- From: Nolf Geraldine <geraldine.nolf@kb.vlaanderen.be>
- Date: Fri, 23 Jun 2017 08:41:47 +0000
- To: "public-dxwg-wg@w3.org" <public-dxwg-wg@w3.org>
- Message-ID: <VI1PR0902MB2045C9135B25A0309D3A7CE7A6D80@VI1PR0902MB2045.eurprd09.prod.outlook.>
Hello all,
I am Geraldine Nolf, expert in metadata for geospatial information for Informatie Vlaanderen, in Flanders Belgium – especially ISO & INSPIRE standards on metadata.
I am relatively new to the DCAT-world and this working group as well, but I think I can give useful information about your questions on versioning, and tell you how we do this in geo-world.
I hope this brings in some good “best practices” of other domains, that can be helpful in the general open data world as well.
1/
Everything starts with a good defined “product”.
- What are you going to make?
- Which data is it?
- How is its provenance: when is the object the same, when is it a new one, do you keep history in the data set or only the effective objects, …?
- Why do you make it? What’s the goal?
==> If you define your product from the beginning in the right way, stable for a long-term, then versioning is more easy.
To define such a product, we use the ISO-standard of data product specification: https://www.iso.org/standard/36760.html
And we describe every product we make / release with product specifications conform that ISO19131-standard.
So the rules are clear. (And they can differ from one product to another.) Here you define product by product the “core characteristics”.
2/
But besides this standard, we also use the ISO-standard for Feature cataloguing (19110): https://www.iso.org/standard/39965.html
In a Feature catalogue you define the used “model”: the used attributes, their domains, cardinality, … And this specification determines too whether it is still the same dataset, or with more or less attributes, it is another dataset.
As long as the model is the same, it is the same product. If the model changes, than we speak about another product.
INSPIRE did the same for its data themes. There are specifications for every data set you need to deliver to INSPIRE, with an existing model.
3/
The next step is how you want to distribute that product to the public.
You can publish the data continuously. Every change is within the next second public for viewing, downloading, … Then we advise to chance the existing metadata of that dataset. There is only one metadata record, and you always have the most recent version of the data if you view or download it.
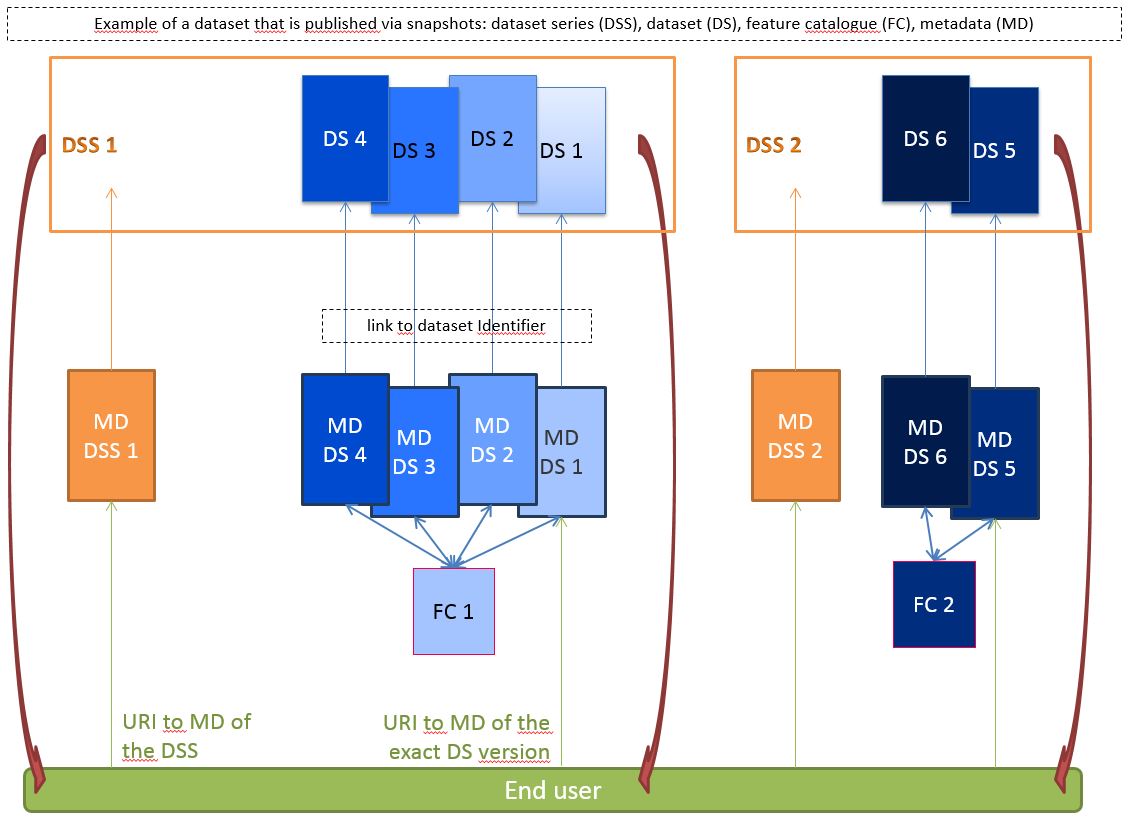
On the other hand, when you have data that is changing (even continuously) but you only foresee snapshots to the public, for example once a week, once a month, 4 times a year, annually, … then you need to create a duplicate of the existing metadata (with an own identifier).
