b6a9-9c4c-45bc-9d22-d1b068e84992/> ;
pds:WebID <https://id.inrupt.com/ubiquitous> ;
pds:accessControlPolicy <https://mypod.com/policy.ttl> ;
noting also; that these considerations also extend to various ways in which
organisations may also use the function, where 'pod' like services may then
be integrated into their systems also...
Presently, the investigation is moreover, about considering if / how,
something like this might be usefully defined as an IETF RFC (if at all);
and then, whilst OIDs exist for organisations, i am particularly wondering
how to address the functional requirements for individuals (natural
persons) IF this method is considered usefully appropriate...
Finally, I'm going to IETF119[10] if anyone else is attending, and is
interested in meeting in person - let me know...
as noted, this is considered an experimental idea atm... Feedback
welcomed! but i've not got any feedback, so, it's just work done in
isolation until now... still working on the docs / tests / etc... The
general method has gone through a few iterations, earliest considerations
having been made several years ago; but not really considered in more
detail, until recently.
Timothy Holborn.
[1] https://en.wikipedia.org/wiki/Object_identifier
[2] https://en.wikipedia.org/wiki/Subject_Alternative_Name
[3] https://www.w3.org/wiki/WebID
[4] https://en.wikipedia.org/wiki/Cross-origin_resource_sharing
[5] https://www.w3.org/community/rww/
[6] https://www.youtube.com/watch?v=IhwAiTOFPrc
[7] https://github.com/linkeddata/cimba/
[8] https://github.com/linkeddata/rdflib.js/tree/main/example/people
[9] https://www.youtube.com/watch?v=pRGhrYmUjU4
[10] https://www.ietf.org/how/meetings/119/
Attachments
- image/png attachment: 2024-03-02_diagram-2.png
Received on Thursday, 7 March 2024 21:50:58 UTC