In the duplicate metadata record you have to change those metadata elements that are different (for example the version, the period of validation, the metadata date of change, the coverage, …). And we advise as well to foresee lineage information: what is new in this version, in comparison to the previous version. So your users know exactly what to expect.
As a data provider you can choose to de-publish the older versions (because it is necessary the only can find the latest version – for legal reasons for example), or you can choose to keep all the versions published.
That way there is a metadata record of all the published versions; and users can look-up details of each version, compare them, …
This way too, you can foresee corrections of versions. If a data provider made a mistake in the previous version (he accidently published half his dataset), but this version was published (and viewed or downloaded by the public). Then the next version has a new metadata record describing what is corrected. And this way he can communicate about the previous and new version of the data.
And that way you are able to distinguish versions of one dataset as an end user.
When your data model changes (the feature catalogue – or thus, the data product specification); then it is in any case a new metadata description. Even for continuously managed data.
4/
Then, the concept of dataset series is very useful to group all datasets with the same feature catalogue – and thus the same data product specification. That way you can keep the overview in a catalogue, for example.
The ISO 19115 says that datasets with the same product specification can be grouped in a dataset series. (As a dataset you have max. 1 parent, a dataset series.)
In the dataset series you can order then all the metadata records by date for example. You can view only the latest, or you can view them all to compare the changes over years for example.
5/ Last but not least,
I suppose I don’t have to mention that unique identifiers are crucial in our practices.
To conclude, I attached an overview of all those concepts, because sometimes visuals work better than text.
Kind regards,
Met vriendelijke groeten,
Geraldine Nolf
Productmanager Metadata en ViaAGIV
Afdeling Gegevens- en dienstenintegratie
INFORMATIE VLAANDEREN
T 09 276 16 10
geraldine.nolf@kb.vlaanderen.be<mailto:geraldine.nolf@kb.vlaanderen.be> OPGELET: mijn nieuwe e-mailadres is geraldine.nolf@kb.vlaanderen.be<mailto:geraldine.nolf@kb.vlaanderen.be>. E-mails naar @agiv.be gaan vanaf 10 juli verloren.
Boudewijnlaan 30, 1000 Brussel
Koningin Maria Hendrikaplein 70, 9000 Gent
www.vlaanderen.be<http://www.vlaanderen.be/> | www.agiv.be<http://www.agiv.be/> | www.geopunt.be<http://www.geopunt.be/>
Stel je vraag aan de overheid!
Bel gratis 1700 of surf naar www.vlaanderen.be<http://www.vlaanderen.be/>
//////////////////////////////////////////////////////////////////////////////////
[cid:image001.png@01D11E34.D603F010]
From: D'Haenens Thomas [mailto:thomas.dhaenens@kb.vlaanderen.be]
Sent: vrijdag 23 juni 2017 8:32
To: public-dxwg-wg@w3.org
Subject: Re: Question for DCAT "experts"
Hi Makx (I love these kind of dicussions),
At the top level, no. If you go a bit deeper (maybe one or two levels) you get a much more rich and interoperable classification solution. And if I remember correctly, UDC provides a means of combining lower themes to describe complex items (eg a dataset of public transport infrastructure and the expenditure of it could be classified in MDR 'Transport' as well as 'Government and Public Sector' - I don't know how deep MDR goes; have to check that). In UDC, this is also true, but you could use (using proxy values here; don't know it by heart) transport:public expenditure. It's also designed to be machine-readable. Making it compatible with semantic technologies... (dreaming now).
Anyhow, I think a controlled vocabulary of the magnitude we're thinking about here is way beyond the scope of this WG. But it might be a thought of simply adding an (optional) structural element in DCAT (on a meta-level) describing the link to an online ontology (eg within the class 'Concept' - something like 'Provenance') so a crawler could use that linkable item to enhance retrieveability. And an end-consumer could overcome babylonic confusion if the ontology in question is interlingual. Etc...
Thomas
Op 23 jun. 2017 om 08:02 heeft Makx Dekkers <mail@makxdekkers.com<mailto:mail@makxdekkers.com>> het volgende geschreven:
Hi Thomas,
No problem, I come from a library background too 😉
UDC is indeed an interesting example. It is based on sensible principles, dividing the concept space into a small set of top concepts, then drilling down into more detail. However, it’s really a domain-specific classification, used mostly by libraries and related institutions, and there have been many initiatives to create a global, domain-independent classification (e.g. BSR http://www.ubsr.org/, UDEF http://www.opengroup.org/udefinfo/htm/en_defs.htm, recently O-DEF http://www.opengroup.org/subjectareas/platform3.0/o-def). One common characteristic of all those initiatives is that they start out with a small number of top concepts, relevant for a particular domain, and then go into the detail where things tend to go wrong.
Looking at the top level of UDC, I am not quite sure that those 10 categories are more relevant for the classification of datasets than the 13 terms in the MDR Data Theme vocabulary. I honestly think they are not.
The main question, if we should decide that we need to create or select a global theme vocabulary, is whether this group or W3C itself should be in the business of creating, maintaining, and recommending such a set of themes, and maybe other controlled vocabularies for other properties. The original development of DCAT by the GLD did it on one aspect, as it recommended the use of the official URIs for languages (ISO 639-1 and 639-2) for dct:language.
So, I think we should decide whether this group should try to establish controlled vocabularies for some of the properties in DCAT or not.
Makx.
From: D'Haenens Thomas [mailto:thomas.dhaenens@kb.vlaanderen.be]
Sent: 22 June 2017 21:11
To: public-dxwg-wg@w3.org<mailto:public-dxwg-wg@w3.org>
Subject: Re: Question for DCAT "experts"
Makx (please don't take this critique personal cause it is not in any way),
While this is indeed the way we need to go ahead and I really admire the energy and zeal excercises like this take (and believe me, I know), I must say on a personal note that I have serious questions about how theme vocabularies like this are conceived.
How can one expect true interoperability (and then I'm talking on a global scale with maximal return and minimal noise in queries) if we're defining clustered themes as the grain of our vocabularies.
As a librarian (again) I grew up with something like the UDC-system (you should check it out at http://www.udcc.org - btw conceived by two Belgians - Otlet and La Fontaine :-)) and while this is probably way too complex in our context, we might learn a thing or two from the old and mysterious world of the library...
We (in the Flemish government) have exactly the same problem we're slowly starting to solve. Every domain creating their own list of (clustered) themes, contradicting each other and creating massive noise when sharing data(sets).
Since these themes are really universal (at least global), maybe we could discuss adhering to the high-level classes of the UDC (just a random tought here...). This might go well beyond the scope of this WG though.
Thomas
_____________________________
From: Makx Dekkers <mail@makxdekkers.com<mailto:mail@makxdekkers.com>>
Sent: donderdag, juni 22, 2017 8:37 PM
Subject: RE: Question for DCAT "experts"
To: <public-dxwg-wg@w3.org<mailto:public-dxwg-wg@w3.org>>
I fully agree that a common Theme vocabulary would greatly help interoperability. This is exactly what was done for the European DCAT Application Profile: this makes the use of the MDR Data Theme vocabulary (http://publications.europa.eu/mdr/authority/data-theme/) mandatory for catalogues that want to take part in the European infrastructure for public sector datasets.
The MDR Data Theme vocabulary is an open and online set of terms which could serve as an example for wider usage.
Makx.
From: D'Haenens Thomas [ D'Haenens Thomas [mailto:thomas.dhaenens@kb.vlaanderen.be]
Sent: 22 June 2017 19:31
To: public-dxwg-wg@w3.org<mailto:public-dxwg-wg@w3.org>
Subject: Re: Question for DCAT "experts"
We should be carefull not to get things mixed up (I like it all to be quite modular).
When I talk about core characteristics (and what I didn't mention before), I try to do so on two levels :
- a meta-level, defining eg the structure of the dataset
- a contentual level, denoting an intrinsic value within the dataset
That last one is actually one of my biggest concerns with DCAT. The level in which content is taken into account is not enough (my small personal opinion, mind :-)). Theme (as skos:concept which is a very abstract notion of an idea) and themeTaxonomy (as an instance of skos:conceptScheme) may be semantically correct and SHACL-proof etc but for me (as a librarian myself) much of the potential richness and interoperability just goes to waste with this abstract notion of contentual description. I might be mistaken (so correct me if I'm wrong) but I can't find a guideline or a recommendation stating eg to use an open and online ontology within the dataset's domain (and not just your local thesaurus or list). Only mentioning that would go a long way. Adding this ontology/term-URI (with their own metadata) as part of the Theme-object in DCAT would take us like lightyears ahead if globally applied.
Thinking further on the core-thing....
Adding a field to a dataset (or a chapter in a book, or a mergure of two organisations) changes the fabric, the nature itself of the object. Hence creating a new instance of it.
Changing the content of the dataset also changes the value of it (to whomever its worth may be applicable).
Within the realm of one instance, one can diversity to the level of version. That's to say not touching the core we defined (on those two levels). Implications are :
- adding data (not changing existing data) results in a new version within a given dataset (new date of publishing, ...)
- changing data results in a new dataset
- changing a relation (in terms of high-level ERD) from a dataset to another class (eg the URL to download the dataset changes domain) doesn't change the instance neither the version - only the relationship to the appropriate 'channel' gets updated
Taking your example, when the creator of the dataset updates the data in place it actually becomes a new dataset (since the contentual core fabric gets broken). Thus the article really relates to an instance of a dataset that isn't there anymore. We should be able to formalise that change somehow. The creator of the dataset should be aware that by doing this change, he/she really creates a new dataset. If that person chooses not to preserve the old one, he/she actually states "I don't want this dataset to be interoperable anymore" (which can be perfectly legitimate in its proper context).
Let's take a look at legislation. Laws are being changed all the time. Yet it's crucial to be able to return to a law at any given time in the past. The ELI-initiative eg (http://eur-lex.europa.eu/legal-content/EN/TXT/?uri=URISERV%3Ajl0068) is aiming at preserving/defining that one legal truth at one point in time.
I'm probably straying too far right now :-), but I hope you'll catch some of my figments.
Cheers,
Op 22 jun. 2017 om 18:32 heeft Makx Dekkers <mail@makxdekkers.com<mailto:mail@makxdekkers.com>> het volgende geschreven:
Thomas,
I like your view that you can think of a dataset as having some ‘core’ characteristics – if those change, you have a new dataset, otherwise you might just update ‘in place’, with ideally some indication of the changes that were made. Or would you still keep both ‘versions’ online?
Now the challenge is of course to define those ‘core’ characteristics of a particular dataset. Is it the creator/publisher’s view, or should it also include the perspective of a (re)user?
For example, consider the case of an academic who writes a critical article about an error that he/she found in a published dataset. The article will include a link to the dataset. If the creator of the dataset then updates the data ‘in place’ to correct the error, all of a sudden, the critique is broken.
How to make sure that those things don’t happen?
Makx.
From: D'Haenens Thomas [mailto:thomas.dhaenens@kb.vlaanderen.be]
Sent: 22 June 2017 17:19
To: public-dxwg-wg@w3.org<mailto:public-dxwg-wg@w3.org>
Subject: RE: Question for DCAT "experts"
Hi Peter, all,
I think this is a very general discussion. When do we have a new instance of something and when are we talking about another version/instance.
In my experience, there isn’t a magic solution.
When it comes to organizational dynamics, I usually rely on the formal regulations that give birth to a change. Especially in the public sector, one normally has a decree/law, an organizational decision or some kind of formal document.
In a classic physical (printed/written) work, you have editions, versions, and the like. I believe a dataset isn’t so different.
I believe clarity is crucial.
IMHO, first of all, at the heart of things we have to decide what really identifies a concept, let’s say a dataset. We omit anything that’s not crucial. (‘what is core’) When that core changes, you have a new dataset (with a new identifier).
When the core stays intact, but something around it changes (lastUpdated, publishedBy, …), we define a new life phase of the object (a ‘version’ of an instance).
Starting from that core we have many relations to other things.
Relating to other classes implies we have both a history on the part of the class and on the part of the relationship. The same goes for circular relationships (organisations, services, datasets can be ‘adopted’ in their child-parent-relationship).
So, eg. the structure of a dataset changes (and we could have decided the structure is a critical element of a dataset), that implies we have a new instance. Data is added to a dataset – with no structural changes – it’s simply a new version with some metadata that changed.
To go a step further, in the spirit of any base registry, you enable keeping track of history on any relationship and on any class. Then, within any implementation, you choose what to capture (and you are aware what you don’t capture).
Taking it back to classic printed books, a 4th edition of Goethe’s Faust isn’t a new instance with regards to the 3rd ed. It’s simply a new version. You could as easily rebind the book, creating also a new version.
The some goes, as said, for organizational dynamics, …
Always happy to have some discussion regarding this topic☺.
Cheers,
Thomas
From:Peter.Winstanley@gov.scot<mailto:Peter.Winstanley@gov.scot> [mailto:Peter.Winstanley@gov.scot]
Sent: donderdag 22 juni 2017 16:37
To: andrea.perego@ec.europa.eu<mailto:andrea.perego@ec.europa.eu>
Cc: marvin.frommhold@eccenca.com<mailto:marvin.frommhold@eccenca.com>;martin.bruemmer@eccenca.com<mailto:martin.bruemmer@eccenca.com>; makx@makxdekkers.com<mailto:makx@makxdekkers.com>; kcoyle@kcoyle.net<mailto:kcoyle@kcoyle.net>;david.browning@thomsonreuters.com<mailto:david.browning@thomsonreuters.com>;public-dxwg-wg@w3.org<mailto:public-dxwg-wg@w3.org>
Subject: RE: Question for DCAT "experts"
Thanks for pointing this out Andrea … it certainly could be helpful. Although this is something that crops up frequently in the spatial data world, you’ll see from the school illustration that I gave that it is a regular occurrence in organisational dynamics too.
From:andrea.perego@ec.europa.eu<mailto:andrea.perego@ec.europa.eu> [mailto:andrea.perego@ec.europa.eu]
Sent: 22 June 2017 15:15
To: Winstanley FP (Peter)
Cc: marvin.frommhold@eccenca.com<mailto:marvin.frommhold@eccenca.com>;martin.bruemmer@eccenca.com<mailto:martin.bruemmer@eccenca.com>; makx@makxdekkers.com<mailto:makx@makxdekkers.com>; kcoyle@kcoyle.net<mailto:kcoyle@kcoyle.net>;david.browning@thomsonreuters.com<mailto:david.browning@thomsonreuters.com>;public-dxwg-wg@w3.org<mailto:public-dxwg-wg@w3.org>
Subject: RE: Question for DCAT "experts"
Hi, Peter.
> the other provenance pattern that we have which is tricky relates to things like property
> or schools or fields (land parcel units) where we see splitting or clumping and so the
> update involves new entities that can include the old one (e.g. one house gets split into
> two. The identifier for the old house is retained, but it now contains two new houses. It
> is possible that at some later date the two are joined back into one. Same happens with
> schools, fields and so on) I really don’t know the best practice for this and would
> appreciate a side discussion if anyone’s interested.
Just to note that this issue – versioning of the things being described by data – was subject to discussion in the Spatial Data on the Web WG, and it is addressed by a specific Best Practice (BP11):
https://www.w3.org/TR/sdw-bp/#desc-changing-properties
I wonder whether this BP could provide some guidance.
Andrea
----
Andrea Perego, Ph.D.
Scientific / Technical Project Officer
European Commission DG JRC
Directorate B - Growth and Innovation
Unit B6 - Digital Economy
Via E. Fermi, 2749 - TP 262
21027 Ispra VA, Italy
https://ec.europa.eu/jrc/
----
The views expressed are purely those of the writer and may
not in any circumstances be regarded as stating an official
position of the European Commission.
From:Peter.Winstanley@gov.scot<mailto:Peter.Winstanley@gov.scot> [mailto:Peter.Winstanley@gov.scot]
Sent: Thursday, June 22, 2017 4:04 PM
To: david.browning@thomsonreuters.com<mailto:david.browning@thomsonreuters.com>;public-dxwg-wg@w3.org<mailto:public-dxwg-wg@w3.org>
Cc: marvin.frommhold@eccenca.com<mailto:marvin.frommhold@eccenca.com>;martin.bruemmer@eccenca.com<mailto:martin.bruemmer@eccenca.com>; makx@makxdekkers.com<mailto:makx@makxdekkers.com>; kcoyle@kcoyle.net<mailto:kcoyle@kcoyle.net>; PEREGO Andrea (JRC-ISPRA)
Subject: RE: Question for DCAT "experts"
the other provenance pattern that we have which is tricky relates to things like property or schools or fields (land parcel units) where we see splitting or clumping and so the update involves new entities that can include the old one (e.g. one house gets split into two. The identifier for the old house is retained, but it now contains two new houses. It is possible that at some later date the two are joined back into one. Same happens with schools, fields and so on) I really don’t know the best practice for this and would appreciate a side discussion if anyone’s interested.
From:david.browning@thomsonreuters.com<mailto:david.browning@thomsonreuters.com> [mailto:david.browning@thomsonreuters.com]
Sent: 22 June 2017 15:00
To: Winstanley FP (Peter); public-dxwg-wg@w3.org<mailto:public-dxwg-wg@w3.org>
Cc: marvin.frommhold@eccenca.com<mailto:marvin.frommhold@eccenca.com>;martin.bruemmer@eccenca.com<mailto:martin.bruemmer@eccenca.com>; makx@makxdekkers.com<mailto:makx@makxdekkers.com>; kcoyle@kcoyle.net<mailto:kcoyle@kcoyle.net>;andrea.perego@ec.europa.eu<mailto:andrea.perego@ec.europa.eu>
Subject: RE: Question for DCAT "experts"
Yes, we have that pattern/behaviour/feature too. Generally we support that by retaining a history of changes within the data that’s being exchanged – its sometimes important to know that you were wrong (or misinformed) so you can explain the decision you made..... That does risk it getting very complex and probably domain specific.
· · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · ·
David Browning
Platform Technology Architect
Thomson Reuters
Phone: +41(058) 3065054
Mobile: +41(079) 8126123
david.browning@thomsonreuters.com<mailto:david.browning@thomsonreuters.com>
thomsonreuters.com<http://thomsonreuters.com/>
From:Peter.Winstanley@gov.scot<mailto:Peter.Winstanley@gov.scot> [mailto:Peter.Winstanley@gov.scot]
Sent: 22 June 2017 15:45
To: Browning, David (TRGR); public-dxwg-wg@w3.org<mailto:public-dxwg-wg@w3.org>
Cc: marvin.frommhold@eccenca.com<mailto:marvin.frommhold@eccenca.com>;martin.bruemmer@eccenca.com<mailto:martin.bruemmer@eccenca.com>; makx@makxdekkers.com<mailto:makx@makxdekkers.com>; kcoyle@kcoyle.net<mailto:kcoyle@kcoyle.net>;andrea.perego@ec.europa.eu<mailto:andrea.perego@ec.europa.eu>
Subject: RE: Question for DCAT "experts"
In the statistical areas we have lots of the ‘more data’ situation (all these longitudinal datasets) but sometimes (e.g. with pupil statistics where there can be an exam result that on appeal gets adjusted in grade) the ‘more data’ can be accompanied by a revision of what was previously there
From:david.browning@thomsonreuters.com<mailto:david.browning@thomsonreuters.com> [mailto:david.browning@thomsonreuters.com]
Sent: 22 June 2017 14:39
To: public-dxwg-wg@w3.org<mailto:public-dxwg-wg@w3.org>
Cc: marvin.frommhold@eccenca.com<mailto:marvin.frommhold@eccenca.com>;martin.bruemmer@eccenca.com<mailto:martin.bruemmer@eccenca.com>; makx@makxdekkers.com<mailto:makx@makxdekkers.com>; Winstanley FP (Peter); kcoyle@kcoyle.net<mailto:kcoyle@kcoyle.net>; andrea.perego@ec.europa.eu<mailto:andrea.perego@ec.europa.eu>
Subject: RE: Question for DCAT "experts"
In my experience, this scenario – where a data publisher makes available a sequence of update files that encode incremental changes from some initialising “complete” publication – is the pre-dominant pattern of data exchange in the financial information domain (outside the streaming/realtime data delivery) so it’s one that we’re extremely interested in. We’d like to be able to leverage DCAT as much as possible though clearly we may be extending into a more specialised vocabulary beyond what’s appropriate for inclusion in the DCAT standard itself. As an example, we’d like to be able to automatically process the sequence of files by using the metadata as configuration information so that a data consumer could create a local replica of the latest state of the published data. Our current thinking actually aims to handle this at the dct:Distribution level – though this is still active work and we haven’t yet settled on a definite approach.
As Andrea says, from a data consumer’s perspective, there’s some kind of link here with how service-based access might be modelled, since in my experience that’s often used to give access to a ‘latest state/current value’ copy of the data. [Of course, that might not be the direction the WG takes....]
So I’d like to see this considered as a potential use case for discussion till we have a fuller understanding of the landscape.
Last comment: we tend to think of this kind of change - “more data” – as somewhat distinct from version changes. A version change typically indicates something potentially more disruptive to a consumer than an update file. And, yes, there is some ambiguity in that distinction – but in practice it’s been a useful distinction in our environment.
· · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · ·
David Browning
Platform Technology Architect
Thomson Reuters
Phone: +41(058) 3065054
Mobile: +41(079) 8126123
david.browning@thomsonreuters.com<mailto:david.browning@thomsonreuters.com>
thomsonreuters.com<http://thomsonreuters.com/>
From:andrea.perego@ec.europa.eu<mailto:andrea.perego@ec.europa.eu> [mailto:andrea.perego@ec.europa.eu]
Sent: 22 June 2017 14:15
To: public-dxwg-wg@w3.org<mailto:public-dxwg-wg@w3.org>
Cc: marvin.frommhold@eccenca.com<mailto:marvin.frommhold@eccenca.com>;martin.bruemmer@eccenca.com<mailto:martin.bruemmer@eccenca.com>; makx@makxdekkers.com<mailto:makx@makxdekkers.com>; Peter.Winstanley@gov.scot<mailto:Peter.Winstanley@gov.scot>;kcoyle@kcoyle.net<mailto:kcoyle@kcoyle.net>
Subject: RE: Question for DCAT "experts"
I think it may be worth considering whether the scenario outlined by Karen ("incremental updates"?) relates also to the notion of dcat:Distribution. In particular, for the mechanism used to for synchronising data version, I see some relationship with the use cases concerning the modelling of service-based data access.
Andrea
----
Andrea Perego, Ph.D.
Scientific / Technical Project Officer
European Commission DG JRC
Directorate B - Growth and Innovation
Unit B6 - Digital Economy
Via E. Fermi, 2749 - TP 262
21027 Ispra VA, Italy
https://ec.europa.eu/jrc/<https://urldefense.proofpoint.com/v2/url?u=https-3A__ec.europa.eu_jrc_&d=DwMGaQ&c=4ZIZThykDLcoWk-GVjSLmy8-1Cr1I4FWIvbLFebwKgY&r=SX6sxEGBIuiEtjQTAWz7jTpuOC0f5DcH79errOWxM8RN6gOsHdAxWfl9GTTkalJj&m=HNtxqmdvLjHJ6tDtUN0D71McOaqYoN3CtITnvzqcPmg&s=VFZ5l54iFiCMEum8wIpiZSpB2JHnIMQ7MRrSEdMlAiw&e=>
----
The views expressed are purely those of the writer and may
not in any circumstances be regarded as stating an official
position of the European Commission.
From: Martin Brümmer [mailto:martin.bruemmer@eccenca.com]
Sent: Thursday, June 22, 2017 11:35 AM
To: public-dxwg-wg@w3.org<mailto:public-dxwg-wg@w3.org>
Cc: Marvin Frommhold
Subject: Re: Question for DCAT "experts"
Hi there,
a colleague of mine, Marvin Frommhold, is researching versioning in the context of RDF and Linked Data. He contributes the following points:
The following two documents provide a basic introduction to versioning of datasets:
* Papakonstantinou, Vassilis et al. “Versioning for Linked Data: Archiving Systems and Benchmarks.” BLINK@ ISWC. users.ics.forth.gr, 2016. Web.<https://urldefense.proofpoint.com/v2/url?u=http-3A__ceur-2Dws.org_Vol-2D1700_paper-2D05.pdf&d=DwMGaQ&c=4ZIZThykDLcoWk-GVjSLmy8-1Cr1I4FWIvbLFebwKgY&r=SX6sxEGBIuiEtjQTAWz7jTpuOC0f5DcH79errOWxM8RN6gOsHdAxWfl9GTTkalJj&m=HNtxqmdvLjHJ6tDtUN0D71McOaqYoN3CtITnvzqcPmg&s=-ToimaJTj9bR0AuWNhNZ00_s2nfj0f0YTogpBj-wxdc&e=>
* Section 2 of this paper provides an introduction of different archiving strategies.
* Gray, Alasdair J. G. et al. “Dataset Descriptions: HCLS Community Profile.” Interest group note, W3C (May 2015) http://www.w3.org/TR/hcls-dataset (2015): n. pag. Print.<https://www.w3.org/TR/hcls-dataset/>
* A W3C Interest Group Note that, among other things, discusses requirements for dataset versioning.
* "The Data Catalog Vocabulary (DCAT) [DCAT<https://www.w3.org/TR/hcls-dataset/#DCAT>] is used to describe datasets in catalogs, but does not deal with the issue of dataset evolution and versioning."
He agrees that change sets are related to versioning in that a version can be described as a set of changes. Fully realized, this allows very granular tracking of dataset evolution. Makx point is important here: These changes are granular descriptions about the evolving content of a dataset, where DCAT so far does little to describe the data itself. If DCAT started to describe the content and structure of the data, this would be a considerable expansion of its scope.
The question if a set of changes constitute a new dataset or if a whole database is a dataset is complicated to me, because I understand instances of dcat:Dataset as conceptual descriptions of datasets, largely independent of the structure of the underlying data. In that sense, a database or a web service independent of the query can also be datasets. Limiting the data retrieved from it by some API call or SQL query could then create a new dataset fully contained in the first one.
cheers,
Martin
Am 22/06/17 um 11:00 schrieb Makx Dekkers:
Yes, I agree it is. Updating 'in place' is a case where the publisher decides that a change does not create a new Dataset.
I find Karen's suggestion to treat a 'database' as a 'dataset' interesting -- I have always thought of a database as closer to a dcat:Catalog.
Makx.
-----Original Message-----
From: Peter.Winstanley@gov.scot<mailto:Peter.Winstanley@gov.scot> [mailto:Peter.Winstanley@gov.scot]
Sent: 22 June 2017 10:52
To: mail@makxdekkers.com<mailto:mail@makxdekkers.com>; public-dxwg-wg@w3.org<mailto:public-dxwg-wg@w3.org>
Subject: RE: Question for DCAT "experts"
isn't a change set (like a diff) just a special case of versioning?
-----Original Message-----
From: Makx Dekkers [mailto:mail@makxdekkers.com]
Sent: 22 June 2017 09:47
To: public-dxwg-wg@w3.org<mailto:public-dxwg-wg@w3.org>
Subject: RE: Question for DCAT "experts"
As far as I remember from the initial work on DCAT, a Dataset is considered to be a kind of blob. Nothing is said about what goes on 'inside' a Dataset. The only thing you see on the outside is the modification date but you don't know what has changed inside.
Makx
-----Original Message-----
From: Karen Coyle [mailto:kcoyle@kcoyle.net]
Sent: 21 June 2017 17:31
To: public-dxwg-wg@w3.org<mailto:public-dxwg-wg@w3.org>
Subject: Question for DCAT "experts"
Many of you know DCAT quite well, and I'm new to it, so I'm taking the lazy way and directing this as a question to you.
I see in DCAT that there are properties that define frequency and update dates. The update date is
"Most recent date on which the dataset was changed, updated or modified."
The library world has a number of databases that are updated "in place".
For anyone receiving updates, the updates do not include the entire file, only those records added, changed, or deleted since some set time.
Is this covered by DCAT? If not, I will add a use case and we can discuss.
Thanks,
kc
--
Karen Coyle
kcoyle@kcoyle.net<mailto:kcoyle@kcoyle.net> http://kcoyle.net<https://urldefense.proofpoint.com/v2/url?u=http-3A__kcoyle.net&d=DwMGaQ&c=4ZIZThykDLcoWk-GVjSLmy8-1Cr1I4FWIvbLFebwKgY&r=SX6sxEGBIuiEtjQTAWz7jTpuOC0f5DcH79errOWxM8RN6gOsHdAxWfl9GTTkalJj&m=HNtxqmdvLjHJ6tDtUN0D71McOaqYoN3CtITnvzqcPmg&s=PEF3YuzzKpCupmPY7NjFyFh0zf3uaWiV484O7rPeRbs&e=>
m: 1-510-435-8234 (Signal)
skype: kcoylenet/+1-510-984-3600
______________________________________________________________________
This email has been scanned by the Symantec Email Security.cloud service.
For more information please visit http://www.symanteccloud.com<https://urldefense.proofpoint.com/v2/url?u=http-3A__www.symanteccloud.com&d=DwMGaQ&c=4ZIZThykDLcoWk-GVjSLmy8-1Cr1I4FWIvbLFebwKgY&r=SX6sxEGBIuiEtjQTAWz7jTpuOC0f5DcH79errOWxM8RN6gOsHdAxWfl9GTTkalJj&m=HNtxqmdvLjHJ6tDtUN0D71McOaqYoN3CtITnvzqcPmg&s=RS-ryPIAJX-DdeLAjoV6_iQv-7ExPAEAv3dX7hqb1Y0&e=> ______________________________________________________________________
*********************************** ******************************** This email has been received from an external party and has been swept for the presence of computer viruses.
********************************************************************
**********************************************************************
This e-mail (and any files or other attachments transmitted with it) is intended solely for the attention of the addressee(s). Unauthorised use, disclosure, storage, copying or distribution of any part of this e-mail is not permitted. If you are not the intended recipient please destroy the email, remove any copies from your system and inform the sender immediately by return.
Communications with the Scottish Government may be monitored or recorded in order to secure the effective operation of the system and for other lawful purposes. The views or opinions contained within this e-mail may not necessarily reflect those of the Scottish Government.
Tha am post-d seo (agus faidhle neo ceanglan còmhla ris) dhan neach neo luchd-ainmichte a-mhàin. Chan eil e ceadaichte a chleachdadh ann an dòigh sam bith, a’ toirt a-steach còraichean, foillseachadh neo sgaoileadh, gun chead. Ma ’s e is gun d’fhuair sibh seo le gun fhiosd’, bu choir cur às dhan phost-d agus lethbhreac sam bith air an t-siostam agaibh, leig fios chun neach a sgaoil am post-d gun dàil.
Dh’fhaodadh gum bi teachdaireachd sam bith bho Riaghaltas na h-Alba air a chlàradh neo air a sgrùdadh airson dearbhadh gu bheil an siostam ag obair gu h-èifeachdach neo airson adhbhar laghail eile. Dh’fhaodadh nach eil beachdan anns a’ phost-d seo co-ionann ri beachdan Riaghaltas na h-Alba.
**********************************************************************
--
Martin Brümmer
Linked Data Consultat
phone +49 341 26508028
martin.bruemmer@eccenca.com<mailto:martin.bruemmer@eccenca.com>
Postanschrift / Postal address:
eccenca GmbH | Hainstraße 8 | 04109 Leipzig | Germany
eccenca GmbH
Hainstraße 8 | 04109 Leipzig | Germany
Geschäftsführer / Board of Directors: Hans-Chr. Brockmann
Sitz und Registergericht / Domicile and Court of Registry: Leipzig
HRB-Nr. / Commercial Register No.: 29201
USt-ID / VAT registration No.: DE 289172708
Diese Mail kann vertrauliche Informationen enthalten. Wenn Sie nicht Adressat sind, sind Sie nicht zur Verwendung der in dieser Mail enthaltenen Informationen befugt. Bitte benachrichtigen Sie uns sofort über den irrtümlichen Empfang.
This e-mail may contain confidential information. If you are not the addressee you are not authorized to make use of the information contained in this e-mail. Please inform us immediately that you have received it by mistake.
______________________________________________________________________
This email has been scanned by the Symantec Email Security.cloud service.
For more information please visit http://www.symanteccloud.com<https://urldefense.proofpoint.com/v2/url?u=http-3A__www.symanteccloud.com&d=DwMGaQ&c=4ZIZThykDLcoWk-GVjSLmy8-1Cr1I4FWIvbLFebwKgY&r=SX6sxEGBIuiEtjQTAWz7jTpuOC0f5DcH79errOWxM8RN6gOsHdAxWfl9GTTkalJj&m=fRo50yJizVSUHfDi7E757jy8R7i7W6Y-hkkN2NtudUY&s=-b8B4WeCO4GlJStxswVYUKf3_1lhDWt7WKWzgvy1WAE&e=>
______________________________________________________________________
*********************************** ********************************
This email has been received from an external party and
has been swept for the presence of computer viruses.
********************************************************************
______________________________________________________________________
This email has been scanned by the Symantec Email Security.cloud service.
For more information please visit http://www.symanteccloud.com
______________________________________________________________________
*********************************** ********************************
This email has been received from an external party and
has been swept for the presence of computer viruses.
********************************************************************
______________________________________________________________________
This email has been scanned by the Symantec Email Security.cloud service.
For more information please visit http://www.symanteccloud.com
______________________________________________________________________
*********************************** ********************************
This email has been received from an external party and
has been swept for the presence of computer viruses.
********************************************************************
Attachments
- image/png attachment: image001.png

- image/jpeg attachment: Overview_DS_DSS_FC_MD.JPG
Received on Friday, 23 June 2017 08:45:16 UTC